OneFly7/llama2-sst2-fine-tuning
收藏Hugging Face2023-08-08 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/OneFly7/llama2-sst2-fine-tuning
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: label_text
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 23202578
num_examples: 67349
- name: validation
num_bytes: 334716
num_examples: 872
download_size: 4418625
dataset_size: 23537294
task_categories:
- text-classification
language:
- en
---
# Dataset Card for "llama2-sst2-finetuning"
## Dataset Description
The Llama2-sst2-fine-tuning dataset is designed for supervised fine-tuning of the LLaMA V2 based on the GLUE SST2 for sentiment analysis classification task.
We provide two subsets: training and validation.
To ensure the effectiveness of fine-tuning, we convert the data into the prompt template for LLaMA V2 supervised fine-tuning, where the data will follow this format:
```
<s>[INST] <<SYS>>
{System prompt}
<</SYS>>
{User prompt} [/INST] {Label} </s>.
```
The feasibility of this dataset has been tested in supervised fine-tuning on the meta-llama/Llama-2-7b-hf model.
Note. For the sake of simplicity, we have retained only one new column of data ('text').
## Other Useful Links
- [Get Llama 2 Prompt Format Right](https://www.reddit.com/r/LocalLLaMA/comments/155po2p/get_llama_2_prompt_format_right/)
- [Fine-Tune Your Own Llama 2 Model in a Colab Notebook](https://towardsdatascience.com/fine-tune-your-own-llama-2-model-in-a-colab-notebook-df9823a04a32)
- [Instruction fine-tuning Llama 2 with PEFT’s QLoRa method](https://medium.com/@ud.chandra/instruction-fine-tuning-llama-2-with-pefts-qlora-method-d6a801ebb19)
- [GLUE SST2 Dataset](https://www.tensorflow.org/datasets/catalog/glue#gluesst2)
<!--[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)-->
---
数据集信息:
特征:
- 名称:label_text,数据类型:字符串
- 名称:text,数据类型:字符串
划分集:
- 名称:训练集,字节数:23202578,样本数:67349
- 名称:验证集,字节数:334716,样本数:872
下载大小:4418625,数据集总大小:23537294
任务类别:文本分类
语言:英语
---
# 「llama2-sst2-finetuning」数据集卡片
## 数据集说明
本llama2-sst2微调数据集旨在基于GLUE SST2情感分析分类任务,对LLaMA V2进行监督微调。
我们提供两个子集:训练集与验证集。
为保障微调效果,我们将数据转换为适配LLaMA V2监督微调的提示词模板,数据格式如下:
<s>[INST] <<SYS>>
{系统提示词}
<</SYS>>
{用户提示词} [/INST] {标签} </s>.
本数据集的可行性已在meta-llama/Llama-2-7b-hf模型的监督微调任务中得到验证。
注意:为简化操作,我们仅保留了一个新增数据列('text')。
## 其他实用链接
- [正确配置Llama 2提示词格式](https://www.reddit.com/r/LocalLLaMA/comments/155po2p/get_llama_2_prompt_format_right/)
- [在Colab笔记本中自定义微调Llama 2模型](https://towardsdatascience.com/fine-tune-your-own-llama-2-model-in-a-colab-notebook-df9823a04a32)
- [使用PEFT的QLoRA方法对Llama 2进行指令微调](https://medium.com/@ud.chandra/instruction-fine-tuning-llama-2-with-pefts-qlora-method-d6a801ebb19)
- [GLUE SST2数据集](https://www.tensorflow.org/datasets/catalog/glue#gluesst2)
<!--[需补充更多信息](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)-->
提供机构:
OneFly7
原始信息汇总
数据集卡片 "llama2-sst2-finetuning"
数据集描述
Llama2-sst2-fine-tuning 数据集旨在基于 GLUE SST2 进行情感分析分类任务的 LLaMA V2 监督微调。
我们提供两个子集:训练集和验证集。
为了确保微调的有效性,我们将数据转换为 LLaMA V2 监督微调的提示模板,数据将遵循以下格式:
<s>[INST] <<SYS>>
{System prompt}
<</SYS>>
{User prompt} [/INST] {Label} </s>.
