HorizonWeaver Editing Dataset
收藏arXiv2026-04-07 更新2026-04-07 收录
下载链接:
https://msoroco.github.io/horizonweaver/
下载链接
链接失效反馈官方服务:
资源简介:
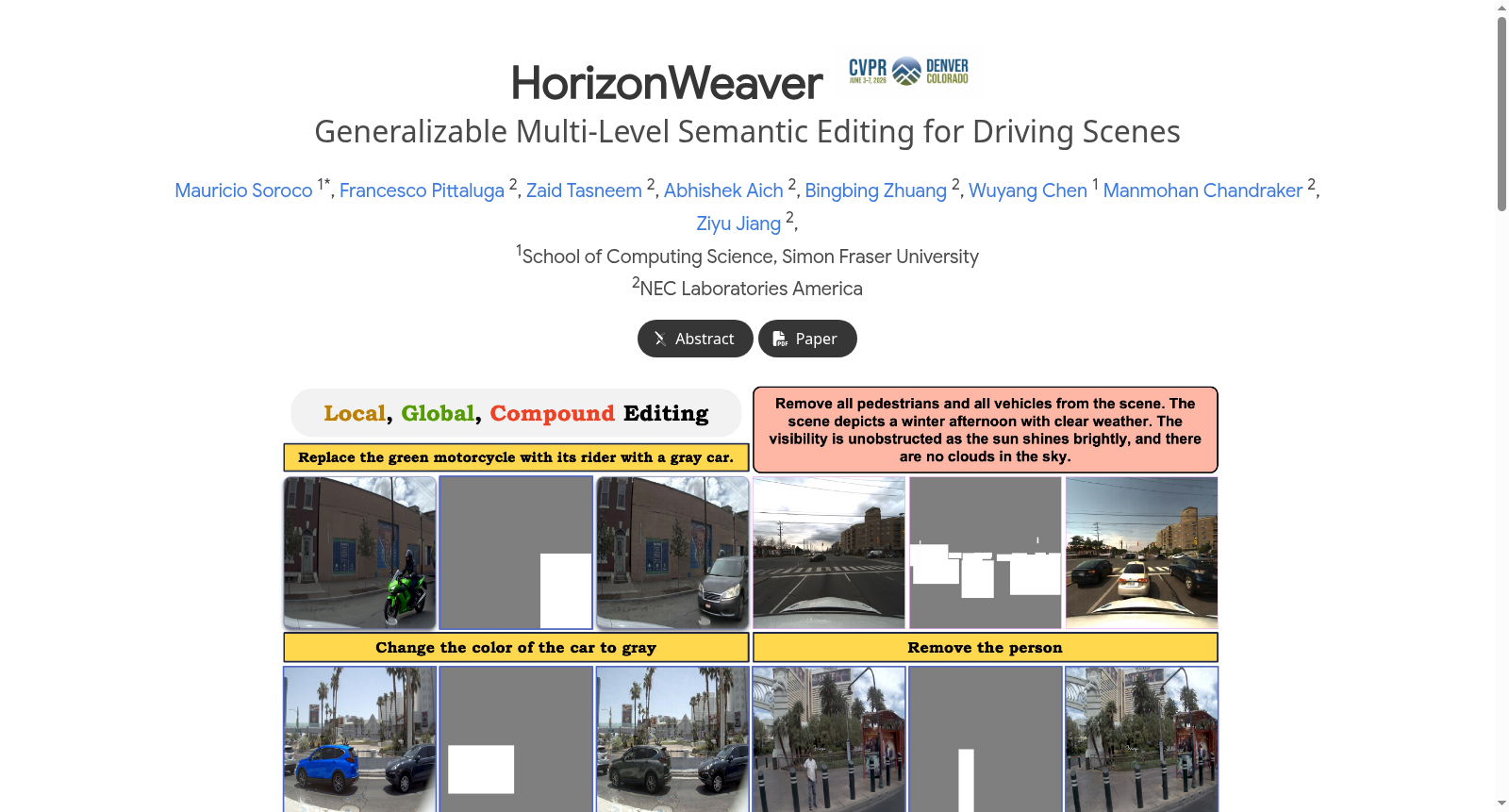
HorizonWeaver数据集由NEC美国实验室与西蒙弗雷泽大学联合构建,包含25.5万张驾驶场景图像,覆盖天气变化、交通流调整等13类编辑任务。该数据集创新性地融合了Boreas、nuScenes和Argoverse2的实景与合成数据,通过自动化配对生成和VLM验证流程确保数据质量,支持多粒度语义编辑研究。其核心价值在于解决自动驾驶领域密集场景下的内容保持与指令对齐难题,显著提升BEV分割等下游任务性能33%。
The HorizonWeaver dataset was jointly constructed by NEC Laboratories America and Simon Fraser University. It comprises 255,000 driving scene images covering 13 types of editing tasks such as weather variation and traffic flow adjustment. This dataset innovatively integrates real and synthetic data from Boreas, nuScenes, and Argoverse2, ensures data quality via automated pairing generation and VLM-based validation workflows, and supports multi-granularity semantic editing research. Its core value lies in resolving the challenges of content preservation and instruction alignment in dense autonomous driving scenarios, and it significantly boosts the performance of downstream tasks such as BEV segmentation by 33%.
