有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
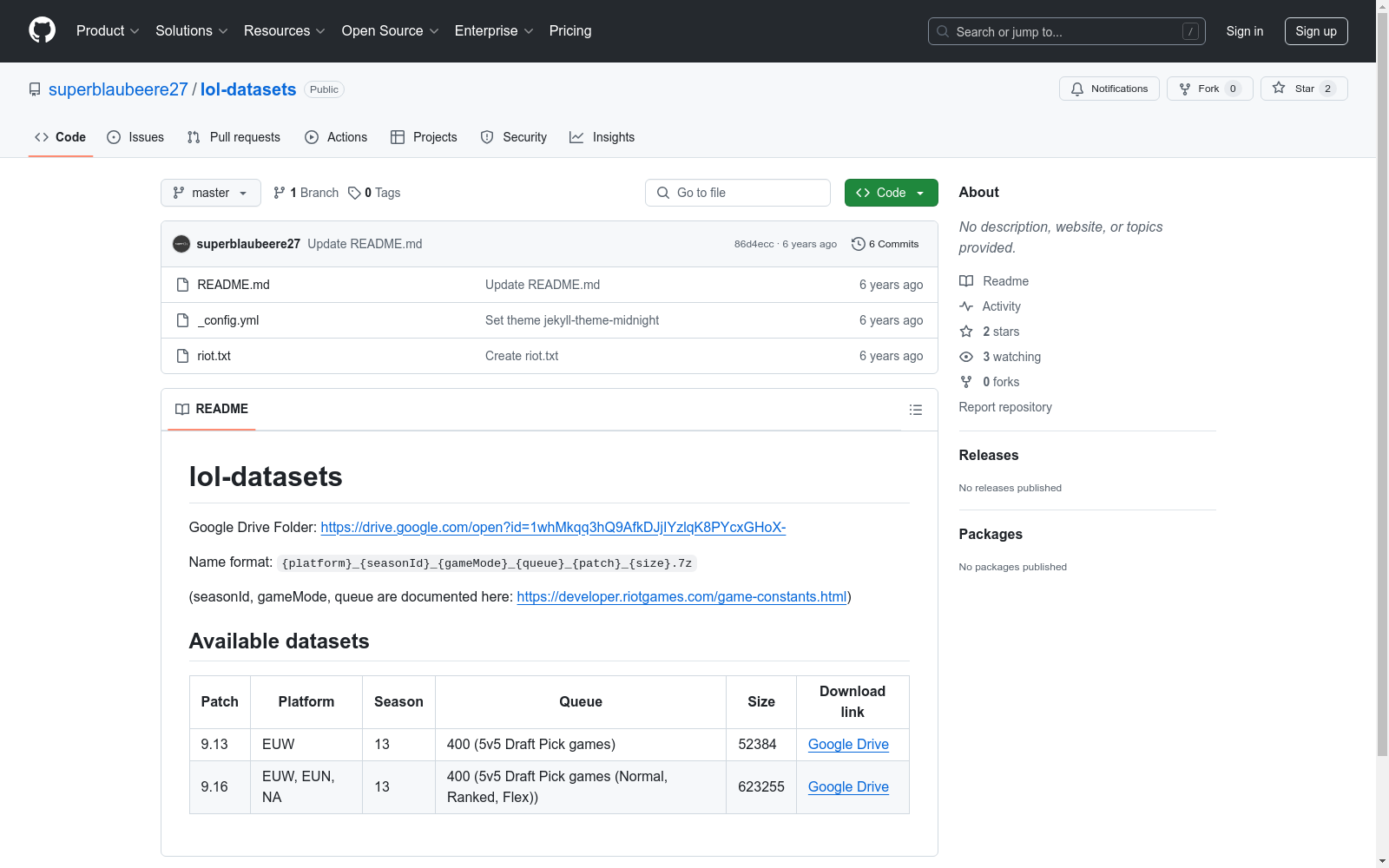
{platform}_{seasonId}_{gameMode}_{queue}_{patch}_{size}.7z| Patch | Platform | Season | Queue | Size | Download link |
|---|---|---|---|---|---|
| 9.13 | EUW | 13 | 400 (5v5 Draft Pick games) | 52384 | Google Drive |
| 9.16 | EUW, EUN, NA | 13 | 400 (5v5 Draft Pick games (Normal, Ranked, Flex)) | 623255 | Google Drive |
LFW
人脸数据集;LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。 URL: http://vis-www.cs.umass.edu/lfw/index.html#download
AI_Studio 收录
Plant-Diseases
Dataset for Plant Diseases containg variours Plant Disease
kaggle 收录
猫狗图像数据集
该数据集包含猫和狗的图像,每类各12500张。训练集和测试集分别包含10000张和2500张图像,用于模型的训练和评估。
github 收录
中国空气质量数据集(2014-2020年)
数据集中的空气质量数据类型包括PM2.5, PM10, SO2, NO2, O3, CO, AQI,包含了2014-2020年全国360个城市的逐日空气质量监测数据。监测数据来自中国环境监测总站的全国城市空气质量实时发布平台,每日更新。数据集的原始文件为CSV的文本记录,通过空间化处理生产出Shape格式的空间数据。数据集包括CSV格式和Shape格式两数数据格式。
国家地球系统科学数据中心 收录
MedChain
MedChain是由香港城市大学、香港中文大学、深圳大学、阳明交通大学和台北荣民总医院联合创建的临床决策数据集,包含12,163个临床案例,涵盖19个医学专科和156个子类别。数据集通过五个关键阶段模拟临床工作流程,强调个性化、互动性和顺序性。数据来源于中国医疗网站“iiYi”,经过专业医生验证和去识别化处理,确保数据质量和患者隐私。MedChain旨在评估大型语言模型在真实临床场景中的诊断能力,解决现有基准在个性化医疗、互动咨询和顺序决策方面的不足。
arXiv 收录