inesc-id/FalAR
收藏Hugging Face2026-03-31 更新2025-10-18 收录
下载链接:
https://hf-mirror.com/datasets/inesc-id/FalAR
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-4.0
dataset_info:
features:
- name: ID
dtype: string
- name: wav
dtype:
audio:
sampling_rate: 16000
- name: speaker_id
dtype: float64
- name: duration
dtype: float64
- name: wrd
dtype: string
- name: transcription
dtype: string
- name: id_lsmi
dtype: float64
- name: cer
dtype: float64
- name: date
dtype: string
- name: speaker_affiliation
dtype: string
- name: speaker_role
dtype: string
- name: action
dtype: string
- name: title
dtype: string
- name: gender
dtype: string
- name: age
dtype: float64
splits:
- name: test
num_bytes: 11825263275.24
num_examples: 16376
- name: dev
num_bytes: 5250037180
num_examples: 7337
- name: train_0
num_bytes: 35480250433
num_examples: 50000
- name: train_1
num_bytes: 35095495946
num_examples: 50000
- name: train_2
num_bytes: 35174566499
num_examples: 50000
- name: train_3
num_bytes: 35325984441
num_examples: 50000
- name: train_4
num_bytes: 35645431260.0
num_examples: 50000
- name: train_5
num_bytes: 35056367648.0
num_examples: 50000
- name: train_6
num_bytes: 35371961782.0
num_examples: 50000
- name: train_7
num_bytes: 35599714455.0
num_examples: 50000
- name: train_8
num_bytes: 35406657542.0
num_examples: 50000
- name: train_9
num_bytes: 35340130500.0
num_examples: 50000
- name: train_10
num_bytes: 36338130616.0
num_examples: 50000
- name: train_11
num_bytes: 34852591037.0
num_examples: 50000
- name: train_12
num_bytes: 35335378402.0
num_examples: 50000
- name: train_13
num_bytes: 35395245514.0
num_examples: 50000
- name: train_14
num_bytes: 35700329456.0
num_examples: 50000
- name: train_15
num_bytes: 13425332540.896
num_examples: 18834
download_size: 565520576837
dataset_size: 561618868527.136
configs:
- config_name: default
data_files:
- split: dev
path: data/dev-*
- split: test
path: data/test-*
- split: train_0
path: data/train_0-*
- split: train_1
path: data/train_1-*
- split: train_2
path: data/train_2-*
- split: train_3
path: data/train_3-*
- split: train_4
path: data/train_4-*
- split: train_5
path: data/train_5-*
- split: train_6
path: data/train_6-*
- split: train_7
path: data/train_7-*
- split: train_8
path: data/train_8-*
- split: train_9
path: data/train_9-*
- split: train_10
path: data/train_10-*
- split: train_11
path: data/train_11-*
- split: train_12
path: data/train_12-*
- split: train_13
path: data/train_13-*
- split: train_14
path: data/train_14-*
- split: train_15
path: data/train_15-*
---
# FalAR
[](https://huggingface.co/datasets/inesc-id/FalAR)
FalAR is a large-scale, speaker-annotated **European Portuguese** speech corpus built from recordings of parliamentary sessions of the Portuguese Parliament. The dataset contains aligned speech segments, reference transcripts, automatic transcripts, and speaker metadata.
This release is intended to support research in automatic speech recognition (ASR), speaker-aware speech processing, and related studies on parliamentary speech in European Portuguese.
## Highlights
- **European Portuguese** parliamentary speech
- **~4.9k hours** with speaker information
- **1.180 speakers** with associated metadata in the speaker-annotated portion
- Covers roughly **20 years** of parliamentary sessions
- Includes both a **reference transcript** and an **automatic transcription**
- Includes a per-utterance **character error rate (CER)** between the two transcripts
## Splits
- `dev`
- `test`
- `train_0` to `train_15`
## Example usage
### Load the dataset
```python
from datasets import load_dataset
# Load all available splits
falAR = load_dataset("inesc-id/FalAR")
# Example: inspect one row from the dev split
print(falAR["dev"][0])
```
## Recommended field usage
- Use `wrd` as the main target text for supervised ASR training when available.
- Use `transcription` as the automatically generated transcript.
- Use `cer` to filter for higher-confidence alignments.
- Use `speaker_id` and metadata fields for speaker-aware analysis.