提供机构:
西蒙弗雷泽大学; NEC美国实验室
创建时间:
2026-04-07
搜集汇总
数据集介绍
构建方式
在自动驾驶领域,构建能够支持多粒度语义编辑的数据集面临严峻挑战。HorizonWeaver编辑数据集通过创新的数据生成流程,整合了真实与合成驾驶场景。该数据集从Boreas、nuScenes和Argoverse2等权威自动驾驶数据源中提取图像,采用姿态对齐技术构建真实世界图像对,确保视角一致性。同时,通过结合视觉语言模型和图像编辑模型,生成涵盖13个编辑类别的大规模伪配对数据。整个构建过程包含自动化的图像描述、指令生成和质量验证流程,最终形成了包含25.5万张图像的高质量编辑数据集。
特点
该数据集的核心特征体现在其对自动驾驶场景编辑需求的深度适配。数据集支持从局部对象到全局场景的多层次编辑粒度,能够同时处理车辆、行人等密集对象的精细操作与环境天气、光照等全局属性的整体调整。通过引入LangMasks这一像素级语义掩码机制,数据集实现了语言指令与空间区域的精确绑定,为模型提供了丰富的语义指导。此外,数据集覆盖了广泛的地理环境和气候条件,有效缓解了领域偏移问题,增强了编辑模型在未见场景中的泛化能力。
使用方法
HorizonWeaver数据集为训练和评估指令驱动的驾驶场景编辑模型提供了标准化基准。研究人员可利用其提供的图像对、编辑指令和LangMasks,训练模型实现内容保持与指令对齐的编辑任务。数据集支持监督训练、无监督训练以及混合训练策略,其配套的训练目标函数(如循环一致性和CLIP对齐损失)可直接集成到模型优化过程中。在评估阶段,数据集支持通过L1、CLIP相似度等量化指标以及用户偏好研究,全面衡量编辑模型在内容保持、指令跟随和视觉真实性方面的性能。
背景与挑战
背景概述
HorizonWeaver Editing Dataset 诞生于自动驾驶领域对高保真、可扩展场景编辑的迫切需求。该数据集由 Simon Fraser University 与 NEC Labs America 的研究团队于2026年联合构建,旨在解决传统图像编辑方法在密集、安全关键的驾驶场景中面临的语义控制不足与泛化能力薄弱等核心问题。通过整合 Boreas、nuScenes 与 Argoverse2 等多源自动驾驶数据集,构建了包含25.5万张图像、覆盖13类编辑任务的配对数据集,为驾驶场景的多粒度语义编辑提供了标准化基准,显著推动了自动驾驶仿真测试与感知系统评估的技术发展。
当前挑战
该数据集主要应对两大挑战:在领域问题层面,需解决驾驶场景中多粒度编辑的复杂性,即如何在保持道路结构等全局要素稳定的同时,精准操控车辆、行人等局部实体,并确保编辑结果符合真实物理约束与安全要求;在构建过程层面,面临配对数据稀缺的难题,研究者通过姿态对齐算法从多季节驾驶日志中提取真实图像对,并设计基于视觉语言模型的自动标注流程生成伪配对数据,同时引入 LangMasks 机制将语义指令嵌入像素级掩码,以平衡编辑精度与内容保留之间的冲突。
常用场景
经典使用场景
在自动驾驶领域,HorizonWeaver Editing Dataset 最经典的使用场景是作为指令引导的图像编辑模型的训练与评估基准。该数据集通过整合Boreas、nuScenes和Argoverse2等真实与合成驾驶场景数据,构建了包含25.5万张图像、覆盖13个编辑类别的配对数据集。其核心价值在于支持多粒度编辑任务,包括局部对象级别的精确修改(如车辆插入、移除、替换)和全局场景级别的整体变换(如天气、光照、季节的调整),同时能够处理密集交通环境下的复合编辑需求,为模型在复杂驾驶场景中的语义理解和编辑能力提供了标准化测试平台。
衍生相关工作
基于HorizonWeaver数据集衍生的经典工作主要集中在多模态驾驶场景生成与编辑架构的创新。例如,LangMasks的设计启发了后续研究将语义嵌入与空间掩码结合,实现更精细的指令控制;其无监督训练目标(如循环一致性损失与CLIP对齐损失)被扩展用于其他跨域编辑任务,提升模型在未配对数据上的泛化能力。同时,该数据集推动了一系列驾驶专用编辑模型的比较研究,如与Qwen-Image、UltraEdit、BAGEL等通用编辑器的性能对比,凸显了驾驶场景密集性与安全要求对编辑技术的特殊约束。这些工作共同促进了指令引导编辑技术在自动驾驶仿真、数据合成与系统测试中的标准化与实用化进程。
数据集最近研究
最新研究方向
在自动驾驶领域,确保系统安全需依赖大规模、可控且真实的驾驶场景生成,以弥补真实世界测试的局限性。HorizonWeaver编辑数据集针对这一需求,聚焦于驾驶场景的多粒度语义编辑前沿研究。该数据集通过整合Boreas、nuScenes和Argoverse2等多源真实与合成数据,构建了涵盖13个编辑类别、25.5万张图像的大规模配对数据集,旨在解决密集驾驶场景中对象级与场景级编辑的协同挑战。其核心创新在于引入LangMasks机制,将语言指令嵌入像素级掩码,实现精细化的语言引导编辑,同时结合内容保持与指令对齐的联合损失函数,确保场景一致性与编辑忠实度。这一研究方向不仅提升了驾驶场景编辑的逼真度与可控性,还通过增强鸟瞰图分割等下游任务的性能,为自动驾驶系统的安全评估与泛化能力提供了关键数据支撑。相关热点事件包括生成式模型在自动驾驶仿真中的广泛应用,以及多模态大语言模型在场景理解与编辑中的深度融合,推动了驾驶场景数据合成向更高语义精度与跨域泛化方向发展。
相关研究论文
- 1HorizonWeaver: Generalizable Multi-Level Semantic Editing for Driving Scenes西蒙弗雷泽大学; NEC美国实验室 · 2026年
以上内容由遇见数据集搜集并总结生成


