---
license: other
license_name: other
license_link: LICENSE
language:
- fr
multilinguality:
- monolingual
source_datasets:
- https://huggingface.co/datasets/race
pretty_name: RACE_fr
size_categories:
- 10K<n<100K
task_categories:
- multiple-choice
task_ids:
- multiple-choice-qa
---
# Dataset Card for "race_all_fr"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Original Dataset Homepage](http://www.cs.cmu.edu/~glai1/data/race/)
- **Repository:** [Translated Dataset on Hugging Face](https://huggingface.co/datasets/race_all_fr)
- **Paper:** [Original Dataset Paper](https://arxiv.org/abs/1704.04683)
- **Leaderboard:** [Original Dataset Leaderboard](https://paperswithcode.com/dataset/race)
### Dataset Summary
`race_all_fr` est la version française du dataset [RACE](https://huggingface.co/datasets/race), un large dataset de compréhension de lecture comprenant plus de 28 000 passages et près de 100 000 questions. Le dataset original, conçu pour les étudiants des écoles secondaires et des collèges en Chine, a été traduit en français pour étendre son accessibilité et permettre des recherches en compréhension de lecture dans d'autres langues.
### Supported Tasks and Leaderboards
Les tâches et classements supportés restent identiques à ceux du dataset original RACE, adaptés pour la langue française.
### Languages
Le dataset est entièrement en français.
## Dataset Structure
### Data Instances
Les instances de données sont structurées de manière identique à celles du dataset original RACE, mais traduites en français.
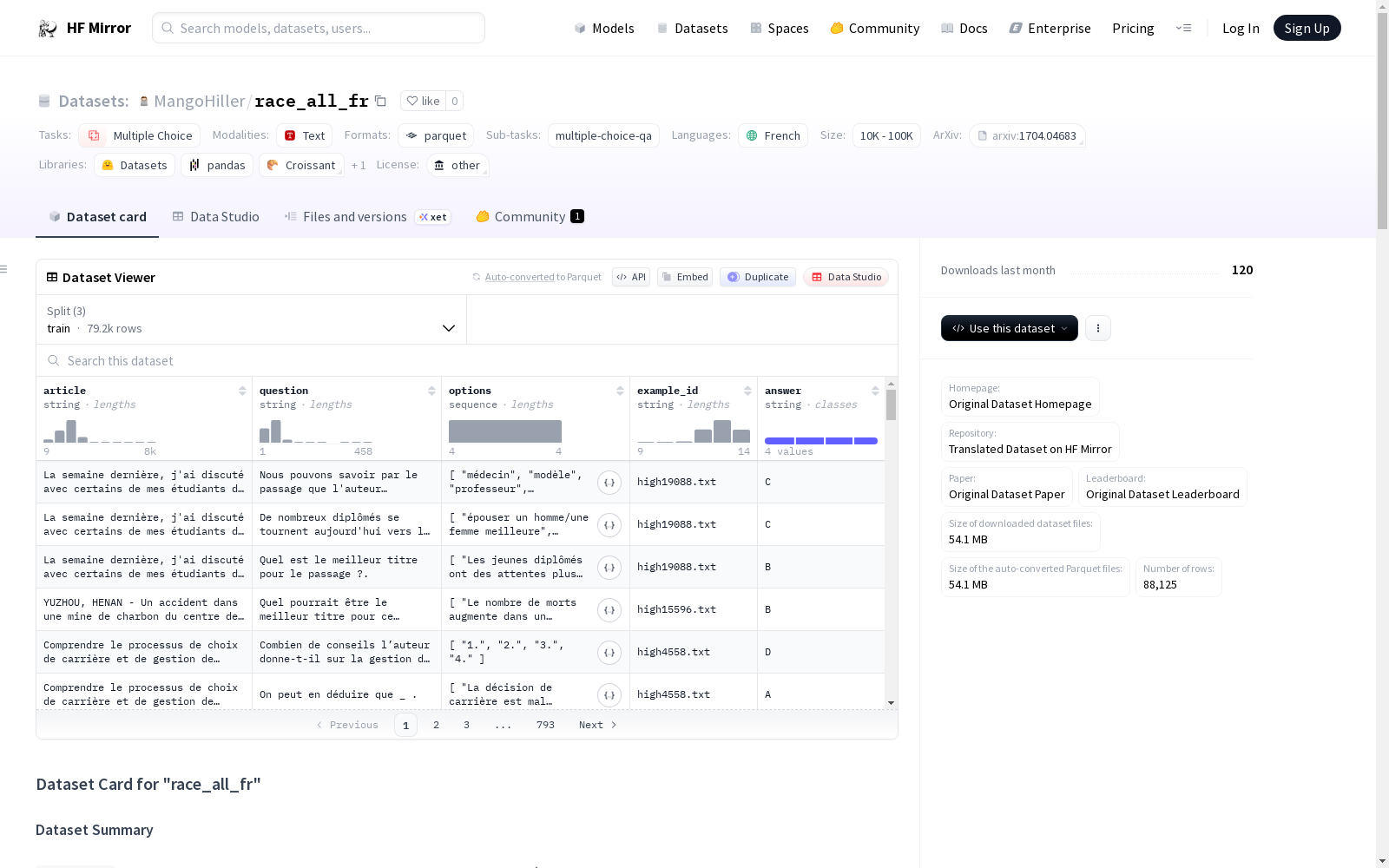
### Data Fields
- `example_id`: un identifiant unique pour chaque exemple.
- `article`: le texte de l'article sur lequel se base les questions.