## 📣 Citation
If you use this dataset, please cite the FalAR paper:
```bibtex
@inproceedings{teixeira2026falar,
title = {FalAR: A Large-scale Speaker-Annotated European Portuguese Speech Corpus of Parliamentary Sessions},
author = {Teixeira, Francisco and Carvalho, Carlos and Julião, Mariana and Botelho, Catarina and Solera-Ureña, Rub{\'e}n and Paulo, S{\'e}rgio and Rolland, Thomas and Peters, Ben and Trancoso, Isabel and Abad, Alberto},
booktitle = {Proceedings of the International Conference on Language Resources and Evaluation (LREC)},
year = {2026}
}
```
## License
This dataset is listed on Hugging Face under **CC-BY-4.0**.
提供机构:
inesc-id
搜集汇总
数据集介绍
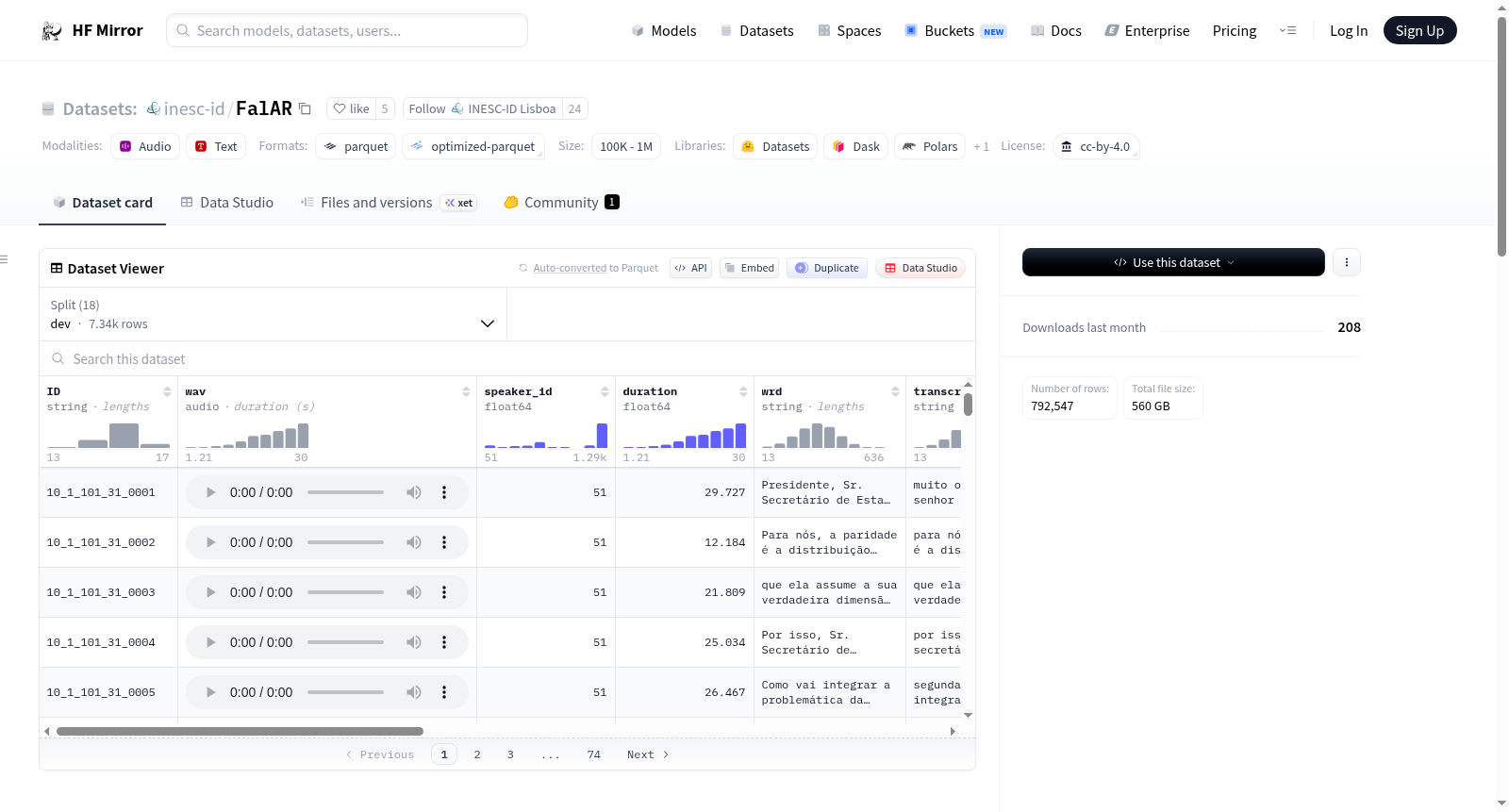
构建方式
在语音识别与语料库构建领域,大规模、高质量的标注数据是推动技术发展的基石。FalAR数据集的构建源于对欧洲葡萄牙语议会演讲的系统性采集与处理,其核心素材取自葡萄牙议会约二十年的会议录音。通过自动化流程,原始音频被分割为独立的话语片段,并与参考文本及自动生成的转录文本进行精准对齐。构建过程中,每个话语片段均关联了说话人身份标识及丰富的元数据,如所属机构、角色、行为等,从而形成了一个兼具语音信号、文本转录与说话人信息的综合性语料库。
使用方法
在语音技术研究中,FalAR数据集为多种任务提供了结构化支持。对于自动语音识别模型的训练与评估,研究者可将`wrd`字段作为监督学习的参考文本,或利用`transcription`字段进行半监督学习及错误分析。`cer`字段可用于筛选高质量对齐的数据子集,以提升模型训练效率。在说话人相关的分析中,`speaker_id`及关联的元数据字段支持说话人识别、语音特征分析与群体语音模式挖掘。数据集已按开发集、测试集及多个训练子集划分,便于进行标准的模型训练、验证与测试流程。
背景与挑战
背景概述