该数据集的可行性已在 meta-llama/Llama-2-7b-hf 模型上进行监督微调测试。
注意:为了简化,我们仅保留了一个新数据列(text)。
数据集信息
- 特征:
- name: label_text dtype: string
- name: text dtype: string
- 拆分:
- name: train num_bytes: 23202578 num_examples: 67349
- name: validation num_bytes: 334716 num_examples: 872
- 下载大小:4418625
- 数据集大小:23537294
- 任务类别:text-classification
- 语言:en
搜集汇总
数据集介绍
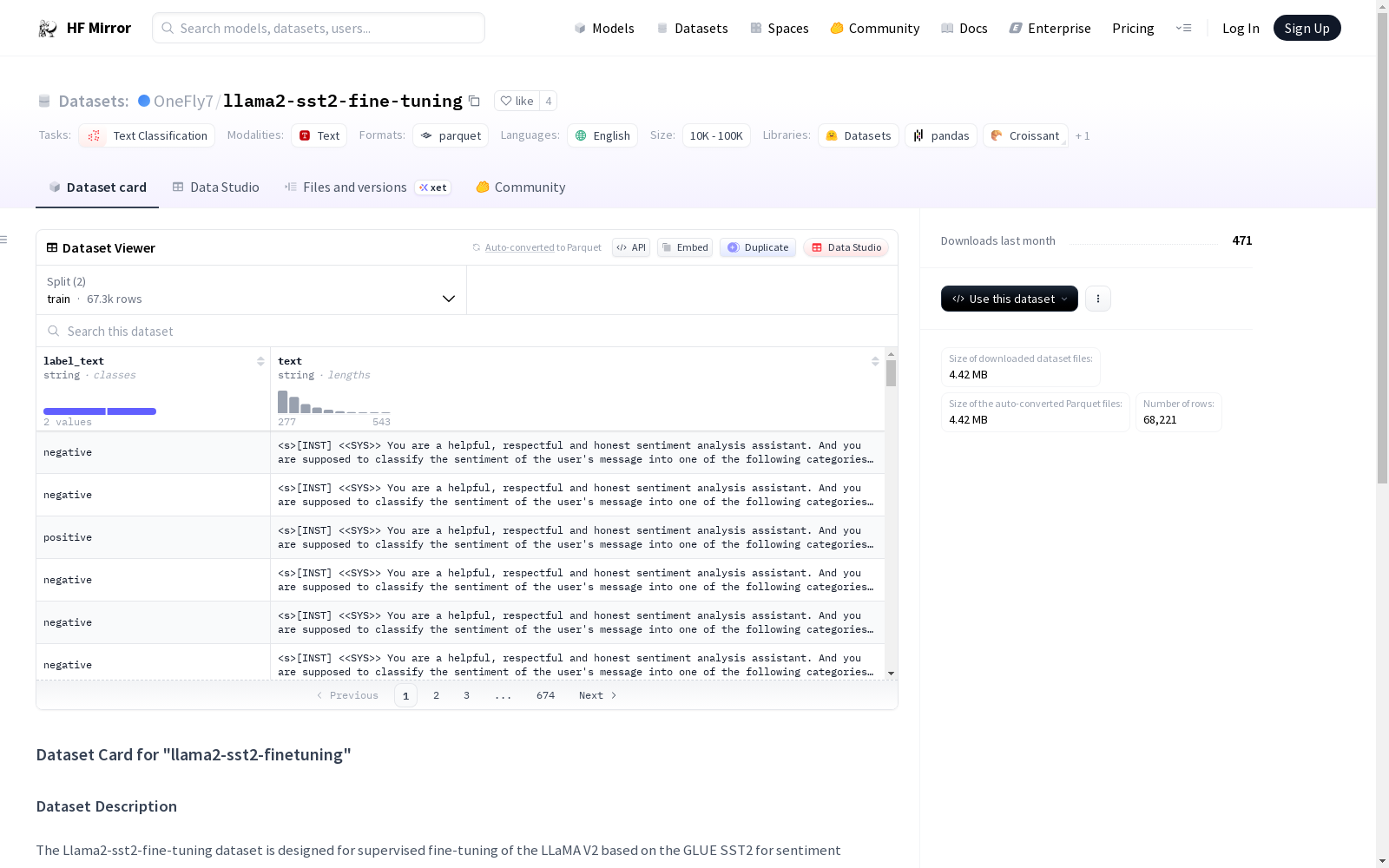
构建方式
在自然语言处理领域,情感分析任务常依赖于高质量标注数据集。本数据集基于GLUE SST2情感分析数据集构建,专为LLaMA V2模型的监督微调而设计。构建过程中,原始数据被转化为符合LLaMA V2提示模板的结构化格式,采用特定指令模板封装文本与标签,确保模型能有效学习情感分类任务。数据集包含训练与验证两个子集,总计超过六万八千条样本,每条样本均包含文本内容及对应情感标签文本,为模型微调提供了标准化输入。
特点
该数据集的核心特点在于其针对大语言模型微调的优化设计。所有数据均严格遵循LLaMA V2的指令微调格式,将系统提示、用户输入与标签整合为统一序列,降低了模型适配的复杂性。数据集专注于二分类情感分析任务,标签以自然语言形式呈现,增强了模型的可解释性。其结构简洁,仅保留文本与标签文本两列,避免了冗余信息干扰,同时确保了与原始SST2数据集的情感标注一致性,为模型性能评估提供了可靠基准。
使用方法
使用本数据集时,研究者可直接将其应用于LLaMA V2系列模型的监督微调流程。数据已预处理为模型可接受的指令格式,用户无需额外进行模板转换。典型用法包括加载训练集进行模型参数优化,并利用验证集监控训练过程与评估性能。该数据集兼容主流深度学习框架,如Hugging Face Transformers库,支持结合参数高效微调技术(如QLoRA)进行资源受限环境下的模型训练,为情感分析领域的模型定制化研究提供了便捷起点。
背景与挑战
背景概述
