wmt/wmt19
收藏Hugging Face2024-04-04 更新2024-03-04 收录
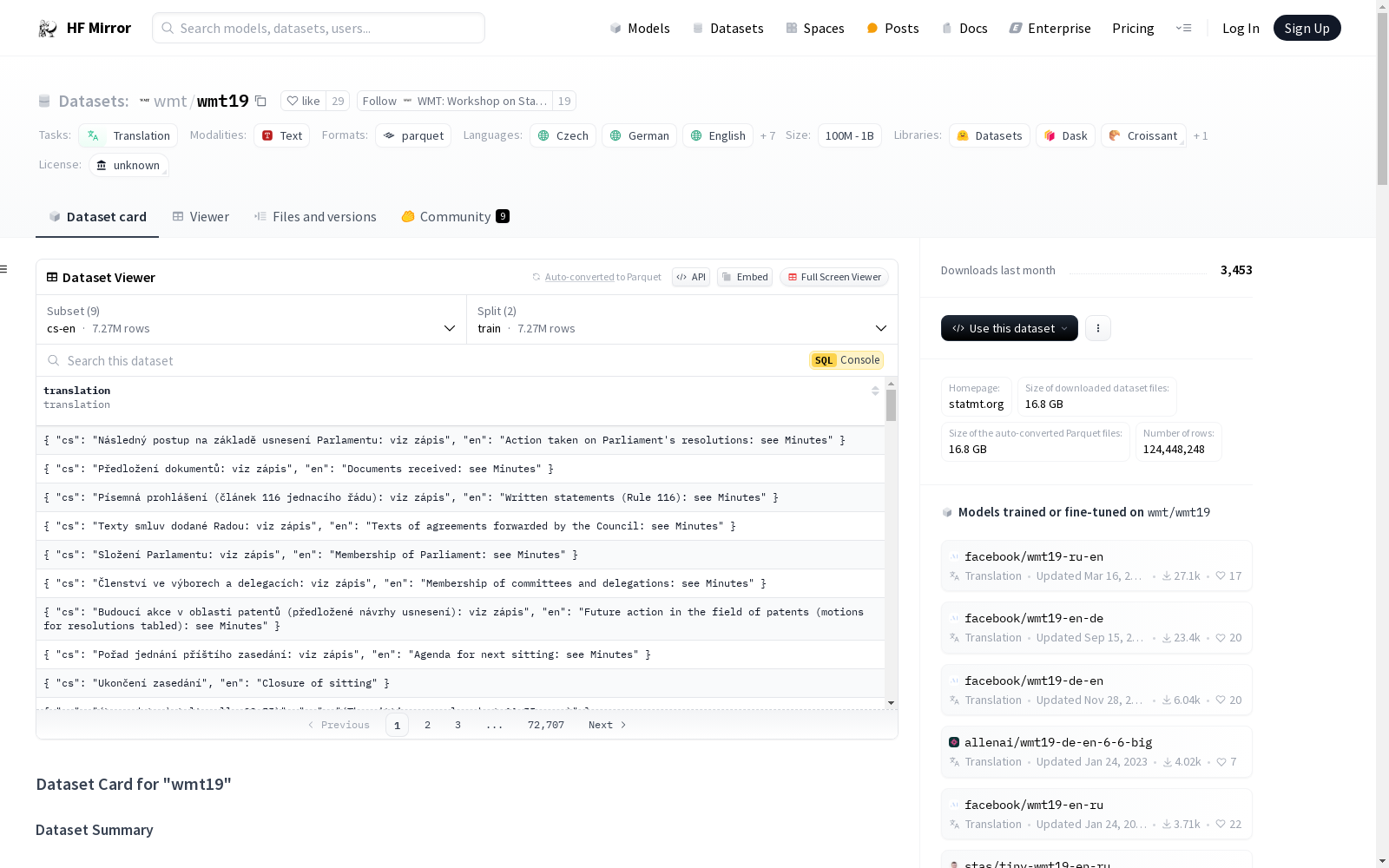
下载链接:
https://hf-mirror.com/datasets/wmt/wmt19
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- cs
- de
- en
- fi
- fr
- gu
- kk
- lt
- ru
- zh
license:
- unknown
multilinguality:
- translation
size_categories:
- 10M<n<100M
source_datasets:
- extended|europarl_bilingual
- extended|news_commentary
- extended|opus_paracrawl
- extended|un_multi
task_categories:
- translation
task_ids: []
pretty_name: WMT19
dataset_info:
- config_name: cs-en
features:
- name: translation
dtype:
translation:
languages:
- cs
- en
splits:
- name: train
num_bytes: 1314866170
num_examples: 7270695
- name: validation
num_bytes: 696221
num_examples: 2983
download_size: 665590448
dataset_size: 1315562391
- config_name: de-en
features:
- name: translation
dtype:
translation:
languages:
- de
- en
splits:
- name: train
num_bytes: 7645655677
num_examples: 34782245
- name: validation
num_bytes: 757641
num_examples: 2998
download_size: 4079732256
dataset_size: 7646413318
- config_name: fi-en
features:
- name: translation
dtype:
translation:
languages:
- fi
- en
splits:
- name: train
num_bytes: 1422916995
num_examples: 6587448
- name: validation
num_bytes: 691833
num_examples: 3000
download_size: 739629820
dataset_size: 1423608828
- config_name: fr-de
features:
- name: translation
dtype:
translation:
languages:
- fr
- de
splits:
- name: train
num_bytes: 2358405621
num_examples: 9824476
- name: validation
num_bytes: 441418
num_examples: 1512
download_size: 1261830726
dataset_size: 2358847039
- config_name: gu-en
features:
- name: translation
dtype:
translation:
languages:
- gu
- en
splits:
- name: train
num_bytes: 590747
num_examples: 11670
- name: validation
num_bytes: 774613
num_examples: 1998
download_size: 730223
dataset_size: 1365360
- config_name: kk-en
features:
- name: translation
dtype:
translation:
languages:
- kk
- en
splits:
- name: train
num_bytes: 9157334
num_examples: 126583
- name: validation
num_bytes: 846849
num_examples: 2066
download_size: 5759291
dataset_size: 10004183
- config_name: lt-en
features:
- name: translation
dtype:
translation:
languages:
- lt
- en
splits:
- name: train
num_bytes: 513082481
num_examples: 2344893
- name: validation
num_bytes: 541945
num_examples: 2000
download_size: 284890393
dataset_size: 513624426
- config_name: ru-en
features:
- name: translation
dtype:
translation:
languages:
- ru
- en
splits:
- name: train
num_bytes: 13721347178
num_examples: 37492126
- name: validation
num_bytes: 1085588
num_examples: 3000
download_size: 6167016481
dataset_size: 13722432766