在语音识别与计算语言学领域,大规模、高质量语音语料库的构建对于推动特定语言及领域的研究至关重要。FalAR数据集由INESC-ID等研究机构于2026年创建,旨在填补欧洲葡萄牙语议会演讲数据的空白。该数据集采集自葡萄牙议会约二十年的会议录音,涵盖近4900小时的语音数据,并包含1180位发言者的详细元数据。其核心研究问题聚焦于提升欧洲葡萄牙语的自动语音识别性能,并支持说话人感知的语音处理研究,为语言学、政治学及语音技术跨学科探索提供了宝贵资源。
当前挑战
FalAR数据集致力于解决欧洲葡萄牙语议会场景下自动语音识别的领域挑战,包括处理专业政治术语、多样化的说话人风格以及复杂的声学环境。在构建过程中,面临诸多技术难题:大规模语音与文本的对齐需保证时间戳精确性;自动转录与参考文本的字符错误率计算要求高效的算法支持;同时,整合多维度说话人元数据如所属机构、角色及人口统计信息,需克服数据标注的一致性与完整性难题。这些挑战共同塑造了数据集的复杂性与研究价值。
常用场景
经典使用场景
在语音技术研究领域,FalAR数据集作为欧洲葡萄牙语议会语音的大规模语料库,其经典使用场景聚焦于自动语音识别模型的训练与评估。该数据集提供了对齐的语音片段、参考转录文本及自动转录结果,研究者可依据wrd字段作为监督学习的目标文本,构建端到端的ASR系统。通过利用其丰富的说话人元数据,如speaker_id和speaker_role,该数据集进一步支持说话人自适应或说话人识别等进阶任务,为欧洲葡萄牙语语音处理提供了标准化基准。
解决学术问题
FalAR数据集有效解决了欧洲葡萄牙语语音资源相对匮乏的学术研究问题,为低资源语言语音识别提供了高质量、大规模的训练数据。其包含的说话人注释信息及长达二十年的议会会话覆盖,使得研究者能够深入探究说话人变异、领域适应及历史语言变化等课题。此外,数据集提供的字符错误率指标为语音对齐质量评估与数据清洗提供了量化依据,显著提升了语音识别模型在复杂真实场景中的鲁棒性与准确性。
实际应用
在实际应用层面,FalAR数据集为欧洲葡萄牙语地区的语音技术开发奠定了坚实基础。基于该数据集训练的自动语音识别系统可广泛应用于议会会议记录自动化、媒体内容字幕生成、司法语音转录及无障碍通信服务等领域。其丰富的说话人元数据,如所属机构与角色,进一步支持了说话人分析、舆情监测及政治话语研究等跨学科应用,为政府、媒体与研究机构提供了高效的数据驱动解决方案。
数据集最近研究
最新研究方向
在语音技术领域,欧洲葡萄牙语资源相对稀缺,FalAR数据集的发布为相关研究注入了新的活力。该数据集以其大规模、带说话人标注的议会语音特性,正推动自动语音识别模型在复杂声学环境下的鲁棒性优化,特别是针对多说话人重叠、领域特定术语及口音变异的处理。前沿探索聚焦于利用说话人元数据开发个性化语音处理系统,结合字符错误率指标提升转录对齐质量,以支持议会辩论分析、多模态政治计算等跨学科应用。这些进展不仅丰富了低资源语言的技术生态,也为民主进程的透明化研究提供了数据基石。
以上内容由遇见数据集搜集并总结生成


