windows-rtx-4060ti-8gb-moe-offload-bench-2026-05
收藏Hugging Face2026-05-07 更新2026-05-08 收录
下载链接:
https://huggingface.co/datasets/witcheer/windows-rtx-4060ti-8gb-moe-offload-bench-2026-05
下载链接
链接失效反馈官方服务:
资源简介:
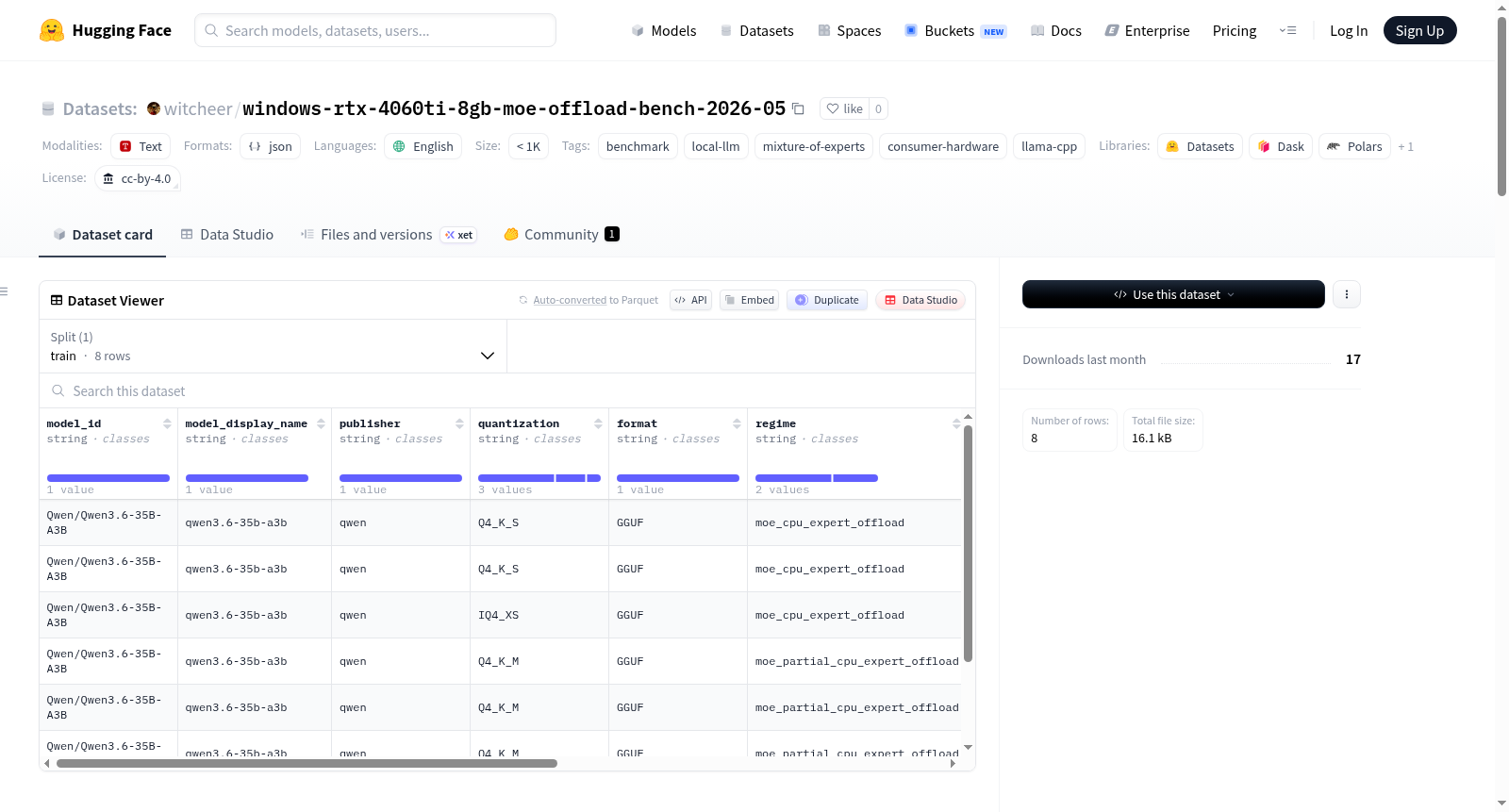
该数据集是一个针对消费级硬件上Mixture-of-Experts (MoE)模型卸载性能的基准测试数据集。数据集包含在Windows RTX 4060 Ti 8GB显卡和32GB DDR5内存的消费级配置上进行的两种卸载策略测试:完全卸载(所有专家层到CPU)和部分卸载(通过llama-server的`-ncmoe N`参数调节)。测试使用了Qwen3.6-35B-A3B模型,包含不同量化配置和上下文长度下的性能数据。数据集提供了详细的硬件规格、测试方法、性能结果和关键发现,特别揭示了8GB显存设备的性能边界和最优配置建议。适用于本地大语言模型部署和优化的研究人员和实践者。
创建时间:
2026-05-06
搜集汇总
数据集介绍
构建方式
本数据集系针对Windows平台下搭载RTX 4060 Ti 8GB显卡及32GB DDR5内存的消费级硬件,对Qwen3.6-35B-A3B混合专家模型进行专家卸载(Expert Offload)性能测试的系统性记录。测试涵盖两种卸载策略:其一为全量卸载(将全部专家层权重迁移至CPU),借助LM Studio引擎实施;其二为部分专家卸载,通过从源码编译的llama-server(llama.cpp b9049版本)执行`-ncmoe N`参数扫描,并跨不同上下文长度(16K至65K)及量化方案(Q4_K_S与IQ4_XS)采集数据。数据以JSONL格式存储于两个文件中,分别对应2026年5月6日与7日的测试批次,每份文件包含3至5次重复运行的结果。
特点
该数据集的核心价值在于精准刻画了8GB显存环境下混合专家模型的性能瓶颈与优化空间。实验揭示了一个尖锐而非渐进的VRAM临界点:当GPU总占用突破约7GB时,显存页错误通过PCIe总线引发瞬时吞吐量骤降约50%。令人瞩目的是,借助混合SSM与注意力机制,Qwen3.6模型仅在10/40层使用标准注意力,使得32K上下文相较于16K仅增加约170 MiB的KV缓存开销。最终,在`-ncmoe 30`结合32K上下文的配置下,系统实现了35.36 tok/sec的解码速度,较全量卸载方案提速4.8倍,展示了部分专家卸载策略在消费级硬件上的卓越潜力。
使用方法