- config_name: zh-en
features:
- name: translation
dtype:
translation:
languages:
- zh
- en
splits:
- name: train
num_bytes: 6391177013
num_examples: 25984574
- name: validation
num_bytes: 1107514
num_examples: 3981
download_size: 3615575187
dataset_size: 6392284527
configs:
- config_name: cs-en
data_files:
- split: train
path: cs-en/train-*
- split: validation
path: cs-en/validation-*
- config_name: de-en
data_files:
- split: train
path: de-en/train-*
- split: validation
path: de-en/validation-*
- config_name: fi-en
data_files:
- split: train
path: fi-en/train-*
- split: validation
path: fi-en/validation-*
- config_name: fr-de
data_files:
- split: train
path: fr-de/train-*
- split: validation
path: fr-de/validation-*
- config_name: gu-en
data_files:
- split: train
path: gu-en/train-*
- split: validation
path: gu-en/validation-*
- config_name: kk-en
data_files:
- split: train
path: kk-en/train-*
- split: validation
path: kk-en/validation-*
- config_name: lt-en
data_files:
- split: train
path: lt-en/train-*
- split: validation
path: lt-en/validation-*
- config_name: ru-en
data_files:
- split: train
path: ru-en/train-*
- split: validation
path: ru-en/validation-*
- config_name: zh-en
data_files:
- split: train
path: zh-en/train-*
- split: validation
path: zh-en/validation-*
---
# Dataset Card for "wmt19"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [http://www.statmt.org/wmt19/translation-task.html](http://www.statmt.org/wmt19/translation-task.html)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 2.02 GB
- **Size of the generated dataset:** 1.32 GB
- **Total amount of disk used:** 3.33 GB
### Dataset Summary
<div class="course-tip course-tip-orange bg-gradient-to-br dark:bg-gradient-to-r before:border-orange-500 dark:before:border-orange-800 from-orange-50 dark:from-gray-900 to-white dark:to-gray-950 border border-orange-50 text-orange-700 dark:text-gray-400">
<p><b>Warning:</b> There are issues with the Common Crawl corpus data (<a href="https://www.statmt.org/wmt13/training-parallel-commoncrawl.tgz">training-parallel-commoncrawl.tgz</a>):</p>
<ul>
<li>Non-English files contain many English sentences.</li>
<li>Their "parallel" sentences in English are not aligned: they are uncorrelated with their counterpart.</li>
</ul>
<p>We have contacted the WMT organizers, and in response, they have indicated that they do not have plans to update the Common Crawl corpus data. Their rationale pertains to the expectation that such data has been superseded, primarily by CCMatrix, and to some extent, by ParaCrawl datasets.</p>
</div>
Translation dataset based on the data from statmt.org.
