Move360
收藏VegQi/Move360 数据集概述
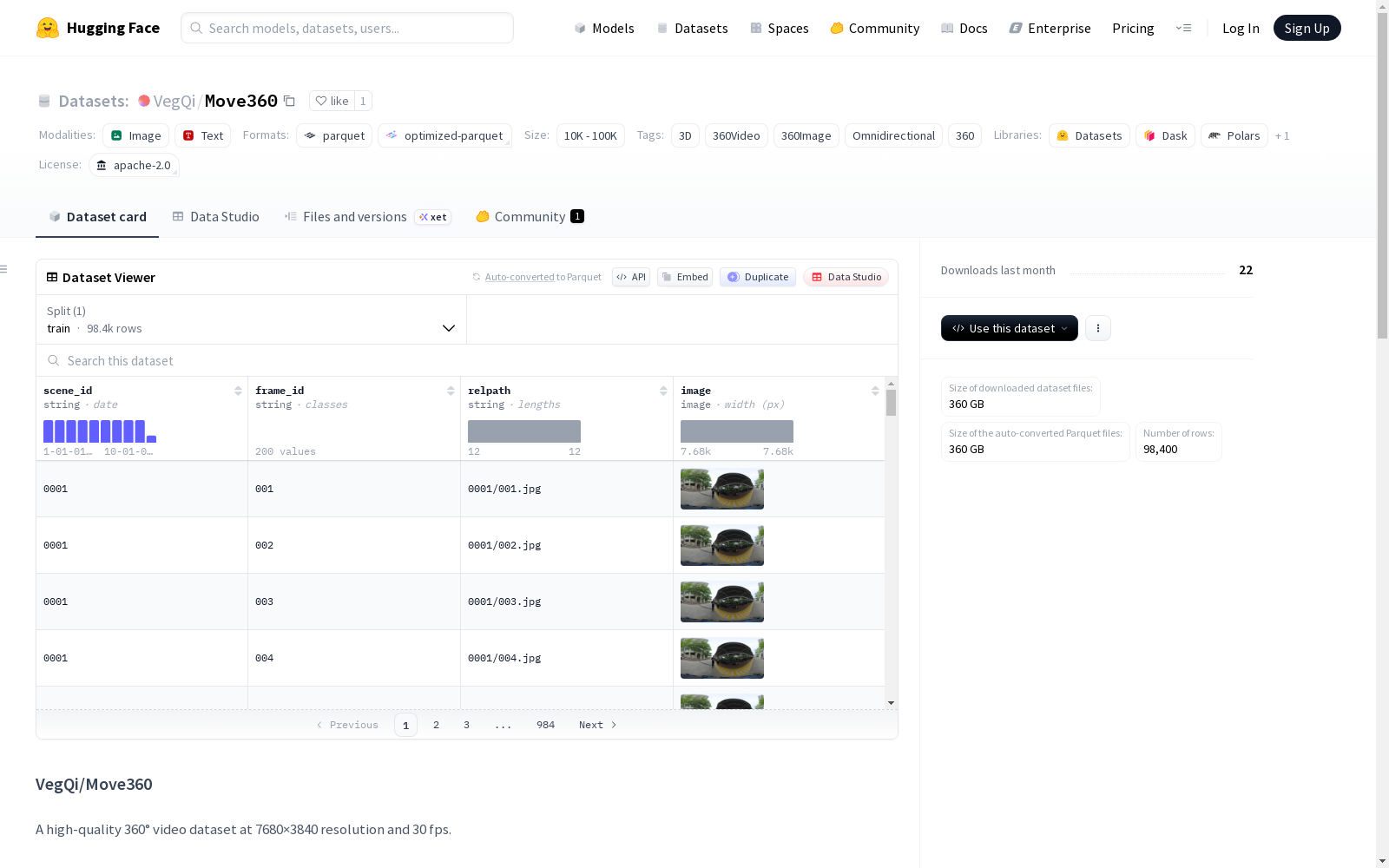
数据集基本信息
- 数据集名称: VegQi/Move360
- 许可协议: Apache-2.0
- 数据规模: 10K<n<100K
- 相关标签: 3D, 360Video, 360Image, Omnidirectional, 360
数据集描述
这是一个高质量的360°视频数据集,分辨率为7680×3840,帧率为30 fps。
数据结构与模式
数据集以表格结构表示,每一行对应一个单独的图像帧(或一个单独的图像实例)。包含以下字段:
scene_id: 场景/片段剪辑的标识符(例如"0001")。frame_id: 帧的标识符,源自不带扩展名的文件名主干(例如"00000001")。relpath: 原始相对路径,遵循原始目录结构(例如"0001/00000001.jpg")。image: 图像内容,存储为datasets.Image特征;访问时可直接解码为PIL图像对象。
快速开始
安装依赖
bash pip install -U datasets pillow
加载数据集
python from datasets import load_dataset ds = load_dataset("VegQi/Move360", split="train") print(ds) print(ds.features)
访问样本与解码图像
python sample = ds[0] scene_id = sample["scene_id"] frame_id = sample["frame_id"] relpath = sample["relpath"] img = sample["image"] # PIL.Image.Image print(scene_id, frame_id, relpath, img.size)
引用
如果在研究或工作中使用此数据集,请引用以下论文:
@article{li2025omnidrag, title={OmniDrag: Enabling Motion Control for Omnidirectional Image-to-Video Generation}, author={Li, Weiqi and Zhao, Shijie and Mou, Chong and Sheng, Xuhan and Zhang, Zhenyu and Wang, Qian and Li, Junlin and Zhang, Li and Zhang, Jian}, journal={International Journal of Computer Vision (IJCV)}, year={2025} }