limingcv/Captioned_ADE20K
收藏Hugging Face2023-10-30 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/limingcv/Captioned_ADE20K
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: image
dtype: image
- name: detailed_prompt
dtype: string
- name: control_seg
dtype: image
- name: seg_map
sequence:
sequence: uint8
- name: image_path
dtype: string
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 11095603078.08
num_examples: 20210
- name: validation
num_bytes: 1128604170.0
num_examples: 2000
download_size: 7044514076
dataset_size: 12224207248.08
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
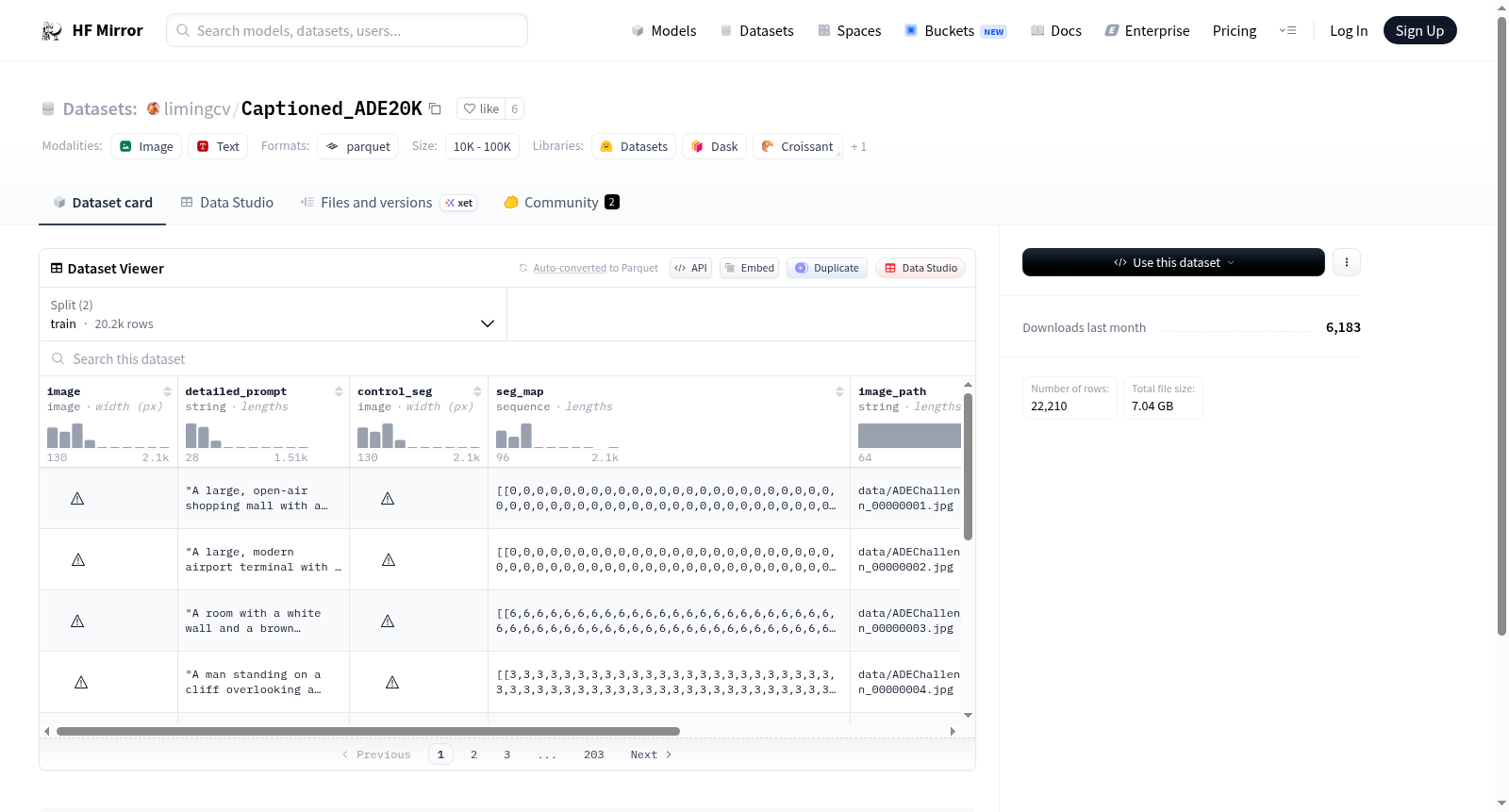
The dataset includes features such as image, detailed prompt, control segmentation, segmentation map, image path, and prompt. It is divided into a training set and a validation set, containing 20210 and 2000 samples respectively. The download size of the dataset is 7044514076 bytes, and the total size is 12224207248.08 bytes. The dataset configuration is set to default, with the training and validation data files stored in data/train-* and data/validation-* paths respectively.