Versions exist for different years using a combination of data
sources. The base `wmt` allows you to create a custom dataset by choosing
your own data/language pair. This can be done as follows:
```python
from datasets import inspect_dataset, load_dataset_builder
inspect_dataset("wmt19", "path/to/scripts")
builder = load_dataset_builder(
"path/to/scripts/wmt_utils.py",
language_pair=("fr", "de"),
subsets={
datasets.Split.TRAIN: ["commoncrawl_frde"],
datasets.Split.VALIDATION: ["euelections_dev2019"],
},
)
# Standard version
builder.download_and_prepare()
ds = builder.as_dataset()
# Streamable version
ds = builder.as_streaming_dataset()
```
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### cs-en
- **Size of downloaded dataset files:** 2.02 GB
- **Size of the generated dataset:** 1.32 GB
- **Total amount of disk used:** 3.33 GB
An example of 'validation' looks as follows.
```
```
### Data Fields
The data fields are the same among all splits.
#### cs-en
- `translation`: a multilingual `string` variable, with possible languages including `cs`, `en`.
### Data Splits
|name | train |validation|
|-----|------:|---------:|
|cs-en|7270695| 2983|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@ONLINE {wmt19translate,
author = "Wikimedia Foundation",
title = "ACL 2019 Fourth Conference on Machine Translation (WMT19), Shared Task: Machine Translation of News",
url = "http://www.statmt.org/wmt19/translation-task.html"
}
```
### Contributions
Thanks to [@patrickvonplaten](https://github.com/patrickvonplaten), [@mariamabarham](https://github.com/mariamabarham), [@thomwolf](https://github.com/thomwolf) for adding this dataset.
annotations_creators:
- 无注释
language_creators:
- 现有采集数据
language:
- 捷克语(cs)
- 德语(de)
- 英语(en)
- 芬兰语(fi)
- 法语(fr)
- 古吉拉特语(gu)
- 哈萨克语(kk)
- 立陶宛语(lt)
- 俄语(ru)
- 中文(zh)
license:
- 未知
multilinguality:
- 翻译型
size_categories:
- 1000万<样本数<1亿
source_datasets:
- 扩展|europarl_bilingual(欧洲议会双语语料库)
- 扩展|news_commentary(新闻评论语料库)
- 扩展|opus_paracrawl(OPUS平行语料库)
- 扩展|un_multi(联合国多语语料库)
task_categories:
- 翻译任务
task_ids: []
pretty_name: WMT19
dataset_info:
- config_name: cs-en(捷克语-英语)
features:
- name: translation
dtype:
translation:
languages:
- 捷克语(cs)
- 英语(en)
splits:
- name: train
num_bytes: 1314866170
num_examples: 7270695
- name: validation
num_bytes: 696221
num_examples: 2983
download_size: 665590448
dataset_size: 1315562391
- config_name: de-en(德语-英语)
features:
- name: translation
dtype:
translation:
languages:
- 德语(de)
- 英语(en)
splits:
- name: train
num_bytes: 7645655677
num_examples: 34782245
- name: validation
num_bytes: 757641
num_examples: 2998
download_size: 4079732256
dataset_size: 7646413318
- config_name: fi-en(芬兰语-英语)
features:
- name: translation
dtype:
translation:
languages:
- 芬兰语(fi)
- 英语(en)
splits:
- name: train
num_bytes: 1422916995
num_examples: 6587448
- name: validation