研究者可直接加载`data/bench-2026-05-06.jsonl`与`data/bench-2026-05-07.jsonl`两个文件,获取全量卸载与部分卸载的详尽性能数据。数据集特别适用于评估MoE模型在显存受限环境下的实际推理表现,并为硬件特定调优提供参考基线。推荐的使用路径为:首先复现全量卸载的瓶颈情况,继而利用`-ncmoe N`参数在16K至65K上下文区间内进行扫描,以确定特定硬件(如8GB VRAM+32GB RAM)的最佳专家卸载层数。结合提供的硬件配置明细(RTX 4060 Ti、Ryzen 5 7600X、DDR5-6000),用户可在相似平台上验证结果,或通过调整`-ncmoe`与`-c`参数探索更广泛的性能边界。
背景与挑战
背景概述
该数据集由研究者witcheer于2026年5月创建,聚焦于在消费级硬件上运行混合专家(MoE)大语言模型的性能基准测试。研究机构或个人开发者旨在评估8GB显存的RTX 4060 Ti显卡与32GB系统内存组合下,Qwen3.6-35B-A3B模型专家卸载策略的实际效果。核心研究问题在于探索局部专家卸载相对于完全卸载的吞吐量提升,以及8GB显存的瓶颈边界。该数据集填补了消费级GPU运行大规模MoE模型优化策略的实证空白,对本地大模型部署领域具有重要参考价值,为硬件受限场景下的推理效率优化提供了可复现的量化依据。
当前挑战
数据集面临的核心领域挑战在于消费级8GB显存与32GB内存的硬件限制,导致大模型推理时专家权重频繁在CPU与GPU间迁移,产生PCIe页面错误,致使吞吐量陡降50%。构建过程中的挑战包括:在Windows与WSL2双环境下复现统一的llama-server编译流程,确保`-ncmoe`参数精确控制专家层数;通过多轮冷启动与不同上下文长度(16K至65K)的交叉测试,在7GB显存阈值附近捕捉性能悬崖,需排除KV缓存、量化格式等变量的干扰,最终定位到硬件特定的最优卸载配置(`-ncmoe 30`,上下文32K),验证了局部专家卸载比全量卸载快4.8倍的核心结论。
常用场景
经典使用场景
在消费级硬件上运行大规模混合专家模型时,本数据集为研究者提供了在8GB显存与32GB系统内存约束下的权威性能基准。其经典用途在于评估MoE专家卸载策略对推理吞吐量的影响,通过对比完全卸载与部分卸载两种机制,揭示显存瓶颈与带宽限制对模型实时性的关键作用。该数据集尤其适用于验证‘-ncmoe’参数在llama.cpp框架中的有效性,为资源受限环境下的MoE模型部署提供定量参考。
实际应用
在实际应用中,本数据集指导开发者为Qwen3.6等MoE模型在Radeon、GeForce等消费级GPU上选择最优卸载配置。例如,通过‘-ncmoe 30’参数将专家层部分保留于GPU,可实现35.36 tok/sec的生成速度,相比全量卸载提升4.8倍,适用于本地AI助手、离线文档分析等需要实时响应的场景。其还支持在Windows与WSL2环境中复现最佳实践,降低企业部署门槛。
衍生相关工作
基于该数据集的阈值发现,衍生出多项针对性研究工作:如自动化显存调度器设计,根据VRAM使用率动态调整‘-ncmoe’参数;或开发跨平台MoE运行时库,优化PCIe页错误处理以缓解性能悬崖。同时,其与同配置的密集模型基准数据集相结合,催生了混合架构比较研究,促使学术界重新审视MoE模型在资源受限条件下的效率优势。
以上内容由遇见数据集搜集并总结生成