在自然语言处理领域,情感分析作为文本分类的重要分支,长期以来依赖于高质量标注数据集以驱动模型性能提升。GLUE SST-2数据集作为经典基准,自2018年由纽约大学等机构发布以来,为情感二分类任务提供了标准评估框架。OneFly7/llama2-sst2-fine-tuning数据集在此基础上,由研究团队于2023年构建,专为LLaMA V2大语言模型的监督微调而设计。该数据集通过重构SST-2的原始标注,将其转化为符合LLaMA V2指令微调格式的提示模板,旨在探索大模型在特定下游任务上的适配能力,为开源大模型的高效轻量化部署提供了实践范例。
当前挑战
情感分析任务面临的核心挑战在于文本语义的复杂性与语境依赖性,例如讽刺、双重否定等语言现象易导致模型误判。SST-2数据集虽标注规范,但其短文本特性与有限领域覆盖可能制约模型泛化能力。在数据集构建过程中,研究者需解决提示模板设计的适配难题:如何将传统分类标签转化为符合LLaMA V2指令格式的结构化文本,同时保持原始语义完整性。此外,数据转换需平衡模板标准化与计算效率,避免因格式冗余增加模型训练负担,这对微调效果的优化提出了技术性要求。
常用场景
经典使用场景
在自然语言处理领域,情感分析作为文本分类的核心任务之一,长期依赖于高质量标注数据进行模型训练。该数据集专为LLaMA V2模型在SST-2情感分析任务上的监督微调而设计,通过将原始数据转换为符合LLaMA V2提示模板的结构化格式,为大规模语言模型提供了标准化的指令微调范例。其经典使用场景集中于学术研究中的模型性能评估,研究者可借助该数据集验证微调策略的有效性,探索提示工程对模型理解能力的影响,从而推动指令跟随模型在细粒度情感判别任务上的精度提升。
解决学术问题
该数据集有效解决了大语言模型在特定领域适应性的关键学术问题。传统预训练模型虽具备通用语言理解能力,却在专业情感分类任务上存在性能瓶颈。通过提供格式统一的指令微调数据,该数据集使研究者能够系统探究监督微调对模型参数更新的影响机制,验证提示模板设计对任务表现的调节作用。其意义在于建立了从通用语言模型到领域专用模型的转化范式,为后续研究提供了可复现的基准框架,显著降低了领域自适应研究的实验门槛。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在高效微调方法的创新上。研究者们基于其标准化格式,开发了包括QLoRA在内的参数高效微调技术,在保持模型性能的同时大幅降低计算资源消耗。相关研究进一步探索了多任务提示集成、动态模板优化等方向,推动了指令微调理论的发展。这些工作共同构建了从基础微调实验到先进优化算法的完整研究脉络,为后续基于LLaMA架构的领域自适应研究奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