num_bytes: 691833
num_examples: 3000
download_size: 739629820
dataset_size: 1423608828
- config_name: fr-de(法语-德语)
features:
- name: translation
dtype:
translation:
languages:
- 法语(fr)
- 德语(de)
splits:
- name: train
num_bytes: 2358405621
num_examples: 9824476
- name: validation
num_bytes: 441418
num_examples: 1512
download_size: 1261830726
dataset_size: 2358847039
- config_name: gu-en(古吉拉特语-英语)
features:
- name: translation
dtype:
translation:
languages:
- 古吉拉特语(gu)
- 英语(en)
splits:
- name: train
num_bytes: 590747
num_examples: 11670
- name: validation
num_bytes: 774613
num_examples: 1998
download_size: 730223
dataset_size: 1365360
- config_name: kk-en(哈萨克语-英语)
features:
- name: translation
dtype:
translation:
languages:
- 哈萨克语(kk)
- 英语(en)
splits:
- name: train
num_bytes: 9157334
num_examples: 126583
- name: validation
num_bytes: 846849
num_examples: 2066
download_size: 5759291
dataset_size: 10004183
- config_name: lt-en(立陶宛语-英语)
features:
- name: translation
dtype:
translation:
languages:
- 立陶宛语(lt)
- 英语(en)
splits:
- name: train
num_bytes: 513082481
num_examples: 2344893
- name: validation
num_bytes: 541945
num_examples: 2000
download_size: 284890393
dataset_size: 513624426
- config_name: ru-en(俄语-英语)
features:
- name: translation
dtype:
translation:
languages:
- 俄语(ru)
- 英语(en)
splits:
- name: train
num_bytes: 13721347178
num_examples: 37492126
- name: validation
num_bytes: 1085588
num_examples: 3000
download_size: 6167016481
dataset_size: 13722432766
- config_name: zh-en(中文-英语)
features:
- name: translation
dtype:
translation:
languages:
- 中文(zh)
- 英语(en)
splits:
- name: train
num_bytes: 6391177013
num_examples: 25984574
- name: validation
num_bytes: 1107514
num_examples: 3981
download_size: 3615575187
dataset_size: 6392284527
configs:
- config_name: cs-en(捷克语-英语)
data_files:
- split: train
path: cs-en/train-*
- split: validation
path: cs-en/validation-*
- config_name: de-en(德语-英语)
data_files:
- split: train
path: de-en/train-*
- split: validation
path: de-en/validation-*
- config_name: fi-en(芬兰语-英语)
data_files:
- split: train
path: fi-en/train-*
- split: validation
path: fi-en/validation-*
- config_name: fr-de(法语-德语)
data_files:
- split: train
path: fr-de/train-*
- split: validation
path: fr-de/validation-*
- config_name: gu-en(古吉拉特语-英语)
data_files:
- split: train
path: gu-en/train-*
- split: validation
path: gu-en/validation-*
- config_name: kk-en(哈萨克语-英语)
data_files:
- split: train
path: kk-en/train-*
- split: validation
path: kk-en/validation-*
- config_name: lt-en(立陶宛语-英语)
data_files:
- split: train
path: lt-en/train-*
- split: validation
path: lt-en/validation-*
- config_name: ru-en(俄语-英语)
data_files:
- split: train
path: ru-en/train-*
- split: validation
path: ru-en/validation-*
- config_name: zh-en(中文-英语)
data_files:
- split: train
path: zh-en/train-*
- split: validation
path: zh-en/validation-*
---
