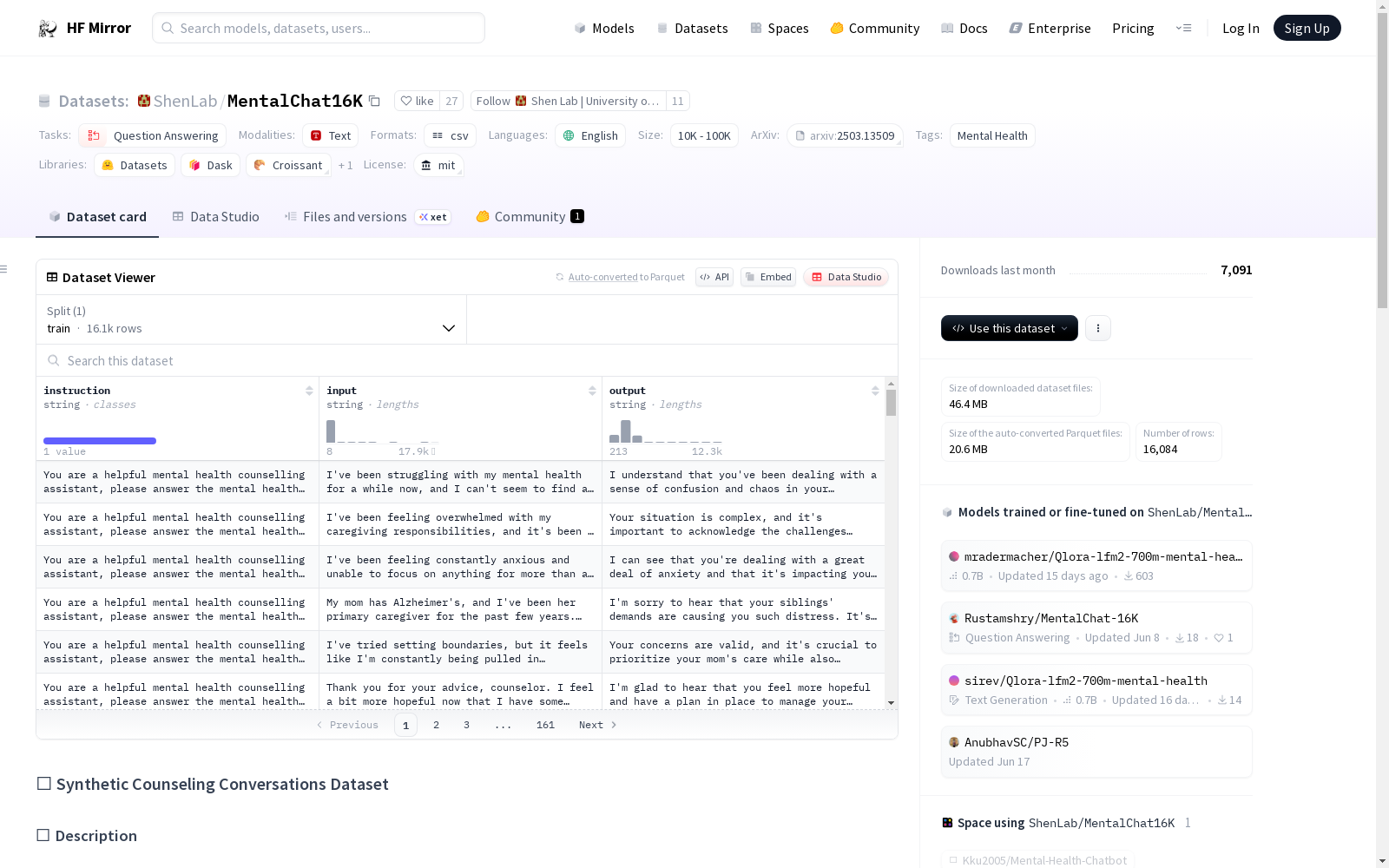
ShenLab/MentalChat16K
收藏🗣️ Synthetic Counseling Conversations Dataset
📝 描述
该数据集包含9,775个合成的心理咨询师与客户之间的对话,涵盖33个心理健康主题,如💑关系、😟焦虑、😔抑郁、🤗亲密关系和👨👩👧👦家庭冲突。对话使用OpenAI GPT-3.5 Turbo模型和定制的Airoboros自我生成框架生成。
Airoboros框架用于创建新的提示,提供生成患者查询的明确指令。这些查询随后被反馈到GPT-3.5 Turbo模型中,生成相应的响应。提示中指定了每个主题的比例,以确保合成对话真实地模拟人类心理咨询师与客户交互的复杂性和多样性。
该数据集旨在使语言模型接触广泛的心理状况和治疗策略,从而能够进行更真实和有效的心理咨询对话。🧠
📊 数据集特征
- 对话数量: 9,775 🗣️
- 涵盖主题: 💑关系、😟焦虑、😔抑郁、🤗亲密关系、👨👩👧👦家庭冲突及其他28个心理健康主题
- 语言: 英语 🇺🇸
- 生成方法: OpenAI GPT-3.5 Turbo模型与定制的Airoboros自我生成框架
🤖 数据集用途
该数据集可用于训练和评估用于心理咨询和心理健康应用的语言模型,如聊天机器人、虚拟助手和对话系统。它提供了一系列多样化和真实的对话场景,有助于提高模型对心理状况和治疗策略的理解。
🌍 数据集限制
该数据集完全是合成的,可能无法完全捕捉现实世界心理咨询对话的细微差别和复杂性。此外,数据集仅限于英语对话,可能不代表多样化的文化和语言背景。
📚 引用
如果您在研究中使用MentalChat16K,请按以下方式引用该数据集:
@dataset{MentalChat16K, author = {Jia Xu, Tianyi Wei, Bojian Hou, Patryk Orzechowski, Shu Yang, Ruochen Jin, Rachael Paulbeck, Joost Wagenaar, George Demiris, Li Shen}, title = {MentalChat16K: A Benchmark Dataset for Conversational Mental Health Assistance}, year = {2024}, url = {https://huggingface.co/datasets/ShenLab/MentalChat16K}, }