olympusmons/librispeech_asr_test_clean_word_timestamp
收藏Hugging Face2024-03-26 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/olympusmons/librispeech_asr_test_clean_word_timestamp
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
dataset_info:
features:
- name: text
dtype: string
- name: words
list:
- name: end
dtype: int64
- name: start
dtype: int64
- name: text
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
splits:
- name: train
num_bytes: 354796679.02
num_examples: 2620
download_size: 351020954
dataset_size: 354796679.02
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
task_categories:
- automatic-speech-recognition
language:
- en
tags:
- asr
- librispeech
- timestamp
- librispeech_asr
- automatic_speech_recognition
size_categories:
- 1K<n<10K
---
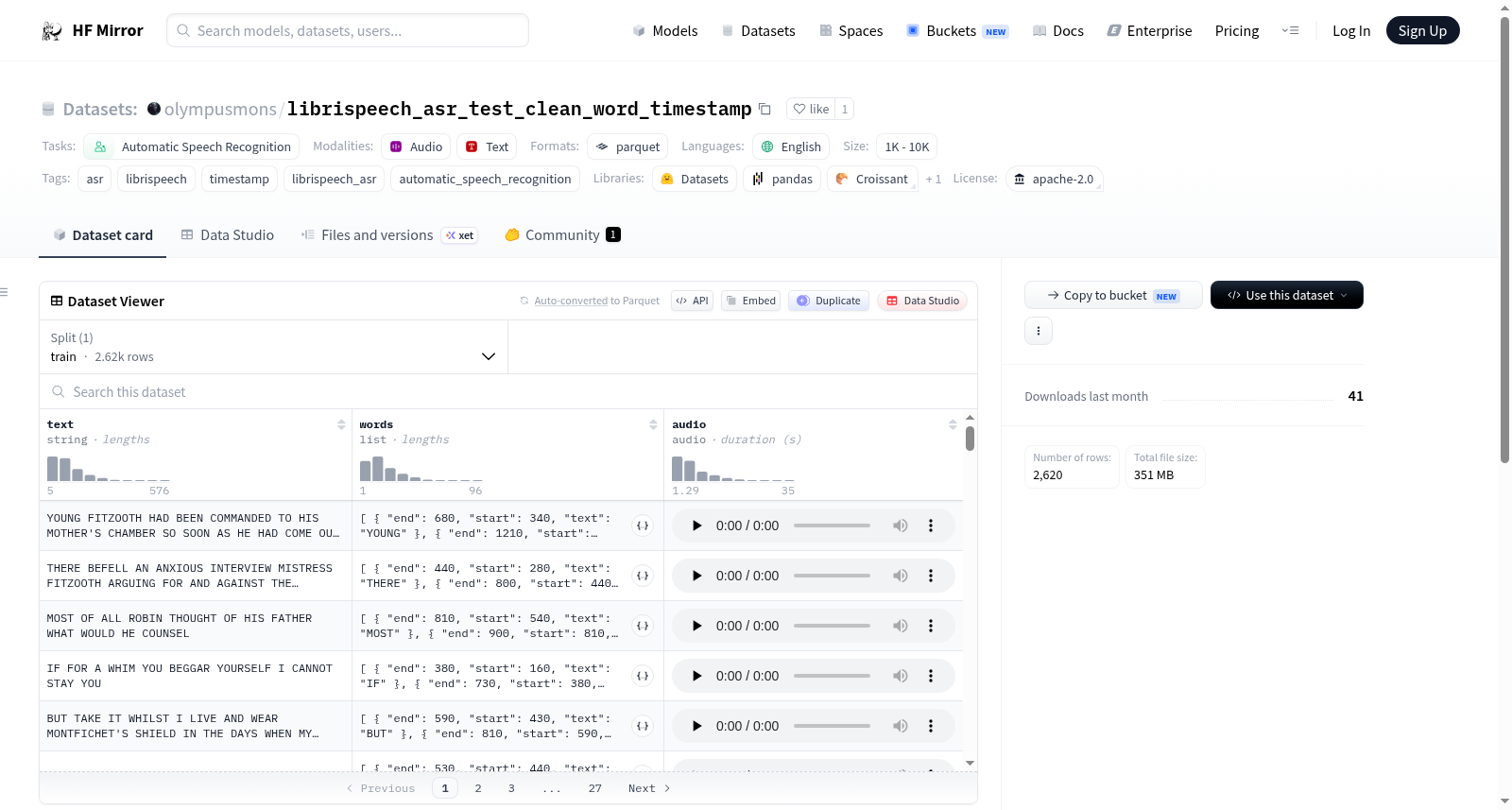
# Word-level timestamp annotated Librispeech ASR test set
This dataset contains word-level timestamp information for the Librispeech ASR test (clean) dataset.
It contains 2620 short files that have been force-aligned with its text to get reasonably accurate word-level timestamp information.
Suitable for use in timestamp benchmarking of ASR models or audio dataset preprocessing.
To request access to more datasets like this, please fill out this form: https://forms.gle/n6cwAfYD9sUTZURY9.
## Usage
```
from datasets import load_dataset
dataset = load_dataset("olympusmons/librispeech_asr_test_clean_word_timestamp")
print(dataset)
```
提供机构:
olympusmons
原始信息汇总
数据集概述
基本信息
- 许可证: Apache 2.0
- 语言: 英语
- 标签: asr, librispeech, timestamp, librispeech_asr, automatic_speech_recognition
- 大小分类: 1K<n<10K
数据集详情
- 特征:
text: 字符串类型words: 列表类型,包含以下子特征:end: 整数类型 (int64)start: 整数类型 (int64)text: 字符串类型
audio: 音频类型,采样率为16000
- 分割:
train: 包含2620个样本,数据大小为354796679.02字节
- 配置:
default: 包含训练数据文件路径data/train-*
任务类别
- 自动语音识别 (automatic-speech-recognition)
描述
该数据集包含Librispeech ASR测试(clean)数据集的单词级时间戳信息。它包含2620个短文件,这些文件已与其文本进行强制对齐,以获得合理准确的单词级时间戳信息。适用于ASR模型的时间戳基准测试或音频数据集预处理。
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是Librispeech ASR测试(clean)集的单词级时间戳版本,包含2620个短音频文件及其文本,通过强制对齐技术生成了精确的单词时间戳信息。它专为自动语音识别(ASR)模型的时间戳基准测试和音频数据预处理设计,采用parquet格式,语言为英语,规模适中,适用于研究和开发场景。
以上内容由遇见数据集搜集并总结生成


