有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
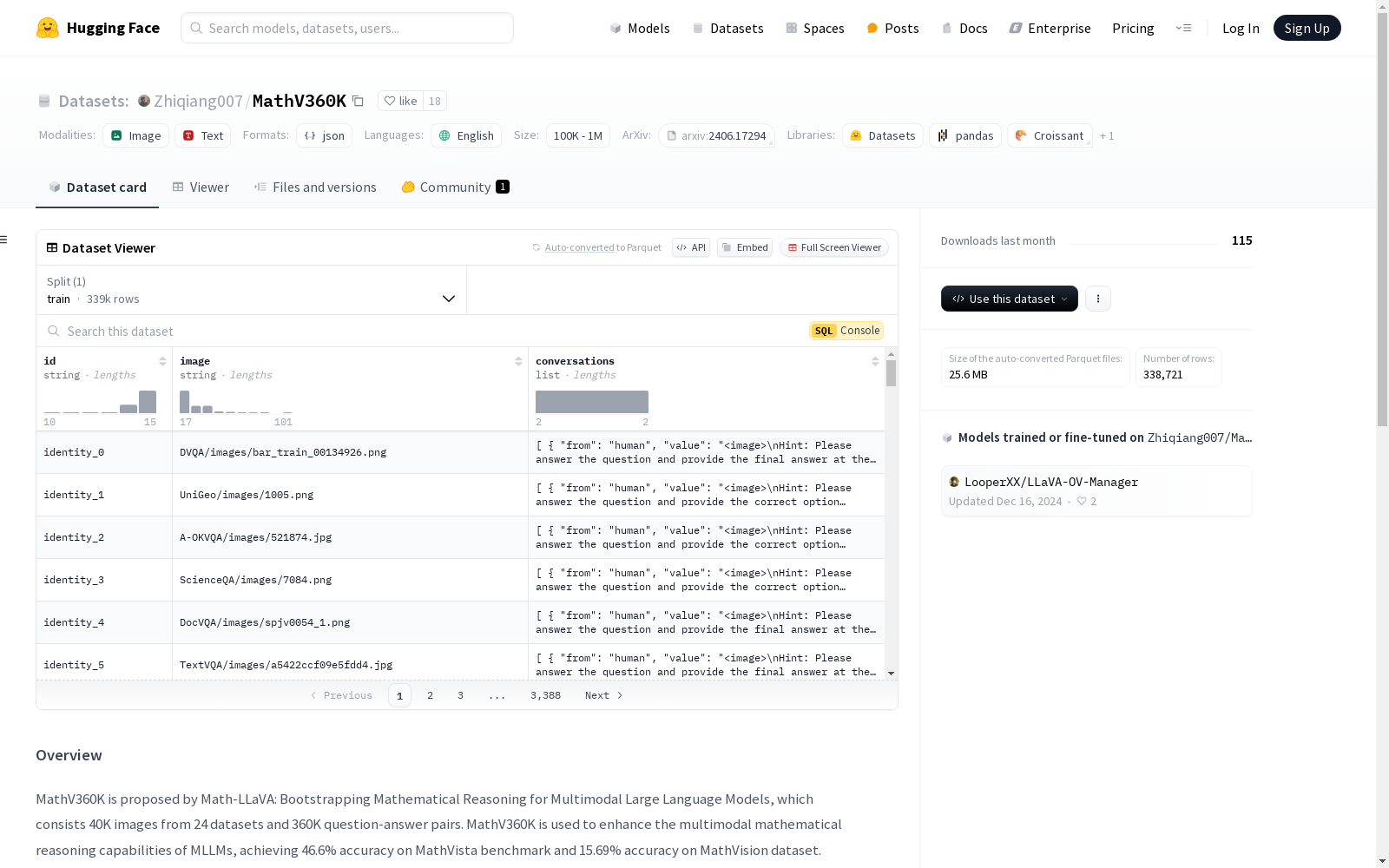
MathV360K 是由 Math-LLaVA 提出的,用于增强多模态大型语言模型的数学推理能力。该数据集包含来自 24 个数据集的 40K 张图像和 360K 个问题-答案对。MathV360K 在 MathVista 基准测试中达到了 46.6% 的准确率,在 MathVision 数据集上达到了 15.69% 的准确率。
数据集大小介于 100K 到 1M 之间。
Breast Ultrasound Images (BUSI)
小型(约500×500像素)超声图像,适用于良性和恶性病变的分类和分割任务。
github 收录
TM-Senti
TM-Senti是由伦敦玛丽女王大学开发的一个大规模、远距离监督的Twitter情感数据集,包含超过1.84亿条推文,覆盖了超过七年的时间跨度。该数据集基于互联网档案馆的公开推文存档,可以完全重新构建,包括推文元数据且无缺失推文。数据集内容丰富,涵盖多种语言,主要用于情感分析和文本分类等任务。创建过程中,研究团队精心筛选了表情符号和表情,确保数据集的质量和多样性。该数据集的应用领域广泛,旨在解决社交媒体情感表达的长期变化问题,特别是在表情符号和表情使用上的趋势分析。
arXiv 收录
LIDC-IDRI
LIDC-IDRI 数据集包含来自四位经验丰富的胸部放射科医师的病变注释。 LIDC-IDRI 包含来自 1010 名肺部患者的 1018 份低剂量肺部 CT。
OpenDataLab 收录
DALY
DALY数据集包含了全球疾病负担研究(Global Burden of Disease Study)中的伤残调整生命年(Disability-Adjusted Life Years, DALYs)数据。该数据集提供了不同国家和地区在不同年份的DALYs指标,用于衡量因疾病、伤害和早逝导致的健康损失。
ghdx.healthdata.org 收录
GME Data
关于2021年GameStop股票活动的数据,包括每日合并的GME短期成交量数据、每日失败交付数据、可借股数、期权链数据以及不同时间框架的开盘/最高/最低/收盘/成交量条形图。
github 收录