---
annotations_creators:
- machine-generated
language_creators:
- found
language:
- af
- an
- ar
- arz
- ast
- az
- azb
- ba
- bar
- be
- bg
- bn
- br
- bs
- ca
- ce
- ceb
- ckb
- cs
- cv
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gl
- hi
- hr
- hsb
- ht
- hu
- hy
- ia
- id
- io
- is
- it
- iw
- ja
- jv
- ka
- kk
- kn
- ko
- la
- lah
- lb
- lmo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- nan
- nds
- ne
- nl
- nn
- 'no'
- nv
- oc
- pa
- pl
- pt
- qu
- ro
- ru
- sco
- si
- sk
- sl
- sq
- sr
- sv
- sw
- ta
- te
- tg
- th
- tr
- tt
- uk
- ur
- uz
- vec
- vi
- vo
- war
- xmf
- yue
- zh
license:
- cc-by-sa-4.0
multilinguality:
- multilingual
size_categories:
- 1M<n<10M
source_datasets:
- original
- extended|wikipedia
task_categories:
- image-to-text
- text-retrieval
task_ids:
- image-captioning
paperswithcode_id: wit
pretty_name: Wikipedia-based Image Text
language_bcp47:
- af
- an
- ar
- arz
- ast
- az
- azb
- ba
- bar
- be
- be-tarask
- bg
- bn
- br
- bs
- ca
- ce
- ceb
- ckb
- cs
- cv
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gl
- hi
- hr
- hsb
- ht
- hu
- hy
- ia
- id
- io
- is
- it
- iw
- ja
- jv
- ka
- kk
- kn
- ko
- la
- lah
- lb
- lmo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- nan
- nds
- ne
- nl
- nn
- 'no'
- nv
- oc
- pa
- pl
- pt
- qu
- ro
- ru
- sco
- si
- sk
- sl
- sq
- sr
- sr-Latn
- sv
- sw
- ta
- te
- tg
- th
- tr
- tt
- uk
- ur
- uz
- vec
- vi
- vo
- war
- xmf
- yue
- zh
- zh-TW
tags:
- text-image-retrieval
---
# Dataset Card for WIT
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [WIT homepage](https://github.com/google-research-datasets/wit)
- **Paper:** [WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
](https://arxiv.org/abs/2103.01913)
- **Leaderboard:** [WIT leaderboard](https://paperswithcode.com/sota/text-image-retrieval-on-wit) and [WIT Kaggle competition](https://www.kaggle.com/competitions/wikipedia-image-caption/leaderboard)
- **Point of Contact:** [Miriam Redi](mailto:miriam@wikimedia.org)
### Dataset Summary
Wikimedia's version of the Wikipedia-based Image Text (WIT) Dataset, a large multimodal multilingual dataset.
From the [official blog post](https://techblog.wikimedia.org/2021/09/09/the-wikipedia-image-caption-matching-challenge-and-a-huge-release-of-image-data-for-research/):
> The core training data is taken from the Wikipedia Image-Text (WIT) Dataset, a large curated set of more than 37 million image-text associations extracted from Wikipedia articles in 108 languages that was recently released by Google Research.
>
> The WIT dataset offers extremely valuable data about the pieces of text associated with Wikipedia images. However, due to licensing and data volume issues, the Google dataset only provides the image name and corresponding URL for download and not the raw image files.
>
> Getting easy access to the image files is crucial for participants to successfully develop competitive models. Therefore, today, the Wikimedia Research team is releasing its first large image dataset. It contains more than six million image files from Wikipedia articles in 100+ languages, which correspond to almost [1] all captioned images in the WIT dataset. Image files are provided at a 300-px resolution, a size that is suitable for most of the learning frameworks used to classify and analyze images.
> [1] We are publishing all images having a non-null “reference description” in the WIT dataset. For privacy reasons, we are not publishing images where a person is the primary subject, i.e., where a person’s face covers more than 10% of the image surface. To identify faces and their bounding boxes, we use the RetinaFace detector. In addition, to avoid the inclusion of inappropriate images or images that violate copyright constraints, we have removed all images that are candidate for deletion on Commons from the dataset.
**Note**: Compared to [Google's version](https://huggingface.co/datasets/google/wit), which has contents of one Wikipedia page per data sample, this version groups contents of all Wikipedia pages available in different languages for the image in one single data sample to avoid duplication of image bytes.
