tinyBenchmarks/tinyMMLU
收藏Hugging Face2024-07-08 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/tinyBenchmarks/tinyMMLU
下载链接
链接失效反馈官方服务:
资源简介:
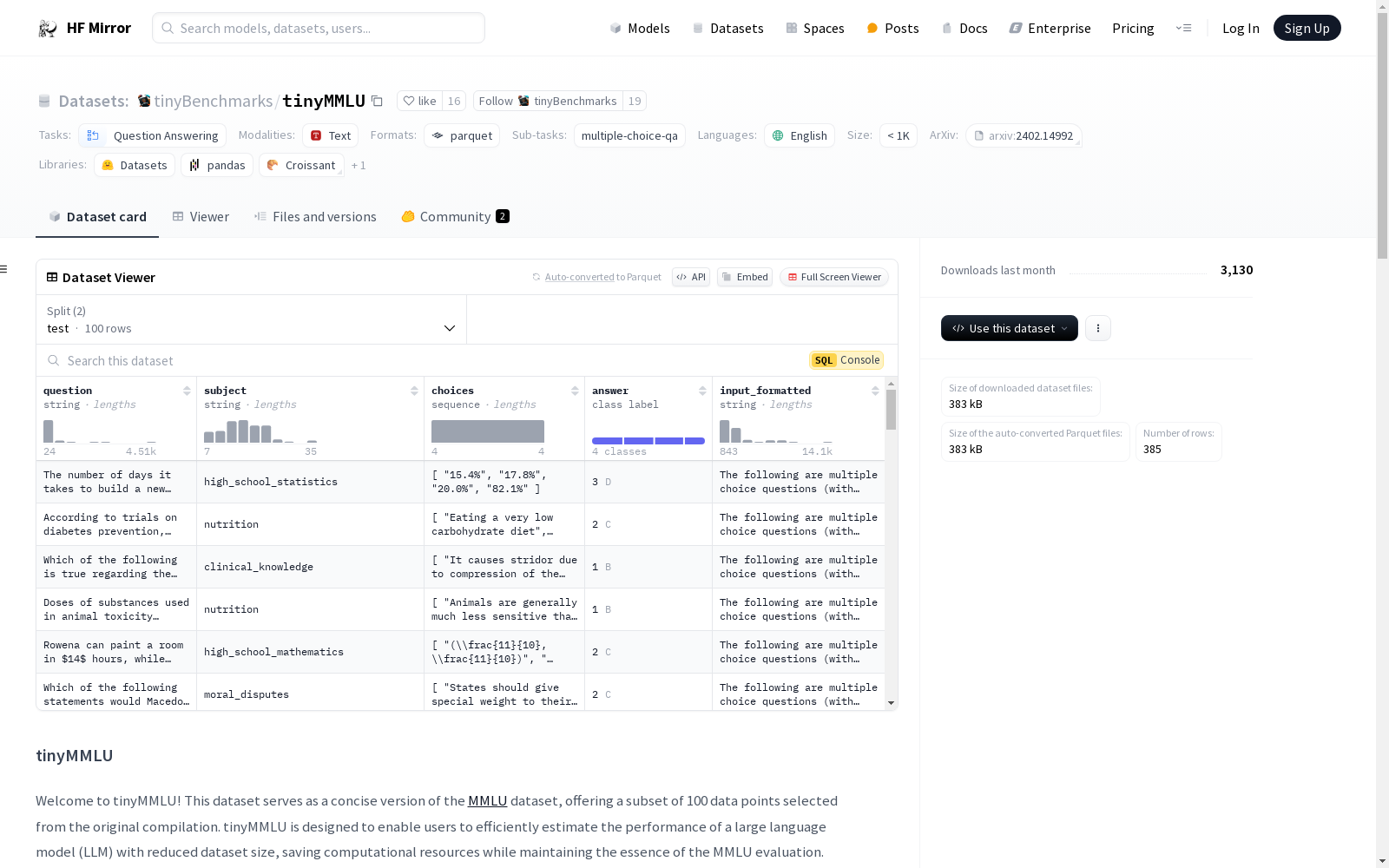
tinyMMLU是MMLU数据集的一个精简版本,包含100个数据点,旨在减少计算资源的同时保持MMLU评估的核心。该数据集支持使用lm evaluation harness进行评估,也可以集成到自定义的评估流程中。数据集包含问题、主题、选项和答案等特征,并提供了预格式化的数据点,便于用户快速评估大型语言模型的性能。
tinyMMLU is a concise version of the MMLU dataset, offering a subset of 100 data points selected from the original compilation. It is designed to enable users to efficiently estimate the performance of a large language model (LLM) with reduced dataset size, saving computational resources while maintaining the essence of the MMLU evaluation. The dataset supports evaluation using the lm evaluation harness and can be integrated into custom pipelines. It includes features such as questions, subjects, choices, and answers, along with preformatted data points for streamlined benchmarking.
