cw1521/ember2018-malware
收藏Hugging Face2023-07-12 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/cw1521/ember2018-malware
下载链接
链接失效反馈官方服务:
资源简介:
---
task_categories:
- text-classification
pretty_name: EMBER
size_categories:
- 1M<n<10M
tags:
- malware
- virus
---
# EMBER 2018 Malware Analysis Dataset<br>
This dataset contains 1 million records of metadata and vectorized features for malware and benign software.<br>
Visit https://github.com/elastic/ember for more information on the dataset.<br>
## Usage <br>
dataset = load_dataset("cw1521/ember2018-malware", field="data")
<br><br>
x - vectorized features <br>
y - label (0 for benign and 1 for malware)
任务类别:
- 文本分类(text-classification)
展示名称:EMBER
数据量范围:
- 100万<n<1000万
标签:
- 恶意软件(malware)
- 病毒(virus)
# EMBER 2018 恶意软件分析数据集
本数据集包含100万条恶意软件与良性软件的元数据及向量化特征记录。
如需了解该数据集的更多详情,请访问:https://github.com/elastic/ember。
## 使用方法
dataset = load_dataset("cw1521/ember2018-malware", field="data")
x:向量化特征
y:标签(0代表良性软件,1代表恶意软件)
提供机构:
cw1521
原始信息汇总
EMBER 2018 Malware Analysis Dataset
概述
该数据集包含100万条恶意软件和良性软件的元数据和向量化特征记录。
任务类别
- 文本分类
大小类别
- 1M<n<10M
标签
- 恶意软件
- 病毒
使用方法
python dataset = load_dataset("cw1521/ember2018-malware", field="data")
x- 向量化特征y- 标签(0表示良性,1表示恶意软件)
搜集汇总
数据集介绍
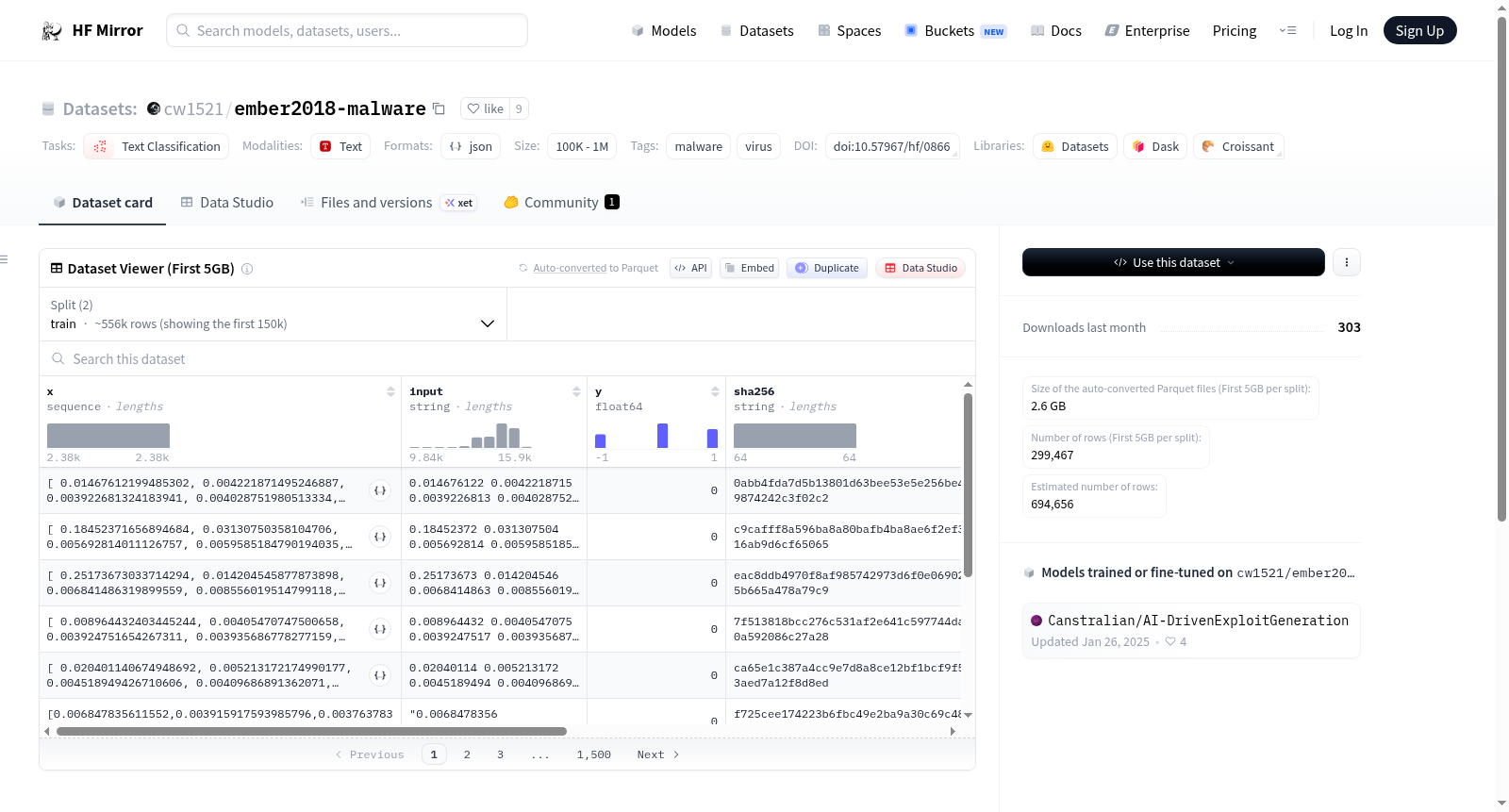
构建方式
在恶意软件检测领域,数据集的构建需兼顾规模与代表性。EMBER 2018数据集通过收集一百万条恶意软件与良性软件的元数据及向量化特征记录而成,其构建过程依托于Elastic公司的开源项目,确保了数据来源的可靠性与标准化处理。每条记录均经过特征提取与向量化转换,形成结构化数据,为后续分析奠定基础。