# 数据集卡片:"wmt19"
## 目录
- [数据集概述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [语言覆盖](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [数据集遴选依据](#curation-rationale)
- [源数据](#source-data)
- [注释](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [授权信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献者](#contributions)
## 数据集概述
- **主页**:[http://www.statmt.org/wmt19/translation-task.html](http://www.statmt.org/wmt19/translation-task.html)
- **代码仓库**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **相关论文**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **联络人**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **下载数据集总大小**:2.02 GB
- **生成数据集总大小**:1.32 GB
- **总磁盘占用**:3.33 GB
### 数据集摘要
<div class="course-tip course-tip-orange bg-gradient-to-br dark:bg-gradient-to-r before:border-orange-500 dark:before:border-orange-800 from-orange-50 dark:from-gray-900 to-white dark:to-gray-950 border border-orange-50 text-orange-700 dark:text-gray--400">
<p><b>警告:</b> Common Crawl 语料库数据(<a href="https://www.statmt.org/wmt13/training-parallel-commoncrawl.tgz">training-parallel-commoncrawl.tgz</a>)存在如下问题:</p>
<ul>
<li>非英语文件中混杂大量英语句子。</li>
<li>其对应的"平行"英语句子未对齐:与原文无关联。</li>
</ul>
<p>我们已联系WMT组委会,对方表示暂无更新该Common Crawl语料库数据的计划。其理由为:此类数据已被CCMatrix(以及一定程度上的ParaCrawl数据集)所替代。</p>
</div>
本数据集为基于statmt.org数据构建的机器翻译数据集。不同年份的版本通过组合多种数据源生成。基础`wmt`数据集支持通过自选数据/语言对构建自定义数据集,实现方式如下:
python
from datasets import inspect_dataset, load_dataset_builder
inspect_dataset("wmt19", "path/to/scripts")
builder = load_dataset_builder(
"path/to/scripts/wmt_utils.py",
language_pair=("fr", "de"),
subsets={
datasets.Split.TRAIN: ["commoncrawl_frde"],
datasets.Split.VALIDATION: ["euelections_dev2019"],
},
)
# 标准版本
builder.download_and_prepare()
ds = builder.as_dataset()
# 流式版本
ds = builder.as_streaming_dataset()
### 支持任务与排行榜
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 语言覆盖
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集结构
### 数据实例
#### cs-en(捷克语-英语)
- **下载数据集大小**:2.02 GB
- **生成数据集大小**:1.32 GB
- **总磁盘占用**:3.33 GB
一个`validation`(验证集)的示例如下:
### 数据字段
所有划分的数据字段均保持一致。
#### cs-en(捷克语-英语)
- `translation`:多语言字符串变量,支持语言包括捷克语(cs)、英语(en)。
### 数据划分
| 划分名称 | 训练集样本数 | 验证集样本数 |
|-----|------:|---------:|
|cs-en|7270695| 2983|
## 数据集构建
### 数据集遴选依据
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 源数据
#### 初始数据收集与归一化
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 源语言生产者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 注释
#### 注释流程
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 注释者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 个人与敏感信息
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据使用注意事项
### 数据集的社会影响
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 偏差讨论
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 其他已知局限性
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 附加信息