### Supported Tasks and Leaderboards
- `image-captioning`: This dataset can be used to train a model for image captioning where the goal is to predict a caption given the image.
- `text-retrieval`: The goal in this task is to build a model that retrieves the text (`caption_title_and_reference_description`) closest to an image. The leaderboard for this task can be found [here](https://paperswithcode.com/sota/text-image-retrieval-on-wit). This task also has a competition on [Kaggle](https://www.kaggle.com/c/wikipedia-image-caption).
In these tasks, any combination of the `caption_reference_description`, `caption_attribution_description` and `caption_alt_text_description` fields can be used as the input text/caption.
### Languages
The dataset contains examples from all Wikipedia languages.
## Dataset Structure
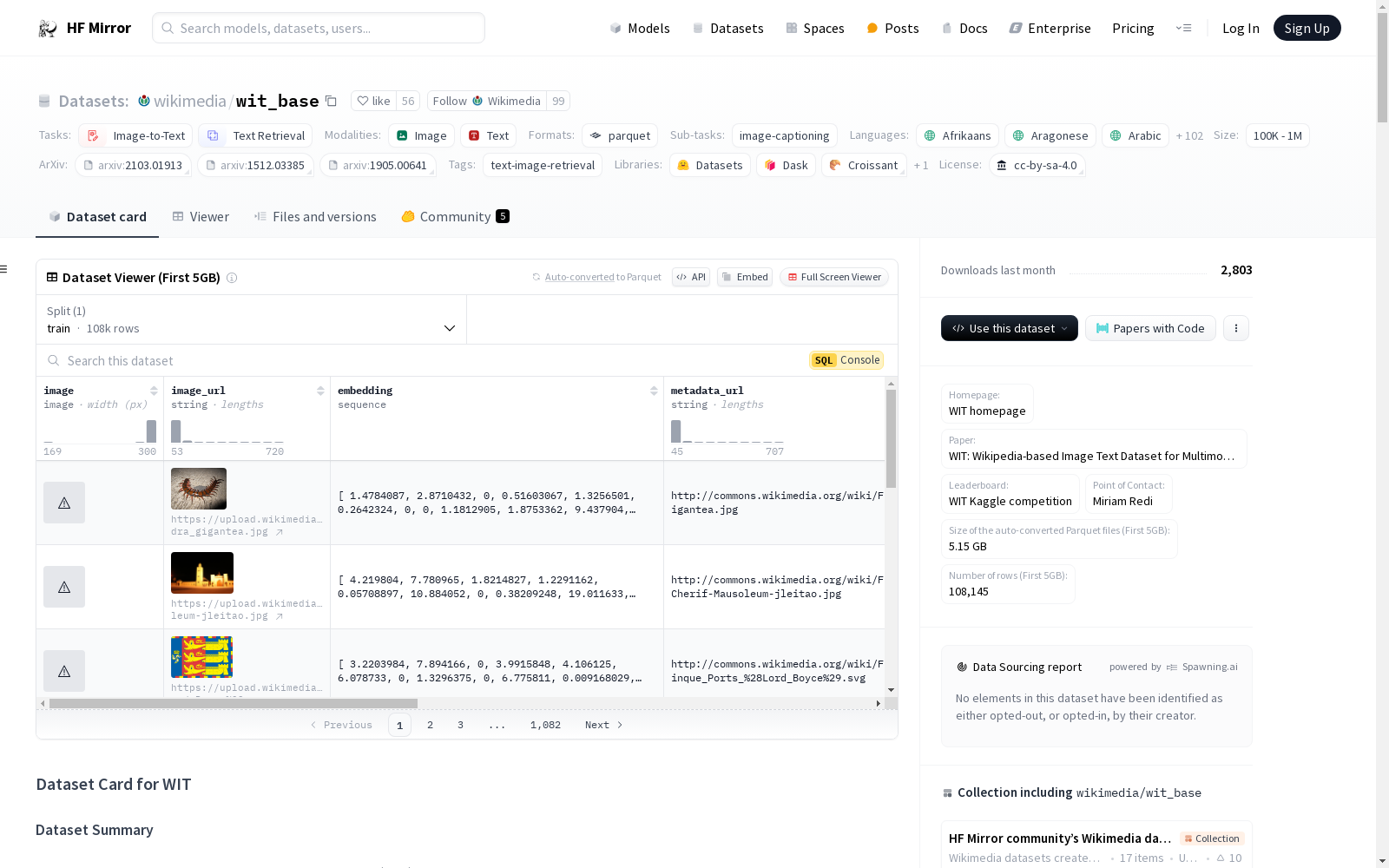
### Data Instances
Each instance is an image, its representation in bytes, a pre-computed embedding, and the set of captions attached to the image in Wikipedia.