特点
该数据集的核心特点在于其大规模与高维度特征表示,涵盖百万级别样本,适用于训练复杂的机器学习模型。特征向量经过精心设计,能够有效捕捉软件行为的细微差异,同时标签清晰区分恶意与良性样本,为分类任务提供坚实基础。数据集的公开性与可重复性进一步促进了恶意软件研究社区的协作与创新。
使用方法
使用该数据集时,可通过HuggingFace平台便捷加载,具体操作为调用load_dataset函数并指定相应字段。输入数据为字符串格式的向量化特征,输出标签以0和1分别标识良性软件与恶意软件,便于直接应用于文本分类任务。研究人员可在此基础上进行模型训练、评估与优化,推动恶意软件检测技术的进步。
背景与挑战
背景概述
在网络安全领域,恶意软件检测一直是核心研究议题,随着恶意代码的复杂化和变种增多,传统基于签名的检测方法逐渐失效。EMBER 2018数据集由Elastic公司于2018年创建,旨在通过机器学习方法提升恶意软件识别的准确性和效率。该数据集收录了100万条恶意软件与良性软件的元数据及向量化特征,为研究人员提供了大规模、标准化的基准数据,推动了基于静态特征的恶意软件检测技术的发展,并在安全社区中产生了广泛影响,成为该领域的重要资源。
当前挑战
EMBER 2018数据集面临的挑战主要体现在两个方面:在领域问题层面,恶意软件检测需应对代码混淆、多态性及零日攻击等复杂威胁,这要求模型具备强大的泛化能力和实时分析性能;在构建过程中,数据收集涉及大量样本的合法获取与标注,需平衡隐私合规性与数据完整性,同时特征向量化过程需克服高维稀疏性和噪声干扰,确保特征能有效区分恶意与良性软件,这些挑战共同制约了检测系统的实际部署效果。
常用场景
经典使用场景
在恶意软件检测领域,EMBER 2018数据集凭借其百万级规模的元数据与向量化特征,为机器学习模型提供了丰富的训练基础。该数据集常用于构建和评估恶意软件分类器,通过提取软件行为的静态特征,如API调用序列、文件结构信息等,研究人员能够训练模型以区分恶意与良性软件。这种基于特征向量的方法,使得模型能够高效处理大规模样本,提升检测的准确性与泛化能力,成为恶意软件分析中的经典基准。
衍生相关工作
围绕EMBER 2018数据集,衍生了一系列经典研究工作,包括基于深度学习的恶意软件检测模型如卷积神经网络与循环神经网络的融合应用。这些工作进一步优化了特征提取与分类算法,推动了恶意软件分析技术的演进。此外,该数据集还促进了对抗性攻击防御、可解释性AI在安全领域的探索,为后续更复杂的数据集构建与方法创新提供了重要参考。
数据集最近研究
最新研究方向
在恶意软件检测领域,EMBER 2018数据集凭借其百万级规模的元数据和向量化特征,已成为推动前沿研究的关键资源。当前研究聚焦于利用深度学习模型,如Transformer架构,对向量化特征进行端到端分析,以提升恶意软件分类的准确性和泛化能力。热点方向包括结合图神经网络处理软件行为依赖关系,以及探索对抗性攻击下的鲁棒性防御策略。这些进展不仅强化了网络安全防护体系,还为自动化威胁情报分析提供了数据驱动的新范式,具有重要的实际应用价值。
以上内容由遇见数据集搜集并总结生成