提供机构:
tinyBenchmarks
原始信息汇总
tinyMMLU 数据集概述
基本信息
- 数据集名称: tinyMMLU
- 语言: 英语(en)
- 多语言性: 单语种(monolingual)
- 任务类别: 问答(question-answering)
- 任务ID: 多项选择问答(multiple-choice-qa)
- 源数据集: cais/mmlu
配置信息
配置: all
- 特征:
question: 字符串subject: 字符串choices: 字符串序列answer: 类别标签,选项为 A, B, C, Dinput_formatted: 字符串
- 分割:
test: 100 个样本,337628 字节validation: 1531 个样本,5425300 字节dev: 285 个样本,858526 字节
- 下载大小: 1661908 字节
- 数据集大小: 6621454 字节
配置: default
- 特征:
question: 字符串subject: 字符串choices: 字符串序列answer: 类别标签,选项为 A, B, C, D, Einput_formatted: 字符串
- 分割:
test: 100 个样本,340095 字节
- 下载大小: 178082 字节
- 数据集大小: 340095 字节
数据文件
配置: all
- 数据文件:
test: all/test-*validation: all/validation-*dev: all/dev-*
配置: default
- 数据文件:
test: data/test-*
语言标识
- 语言 BCP47: en-US
搜集汇总
数据集介绍
构建方式
tinyMMLU数据集是从原始MMLU数据集中精选出的100个数据点构成的精简版本,旨在通过减少数据集规模来高效评估大型语言模型的性能。该数据集的构建过程由专家团队完成,确保了数据的高质量和代表性。通过这种方式,tinyMMLU在保持MMLU评估核心要素的同时,显著降低了计算资源的消耗。
特点
tinyMMLU数据集以其紧凑性和高效性著称,仅包含100个数据点,能够快速评估大型语言模型的性能。该数据集兼容lm evaluation harness工具,并支持自定义评估流程。此外,tinyMMLU保留了原始MMLU数据集的多项选择题形式,涵盖了广泛的主题,确保了评估的全面性和准确性。
使用方法
用户可以通过lm evaluation harness工具直接评估模型,使用`--tasks=tinyMMLU`参数即可。此外,tinyMMLU数据集也可以通过`load_dataset`函数加载,并集成到自定义评估流程中。用户还可以使用tinyBenchmarks库进行性能评估,通过简单的代码片段即可完成模型的性能估计。详细的评估指南和代码示例可在lm evaluation harness和tinyBenchmarks GitHub页面找到。
背景与挑战
背景概述
tinyMMLU数据集是MMLU(Massive Multitask Language Understanding)数据集的一个精简版本,由Felipe Maia Polo等研究人员于2024年发布。该数据集旨在通过提供100个精选数据点,帮助用户高效评估大型语言模型(LLM)的性能,同时减少计算资源的消耗。MMLU数据集最初由Dan Hendrycks等人于2021年提出,旨在衡量模型在多任务语言理解中的表现。tinyMMLU继承了MMLU的核心特性,专注于多项选择题形式的问答任务,涵盖了广泛的学科领域。这一数据集的推出为研究人员提供了一个快速验证模型性能的工具,推动了自然语言处理领域的模型评估效率。
当前挑战
tinyMMLU数据集在构建和应用过程中面临多重挑战。首先,如何在有限的样本中保持原始MMLU数据集的多样性和代表性是一个关键问题。尽管tinyMMLU通过精选数据点保留了核心任务特性,但样本量的减少可能导致评估结果的偏差,尤其是在模型泛化能力的测试中。其次,数据集的构建需要确保每个数据点的质量和准确性,以避免引入噪声或错误标签,这对专家生成的数据提出了高要求。此外,tinyMMLU的评估依赖于特定的工具链,如lm-evaluation-harness,这对不熟悉该工具的用户可能构成技术门槛。最后,如何在多GPU环境下保持评估结果的一致性也是一个需要解决的难题,因为输出顺序的变化可能影响最终的性能估计。
常用场景
经典使用场景
tinyMMLU数据集作为MMLU数据集的精简版本,主要用于快速评估大型语言模型(LLM)的性能。通过仅包含100个数据点,该数据集能够在保持MMLU评估核心内容的同时,显著减少计算资源的消耗。研究人员和开发者可以利用tinyMMLU在短时间内对模型进行初步评估,从而为后续的深入研究和优化提供参考。
解决学术问题
tinyMMLU解决了在资源有限的情况下评估大型语言模型的难题。传统的MMLU数据集规模庞大,评估过程耗时且计算成本高。tinyMMLU通过精选的100个数据点,提供了一个高效且可靠的评估基准,使得研究人员能够在资源受限的环境中,依然能够对模型的性能进行准确的估计。这一创新不仅降低了研究门槛,还推动了语言模型评估方法的普及和发展。
衍生相关工作
tinyMMLU的推出催生了一系列相关研究和工作。例如,基于tinyMMLU的评估结果,研究人员开发了更高效的模型优化算法,进一步提升了语言模型的性能。此外,tinyMMLU还被用于多个开源项目,如lm-evaluation-harness,推动了语言模型评估工具的标准化和普及。这些衍生工作不仅丰富了tinyMMLU的应用场景,也为语言模型领域的研究提供了新的思路和方向。
以上内容由遇见数据集搜集并总结生成


