EpistemeAI__Fireball-Meta-Llama-3.2-8B-Instruct-agent-003-128k-code-DPO
收藏Hugging Face2025-01-08 更新2025-01-09 收录
下载链接:
https://huggingface.co/datasets/math-extraction-comp/EpistemeAI__Fireball-Meta-Llama-3.2-8B-Instruct-agent-003-128k-code-DPO
下载链接
链接失效反馈官方服务:
资源简介:
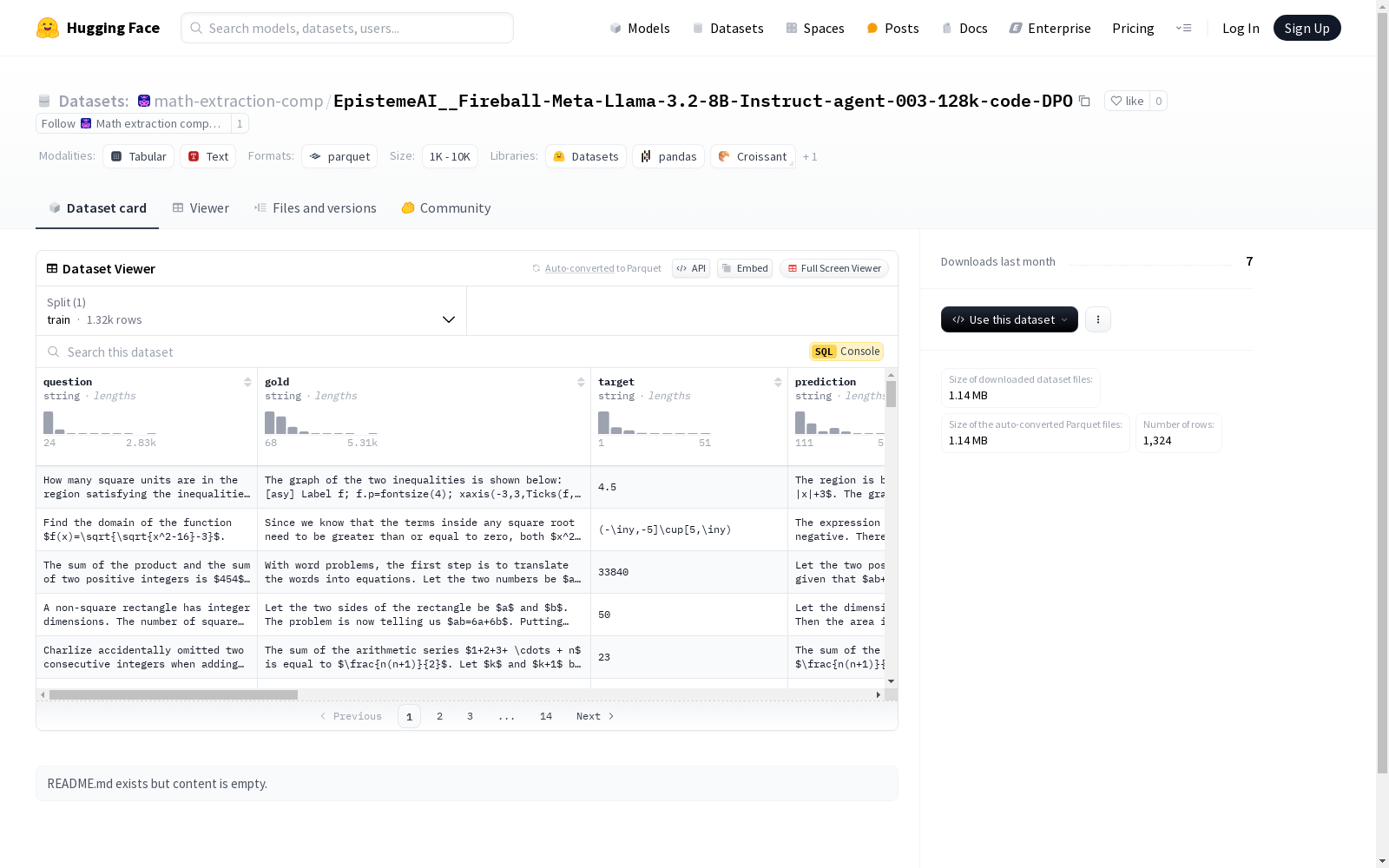
该数据集包含多个字段,主要涉及问答系统的评估。字段包括问题(question)、正确答案(gold)、目标(target)、预测(prediction)、子集(subset)、提取的答案(如lighteval-2018ed86_extracted_answer、qwen_extracted_answer等)和评分(如lighteval-2018ed86_score、qwen_score等)。数据集被分割为训练集,包含1324个样本,总大小为2885033字节。
This dataset includes multiple fields primarily focused on the evaluation of question answering systems. The fields consist of question, gold (correct answer), target, prediction, subset, extracted answers (e.g., lighteval-2018ed86_extracted_answer, qwen_extracted_answer) and scores (e.g., lighteval-2018ed86_score, qwen_score). The dataset is split into a training set containing 1324 samples with a total size of 2885033 bytes.