```
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=300x225 at 0x7F88F3876358>,
'image_url': 'https://upload.wikimedia.org/wikipedia/commons/8/8b/Scolopendra_gigantea.jpg',
'embedding': [1.4784087, 2.8710432, 0.0, 0.51603067, ..., 10.266883, 0.51142216, 0.0, 2.3464653],
'metadata_url': 'http://commons.wikimedia.org/wiki/File:Scolopendra_gigantea.jpg',
'original_height': 3000,
'original_width': 4000,
'mime_type': 'image/jpeg',
'caption_attribution_description': 'English: Puerto Rican Giant Centipede, Scolopendra gigantea; Vieques, Puerto Rico Slovenčina: Stonožka obrovská, Scolopendra gigantea; Vieques, Portoriko',
'wit_features': {
'language': ['ro', 'vi', 'sk', ..., 'nl', 'th', 'lv'],
'page_url': ['https://ro.wikipedia.org/wiki/Scolopendra_gigantea', 'https://vi.wikipedia.org/wiki/Scolopendra_gigantea', 'https://sk.wikipedia.org/wiki/Scolopendra_gigantea', ..., 'https://nl.wikipedia.org/wiki/Scolopendra_gigantea', 'https://th.wikipedia.org/wiki/%E0%B8%95%E0%B8%B0%E0%B8%82%E0%B8%B2%E0%B8%9A%E0%B8%A2%E0%B8%B1%E0%B8%81%E0%B8%A9%E0%B9%8C%E0%B8%82%E0%B8%B2%E0%B9%80%E0%B8%AB%E0%B8%A5%E0%B8%B7%E0%B8%AD%E0%B8%87%E0%B9%80%E0%B8%9B%E0%B8%A3%E0%B8%B9', 'https://lv.wikipedia.org/wiki/Skolopendru_dzimta'],
'attribution_passes_lang_id': [True, True, True, ..., True, True, True],
'caption_alt_text_description': [None, None, None, ..., 'Scolopendra gigantea', None, 'Milzu skolopendra (Scolopendra gigantea)'],
'caption_reference_description': [None, None, None, ..., None, None, 'Milzu skolopendra (Scolopendra gigantea)'],
'caption_title_and_reference_description': [None, 'Scolopendra gigantea [SEP] ', None, ..., 'Scolopendra gigantea [SEP] ', None, 'Skolopendru dzimta [SEP] Milzu skolopendra (Scolopendra gigantea)'],
'context_page_description': ['Scolopendra gigantea este un miriapod din clasa Chilopoda, fiind cel mai mare reprezentant al genului Scolopendra. Adultul poate atinge o lungime de 26 cm, uneori depășind 30 cm. Această specie habitează în regiunile de nord și de vest a Americii de Sud, pe insulele Trinidad, insulele Virgine, Jamaica Hispaniola ș.a. Localnicii denumesc scolopendra chilopodul gigant galben și chilopodul gigant amazonian.', 'Scolopendra gigantea là đại diện lớn nhất của chi Scolopendra nói riêng và cả lớp rết nói chung, thường đạt độ dài 26 cm và có thể vượt quá 30 cm. Sinh sống ở khu vực phía bắc và tây của Nam Mỹ và các đảo Trinidad, Puerto Rico, Saint Thomas, U.S. Virgin Islands, Jamaica, và Hispaniola.', 'Scolopendra gigantea, starší slovenský nazov: štípavica veľká, je živočích z rodu Scolopendra, s veľkosťou do 30 cm.', ..., 'Scolopendra gigantea is een tijgerduizendpoot uit Zuid-Amerika. De soort jaagt onder andere op grote geleedpotigen, amfibieën, reptielen en kleine zoogdieren. Het is voor zover bekend de grootste niet uitgestorven duizendpoot ter wereld.', 'ตะขาบยักษ์ขาเหลืองเปรู หรือ ตะขาบยักษ์อเมซอน เป็นตะขาบชนิดที่มีขนาดใหญ่ที่สุดในสกุล Scolopendra โดยปกติเมื่อโตเต็มที่จะยาว 26 เซนติเมตร แต่บางครั้งก็สามารถโตได้ถึง 30 เซนติเมตร ตะขาบชนิดนี้อาศัยอยู่ทางแถบเหนือและตะวันตกของทวีปอเมริกาใต้ และตามเกาะแก่งของประเทศตรินิแดดและจาไมกา เป็นสัตว์กินเนื้อ โดยกินจิ้งจก, กบ, นก, หนู และแม้แต่ค้างคาวเป็นอาหาร และขึ้นชื่อในเรื่องความดุร้าย', 'Skolpendru dzimta pieder pie simtkāju kārtas. Ap 400 dzimtas sugas sastopamas visā pasaulē, īpaši subtropu un tropu apgabalos. Mitinās augsnē, nobirušās lapās, plaisās, spraugās.'],