### 数据集维护者
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 授权信息
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 引用信息
@ONLINE {wmt19translate,
author = "Wikimedia Foundation",
title = "ACL 2019 第四届机器翻译会议(WMT19)共享任务:新闻机器翻译",
url = "http://www.statmt.org/wmt19/translation-task.html"
}
### 贡献者
感谢 [@patrickvonplaten](https://github.com/patrickvonplaten), [@mariamabarham](https://github.com/mariamabarham), [@thomwolf](https://github.com/thomwolf) 为本数据集的添加工作。
提供机构:
wmt
原始信息汇总
数据集卡片概述
数据集描述
数据集概要
该数据集是一个多语言翻译数据集,基于statmt.org的数据。它包含了多种语言对的翻译数据,支持的任务主要是翻译。
支持的任务和排行榜
该数据集主要支持翻译任务。
语言
数据集包含以下语言:
- 捷克语 (cs)
- 德语 (de)
- 英语 (en)
- 芬兰语 (fi)
- 法语 (fr)
- 古吉拉特语 (gu)
- 哈萨克语 (kk)
- 立陶宛语 (lt)
- 俄语 (ru)
- 中文 (zh)
数据集结构
数据实例
数据集包含多个语言对的翻译数据,每个语言对有训练集和验证集。
数据字段
每个语言对的数据字段为:
translation: 一个多语言的字符串变量,包含源语言和目标语言。
数据分割
数据集的分割如下:
| 配置名称 | 训练集数量 | 验证集数量 |
|---|---|---|
| cs-en | 7270695 | 2983 |
| de-en | 34782245 | 2998 |
| fi-en | 6587448 | 3000 |
| fr-de | 9824476 | 1512 |
| gu-en | 11670 | 1998 |
| kk-en | 126583 | 2066 |
| lt-en | 2344893 | 2000 |
| ru-en | 37492126 | 3000 |
| zh-en | 25984574 | 3981 |
数据集创建
数据来源
数据集的来源包括:
- europarl_bilingual
- news_commentary
- opus_paracrawl
- un_multi
注释
数据集没有注释。
使用数据的注意事项
数据集的社会影响
偏见的讨论
其他已知限制
附加信息
数据集策展人
许可信息
数据集的许可信息未知。
引用信息
@ONLINE {wmt19translate, author = "Wikimedia Foundation", title = "ACL 2019 Fourth Conference on Machine Translation (WMT19), Shared Task: Machine Translation of News", url = "http://www.statmt.org/wmt19/translation-task.html" }
贡献
感谢@patrickvonplaten, @mariamabarham, @thomwolf 添加此数据集。
搜集汇总
数据集介绍
构建方式
WMT19数据集的构建基于statmt.org提供的翻译数据,涵盖了多种语言对。该数据集通过整合多个来源的数据,包括Europarl、News Commentary、OPUS Paracrawl和UN Multi,形成了一个大规模的多语言翻译语料库。每个语言对的训练和验证集均经过精心划分,确保数据的质量和多样性。
特点
WMT19数据集的显著特点在于其多语言性和大规模性。支持的语言对包括但不限于捷克语-英语、德语-英语、芬兰语-英语、法语-德语等,涵盖了多种语言组合。数据集的规模庞大,训练集的样本数量从数万到数千万不等,验证集则通常在数千条记录左右,适合用于训练和评估大规模翻译模型。
使用方法
使用WMT19数据集时,用户可以通过HuggingFace的datasets库进行加载和处理。具体操作包括指定语言对和数据子集,如训练集和验证集。数据集支持标准加载和流式加载两种方式,用户可以根据需求选择合适的方式进行数据处理。此外,数据集的结构清晰,便于用户进行定制化的数据预处理和模型训练。
背景与挑战
背景概述
WMT19数据集是由Wikimedia Foundation在2019年创建的,旨在支持机器翻译领域的研究。该数据集汇集了多种语言对的翻译数据,涵盖了捷克语、德语、英语、芬兰语、法语、古吉拉特语、哈萨克语、立陶宛语、俄语和中文等。WMT19数据集的核心研究问题是如何在多语言环境下实现高质量的机器翻译,其对机器翻译领域的贡献在于提供了大规模、多样化的语言对数据,推动了翻译模型的性能提升。
当前挑战
WMT19数据集在构建过程中面临了多重挑战。首先,数据来源的多样性带来了数据质量的参差不齐,尤其是Common Crawl数据集中存在大量非对齐的句子,影响了翻译模型的训练效果。其次,多语言数据的处理和整合需要克服语言间的语法、语义差异,确保翻译的准确性和流畅性。此外,数据集的规模庞大,如何高效地存储、处理和分析这些数据也是一大技术挑战。
常用场景
经典使用场景
WMT19数据集在机器翻译领域中扮演着至关重要的角色,尤其适用于多语言翻译任务的模型训练与评估。该数据集涵盖了多种语言对,如捷克语-英语、德语-英语、法语-德语等,为研究人员提供了丰富的语料资源。通过利用WMT19数据集,研究者能够构建和优化跨语言翻译模型,提升翻译系统的准确性和流畅度。
实际应用
WMT19数据集在实际应用中具有广泛的价值,尤其在跨国企业、国际组织和多语言服务提供商中。通过利用该数据集训练的翻译模型,企业能够实现高效的文档翻译、客户服务支持以及市场营销材料的本地化。此外,该数据集还支持多语言语音识别和生成系统的开发,为智能助手、语音翻译设备等应用提供了技术支持。
衍生相关工作
基于WMT19数据集,研究者们开发了多种先进的翻译模型和算法,推动了机器翻译领域的技术进步。例如,Transformer模型在WMT19数据集上的成功应用,显著提升了翻译质量。此外,该数据集还催生了多篇关于多语言翻译、低资源语言翻译以及翻译模型评估的学术论文,为后续研究提供了丰富的参考和启发。
以上内容由遇见数据集搜集并总结生成