提供机构:
limingcv
原始信息汇总
数据集概述
数据特征
- image: 图像数据
- detailed_prompt: 字符串类型
- control_seg: 图像数据
- seg_map: 序列类型,内部为uint8类型
- image_path: 字符串类型
- prompt: 字符串类型
数据分割
- train: 训练集,包含20210个样本,大小为11095603078.08字节
- validation: 验证集,包含2000个样本,大小为1128604170.0字节
数据集大小
- 下载大小: 7044514076字节
- 数据集大小: 12224207248.08字节
配置信息
- config_name: default
- data_files:
- train: 路径为
data/train-* - validation: 路径为
data/validation-*
- train: 路径为
- data_files:
搜集汇总
数据集介绍
构建方式
在语义分割领域,高质量且带有详细文本描述的数据集是推动多模态模型发展的关键。limingcv/Captioned_ADE20K数据集基于经典的ADE20K语义分割数据集构建,通过为每张图像生成详尽的自然语言描述,将视觉场景与文本信息深度融合。其构建过程涉及对原始ADE20K数据集中的图像进行人工或自动标注,生成包含场景整体描述、物体细节及空间关系的详细提示(detailed_prompt),同时保留原有的语义分割掩码(seg_map)和精简提示(prompt),形成多模态对齐的样本结构。
使用方法
该数据集适用于多种多模态与计算机视觉任务。在模型训练中,可直接加载图像与对应的文本描述用于图文对齐或图像描述生成,亦可利用语义分割掩码进行条件扩散模型(如ControlNet)的训练。用户可通过HuggingFace的datasets库加载数据,指定split参数选择训练或验证集,并利用图像字段进行视觉编码,同时将detailed_prompt或prompt作为文本监督信号。对于需要语义控制的任务,seg_map和control_seg字段提供了精确的空间引导信息。
背景与挑战
背景概述
在计算机视觉与自然语言处理交叉领域中,图像语义理解与精细化描述生成一直是研究的热点与难点。limingcv/Captioned_ADE20K数据集由研究团队于近年创建,基于经典的ADE20K场景解析数据集进行扩展,核心研究问题在于如何为复杂的场景图像提供兼具语义分割标注与高质量自然语言描述的多模态数据。该数据集包含超过2万张训练图像及其对应的详细提示文本、语义分割控制图与原始分割映射,为视觉语言模型、可控图像生成及细粒度场景理解等任务提供了关键支撑。其发布显著推动了多模态学习与生成式模型在复杂场景下的对齐能力,影响力覆盖图像描述、语义分割及扩散模型控制等领域。
当前挑战
该数据集所解决的领域挑战在于弥合视觉场景解析与语言生成之间的语义鸿沟,传统图像描述数据集往往缺乏精确的像素级语义对应,而Captioned_ADE20K通过引入详细提示与分割控制图,使得模型能够学习到区域级属性与空间关系的语言表达。构建过程中的挑战则体现在多模态标注的复杂性与一致性维护上,包括为每张图像生成与语义分割严格对齐的详细文本描述,确保不同标注者之间对场景要素的语言表达风格统一,以及处理长尾类别与罕见场景的标注覆盖问题。此外,大规模图像数据的存储与高效加载、分割映射与文本的跨模态校验也是工程实现上的显著难点。
常用场景
经典使用场景
Captioned_ADE20K数据集在计算机视觉与自然语言处理的交叉领域中占据着举足轻重的地位,其经典使用场景在于为图像语义分割任务提供精细化文本描述。不同于传统仅含类别标签的语义分割数据集,该数据集为每张图像配备了详尽的自然语言提示(detailed_prompt),使得模型在预测像素级分割掩码的同时,能够理解场景中物体的语义关系与视觉属性。这种多模态对齐特性使其成为训练可控图像生成模型、视觉问答系统以及图像描述生成器的理想基准。研究者借助该数据集,可探索如何将结构化分割图(control_seg)与自由文本描述相结合,从而提升模型对复杂场景的细粒度理解能力,推动从“看到”到“看懂”的认知跃迁。
解决学术问题
该数据集的核心学术贡献在于弥合了像素级分割与高层语义理解之间的鸿沟。传统语义分割研究常受限于固定类别体系,难以捕捉场景中物体的上下文关联与视觉细节。Captioned_ADE20K通过引入密集、多样化的文本标注,解决了多标签场景下视觉概念歧义性的问题,为开放词汇分割、零样本学习以及场景图生成等前沿课题提供了关键数据支撑。其意义在于构建了一个统一的评估框架,使得研究者能够量化模型在同时完成分割与描述任务时的性能,进而推动视觉语言预训练范式的演进。该数据集的出现,有效促进了从孤立任务学习向联合推理范式的转型,对理解视觉场景的深层结构具有里程碑式的影响。
实际应用
在实际应用中,Captioned_ADE20K驱动的技术已渗透至多个高价值领域。在自动驾驶场景中,结合文本描述的分割模型能够更精准地识别“人行道上的红色车辆”或“右侧车道施工区域”等复杂指令,提升环境感知的鲁棒性。在医学影像分析中,该数据集启发的多模态方法可辅助医生定位“肺部左下叶的毛玻璃结节”并生成结构化报告,降低误诊风险。此外,在电商视觉搜索与辅助设计领域,用户可通过自然语言描述(如“客厅中带有金属腿的棕色沙发”)直接检索或生成符合要求的图像,极大优化了人机交互体验。这些实践充分证明了该数据集在连接视觉感知与语言推理方面的巨大实用价值。
数据集最近研究
最新研究方向
在当前多模态大模型与可控生成技术蓬勃发展的背景下,limingcv/Captioned_ADE20K数据集通过为经典的场景解析数据集ADE20K赋予细粒度、丰富的自然语言描述,开辟了语义分割与文本生成深度融合的新前沿。该数据集不仅保留了原始的精细分割掩码(seg_map),还提供了面向控制生成的条件分割图像(control_seg)以及用于引导模型的详细提示文本(detailed_prompt),使其成为研究基于文本引导的图像编辑、可控场景合成以及跨模态语义对齐的关键资源。近期研究热点聚焦于利用该数据集训练能够理解复杂场景语义并生成对应描述的分割-语言联合模型,以及探索如何将分割先验注入扩散模型以实现高保真度的条件图像生成。这一工作推动了从纯粹的像素级理解向语义理解与生成一体化范式的转变,对构建更智能、更可控的视觉内容创作工具具有深远影响。
以上内容由遇见数据集搜集并总结生成