'context_section_description': [None, 'Scolopendra gigantea (còn được gọi là Rết chân vàng khổng lồ Peru và Rết khổng lồ Amazon) là đại diện lớn nhất của chi Scolopendra nói riêng và cả lớp rết nói chung, thường đạt độ dài 26\xa0cm (10\xa0in) và có thể vượt quá 30\xa0cm (12\xa0in). Sinh sống ở khu vực phía bắc và tây của Nam Mỹ và các đảo Trinidad, Puerto Rico, Saint Thomas, U.S. Virgin Islands, Jamaica, và Hispaniola.', None, ..., 'Scolopendra gigantea is een tijgerduizendpoot uit Zuid-Amerika. De soort jaagt onder andere op grote geleedpotigen, amfibieën, reptielen en kleine zoogdieren. Het is voor zover bekend de grootste niet uitgestorven duizendpoot ter wereld.', None, 'Skolpendru dzimta (Scolopendridae) pieder pie simtkāju kārtas. Ap 400 dzimtas sugas sastopamas visā pasaulē, īpaši subtropu un tropu apgabalos. Mitinās augsnē, nobirušās lapās, plaisās, spraugās.'],
'hierarchical_section_title': ['Scolopendra gigantea', 'Scolopendra gigantea', 'Scolopendra gigantea', ..., 'Scolopendra gigantea', 'ตะขาบยักษ์ขาเหลืองเปรู', 'Skolopendru dzimta'],
'is_main_image': [True, True, True, ..., True, True, True],
'page_title': ['Scolopendra gigantea', 'Scolopendra gigantea', 'Scolopendra gigantea', ..., 'Scolopendra gigantea', 'ตะขาบยักษ์ขาเหลืองเปรู', 'Skolopendru dzimta'],
'section_title': [None, None, None, ..., None, None, None]
}
}
```
**Note**: The dataset is stored in Parquet for better performance. This dataset was generated from the original files using [this script](wit_base/blob/main/scripts/wit.py). Additionally, 120 examples from the original files have incorrectly formatted one or more of the following fields: `original_height`, `original_width`, `mime_type` and `caption_attribution_description`. The fixed versions of these examples that were used in the generation script can be found [here](wit_base/blob/main/scripts/corrected_examples.py).
### Data Fields
- `image`: A `PIL.Image.Image` object containing the image resized to a width of 300-px while preserving its aspect ratio. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`.
- `image_url`: URL to wikipedia image
- `embedding`: Precomputed image embedding. Each image is described with a 2048-dimensional signature extracted from the second-to-last layer of a [ResNet-50](https://arxiv.org/abs/1512.03385) neural network trained with [Imagenet](https://www.image-net.org/) data. These embeddings contain rich information about the image content and layout, in a compact form
- `metadata_url`: URL to wikimedia page containing the image and the metadata
- `original_height`: Original image height before resizing
- `original_width`: Original image width before resizing
- `mime_type`: Mime type associated to the image
- `caption_attribution_description`: This is the text found on the Wikimedia page of the image. This text is common to all occurrences of that image across all Wikipedias.
- `wit_features`: Sequence of captions for the image with language, page URL, information about the page, caption text, etc.
- `language`: Language code depicting wikipedia language of the page
- `page_url`: URL to wikipedia page
- `attribution_passes_lang_id`: Compared `language` field with the attribution language (written in the prefix of the attribution description.