创建时间:
2025-01-08
搜集汇总
数据集介绍
构建方式
EpistemeAI__Fireball-Meta-Llama-3.2-8B-Instruct-agent-003-128k-code-DPO数据集的构建基于多源数据的整合与标注。该数据集通过收集大量问答对,并结合自动化工具与人工审核,确保了数据的多样性与准确性。每个样本包含问题、标准答案、预测答案及多个评估指标,涵盖了不同子集和评分体系,形成了一个综合性的问答评估数据集。
特点
该数据集的特点在于其多维度的评估体系,不仅包含传统的问答对,还引入了多个评估工具生成的提取答案与评分。数据集中的每个样本均经过严格的标注与验证,确保了数据的可靠性与一致性。此外,数据集涵盖了多个子集,能够满足不同场景下的模型评估需求,具有较强的通用性与实用性。
使用方法
该数据集适用于问答系统与自然语言处理模型的训练与评估。用户可通过加载数据集,获取问题、标准答案及预测答案等信息,结合多个评估指标对模型性能进行综合分析。数据集支持直接用于模型微调或作为基准测试工具,帮助研究人员优化模型表现并提升问答系统的准确性与鲁棒性。
背景与挑战
背景概述
EpistemeAI__Fireball-Meta-Llama-3.2-8B-Instruct-agent-003-128k-code-DPO数据集是由EpistemeAI团队开发的一个多任务评估数据集,旨在推动自然语言处理(NLP)领域中的指令跟随与代码生成任务的研究。该数据集创建于2023年,主要研究人员来自EpistemeAI,专注于评估大型语言模型在复杂指令理解与执行任务中的表现。数据集的核心研究问题在于如何通过多维度评估指标,提升模型在生成代码、回答问题等任务中的准确性与鲁棒性。该数据集的发布为NLP领域的研究者提供了一个新的基准,推动了指令跟随模型与代码生成模型的进一步发展。
当前挑战
该数据集面临的挑战主要体现在两个方面。首先,在领域问题方面,数据集旨在解决指令跟随与代码生成任务中的模型评估难题,尤其是在多任务场景下,如何准确评估模型在不同任务中的表现仍然是一个复杂的问题。其次,在数据构建过程中,研究人员需要处理大量异构数据,确保数据的一致性与质量,同时还需要设计合理的评估指标,以全面反映模型的性能。这些挑战不仅要求数据集的构建者具备深厚的领域知识,还需要在数据处理与评估方法上进行创新。
常用场景
经典使用场景
在自然语言处理领域,EpistemeAI__Fireball-Meta-Llama-3.2-8B-Instruct-agent-003-128k-code-DPO数据集被广泛应用于问答系统的训练与评估。通过提供包含问题、标准答案、预测答案及评分的数据,该数据集为模型在复杂问答任务中的表现提供了基准。研究人员利用该数据集进行模型微调,以提升模型在开放域问答中的准确性和鲁棒性。
实际应用
在实际应用中,该数据集被用于开发智能客服、教育辅助工具和知识检索系统。通过训练模型使用该数据集,企业能够构建更高效的自动化问答系统,减少人工干预,提升用户体验。例如,在教育领域,该数据集帮助开发了能够即时回答学生问题的智能辅导工具。
衍生相关工作
基于该数据集,研究人员开发了多种改进的问答模型和评估框架。例如,一些研究专注于利用该数据集的多维度评分信息,优化模型的答案生成策略;另一些研究则通过结合该数据集与其他领域数据,探索跨领域问答系统的可能性。这些工作进一步推动了问答系统技术的发展。
以上内容由遇见数据集搜集并总结生成