- `caption_alt_text_description`: This is the “alt” text associated with the image. While not visible in general, it is commonly used for accessibility / screen readers
- `caption_reference_description`: This is the caption that is visible on the wikipedia page directly below the image.
- `caption_title_and_reference_description`: Concatenation of `page_title` and `caption_reference_description`.
- `context_page_description`: Corresponds to the short description of the page. It provides a concise explanation of the scope of the page.
- `context_section_description`: Text within the image's section
- `hierarchical_section_title`: Hierarchical section's title
- `is_main_image`: Flag determining if the image is the first image of the page. Usually displayed on the top-right part of the page when using web browsers.
- `page_changed_recently`: [More Information Needed]
- `page_title`: Wikipedia page's title
- `section_title`: Section's title
<p align='center'>
<img width='75%' src='https://production-media.paperswithcode.com/datasets/Screenshot_2021-03-04_at_14.26.02.png' alt="Half Dome" /> </br>
<b>Figure: WIT annotation example. </b>
</p>
Details on the field content can be found directly in the [paper, figure 5 and table 12.](https://arxiv.org/abs/2103.01913)
### Data Splits
All data is held in `train` split, with a total of 6477255 examples.
## Dataset Creation
### Curation Rationale
From the [official blog post](https://techblog.wikimedia.org/2021/09/09/the-wikipedia-image-caption-matching-challenge-and-a-huge-release-of-image-data-for-research/):
> The WIT dataset offers extremely valuable data about the pieces of text associated with Wikipedia images.
> Getting easy access to the image files is crucial for participants to successfully develop competitive models.
> With this large release of visual data, we aim to help the competition participants—as well as researchers and practitioners who are interested in working with Wikipedia images—find and download the large number of image files associated with the challenge, in a compact form.
### Source Data
#### Initial Data Collection and Normalization
From the [paper, section 3.1](https://arxiv.org/abs/2103.01913):
> We started with all Wikipedia content pages (i.e., ignoring other
pages that have discussions, comments and such). These number about ~124M pages across 279 languages.
#### Who are the source language producers?
Text was extracted from Wikipedia.
### Annotations
#### Annotation process
WIT was constructed using an automatic process. However it was human-validated.
From the [paper, section 3.7](https://arxiv.org/abs/2103.01913):
> To further verify the quality of the WIT dataset we performed a
study using (crowd-sourced) human annotators. As seen in Fig. 3,
we asked raters to answer 3 questions. Given an image and the page
title, raters first evaluate the quality of the attribution description
and reference description in the first two questions (order randomized). The third question understands the contextual quality of these
text descriptions given the page description and caption. Each response is on a 3-point scale: "Yes" if the text perfectly describes
the image, "Maybe" if it is sufficiently explanatory and "No" if it is
irrelevant or the image is inappropriate.
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
From the [official blog post](https://techblog.wikimedia.org/2021/09/09/the-wikipedia-image-caption-matching-challenge-and-a-huge-release-of-image-data-for-research/#FN1):
> For privacy reasons, we are not publishing images where a person is the primary subject, i.e., where a person’s face covers more than 10% of the image surface. To identify faces and their bounding boxes, we use the [RetinaFace](https://arxiv.org/abs/1905.00641) detector. In addition, to avoid the inclusion of inappropriate images or images that violate copyright constraints, we have removed all images that are [candidate for deletion](https://commons.wikimedia.org/wiki/Commons:Deletion_requests) on Commons from the dataset.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
From the [paper, section 3.4](https://arxiv.org/abs/2103.01913):
> Lastly we found that certain image-text pairs occurred very
frequently. These were often generic images that did not have
much to do with the main article page. Common examples
included flags, logos, maps, insignia and such. To prevent
biasing the data, we heavily under-sampled all such images
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Miriam Redi, Fabian Kaelin and Tiziano Piccardi.
### Licensing Information
[CC BY-SA 4.0 international license](https://creativecommons.org/licenses/by-sa/4.0/)
### Citation Information
```bibtex
@article{srinivasan2021wit,
title={WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning},
author={Srinivasan, Krishna and Raman, Karthik and Chen, Jiecao and Bendersky, Michael and Najork, Marc},
journal={arXiv preprint arXiv:2103.01913},
year={2021}
}
```
### Contributions
Thanks to [@nateraw](https://github.com/nateraw), [yjernite](https://github.com/yjernite) and [mariosasko](https://github.com/mariosasko) for adding this dataset.