- `question`: la question posée.
- `options`: les quatre options de réponse fournies, où seulement une est correcte.
- `answer`: la lettre correspondant à la réponse correcte parmi les options.
### Data Splits
La répartition des données (train/validation/test) est la même que celle du dataset RACE original.
## Dataset Creation
### Curation Rationale
Ce dataset a été créé pour étendre les ressources disponibles pour la recherche en traitement automatique des langues (TAL) en français, spécifiquement pour la compréhension de la lecture.
### Source Data
#### Initial Data Collection and Normalization
Les données sources sont identiques à celles du dataset RACE, mais ont été traduites en français.
### Annotations
Les annotations restent inchangées par rapport à l'original, à l'exception de la langue.
### Personal and Sensitive Information
Les considérations sont les mêmes que pour le dataset RACE original.
## Considerations for Using the Data
### Social Impact of Dataset
La traduction de datasets en différentes langues est cruciale pour rendre la recherche en TAL accessible plus largement et pour permettre l'entraînement de modèles multilingues.
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
Dataset traduit à l'aide de [Large_dataset_translator](https://github.com/vTuanpham/Large_dataset_translator) et l'API Google Translate.
### Licensing Information
Les mêmes licences que le dataset RACE original s'appliquent. Veuillez consulter le [lien suivant](http://www.cs.cmu.edu/~glai1/data/race/) pour plus d'informations.
### Citation Information
Veuillez citer le papier original du dataset RACE lors de l'utilisation de `race_all_fr` :
```bibtex
@inproceedings{lai-etal-2017-race,
title = "{RACE}: Large-scale {R}e{A}ding Comprehension Dataset From Examinations",
author = "Lai, Guokun and
Xie, Qizhe and
Liu, Hanxiao and
Yang, Yiming and
Hovy, Eduard",
booktitle = "Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing",
month = sep,
year = "2017",
address = "Copenhagen, Denmark",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D17-1082",
doi = "10.18653/v1/D17-1082",
pages = "785--794",
}
```
### Contributions
La traduction de ce dataset a été réalisée par [@MangoHiller](https://huggingface.co/MangoHiller). Pour les contributions originales, veuillez vous référer au dépôt GitHub du dataset RACE : [https://github.com/qizhex/RACE_AR_baselines](https://github.com/qizhex/RACE_AR_baselines).
---
license: 其他
license_name: 其他
license_link: LICENSE
language:
- 法语(fr)
multilinguality:
- 单语言
source_datasets:
- https://huggingface.co/datasets/race
pretty_name: RACE_fr
size_categories:
- 10K<n<100K
task_categories:
- 多项选择
task_ids:
- 多项选择问答
---
# 「race_all_fr」数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建初衷](#curation-rationale)
- [源数据](#source-data)
- [标注信息](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献](#contributions)
## 数据集描述
- **主页:** [原始数据集主页](http://www.cs.cmu.edu/~glai1/data/race/)
- **代码仓库:** [Hugging Face上的翻译数据集](https://huggingface.co/datasets/race_all_fr)
- **论文:** [原始数据集论文](https://arxiv.org/abs/1704.04683)
- **排行榜:** [原始数据集排行榜](https://paperswithcode.com/dataset/race)
### 数据集摘要
`race_all_fr` 是数据集[RACE](https://huggingface.co/datasets/race)的法语版本,这是一个大型阅读理解数据集,包含超过28000篇文章和近100000道题目。原始数据集专为中国初高中学生设计,现已被翻译成法语,以提升其可访问性,并推动其他语言的阅读理解研究。
### 支持任务与排行榜
所支持的任务与排行榜与原始RACE数据集一致,仅适配法语语言环境。
### 语言
本数据集全部采用法语。
## 数据集结构
### 数据实例
数据实例的结构与原始RACE数据集完全一致,仅内容已被译为法语。
### 数据字段
- `example_id`:每个数据实例的唯一标识符。
- `article`:作为问题依据的文章文本。
- `question`:提出的问题。
- `options`:提供的四个候选答案,其中仅有一个为正确答案。
- `answer`:候选答案中对应正确答案的字母标识。
### 数据划分
数据集的划分(训练集/验证集/测试集)与原始RACE数据集完全一致。
## 数据集构建
### 构建初衷
本数据集的构建旨在扩充法语自动语言处理(Traitement Automatique des Langues, TAL)领域,尤其是阅读理解方向的可用研究资源。
### 源数据
#### 初始数据收集与标准化
源数据与原始RACE数据集完全一致,仅内容已被译为法语。
### 标注信息
除语言外,标注信息与原始数据集完全一致。
### 个人与敏感信息
相关注意事项与原始RACE数据集一致。
## 数据集使用注意事项
### 数据集的社会影响
将数据集翻译为多种语言,对于扩大自动语言处理(Traitement Automatique des Langues, TAL)研究的覆盖范围,以及支持多语言模型的训练均至关重要。
### 偏差讨论
[需补充更多信息]
### 其他已知局限性
[需补充更多信息]
## 附加信息
本数据集通过[Large_dataset_translator](https://github.com/vTuanpham/Large_dataset_translator)与谷歌翻译API完成翻译。
### 许可信息
本数据集适用与原始RACE数据集相同的许可协议。如需了解更多信息,请参阅[此链接](http://www.cs.cmu.edu/~glai1/data/race/)。
### 引用信息
使用`race_all_fr`数据集时,请引用原始RACE数据集的论文:
bibtex
@inproceedings{lai-etal-2017-race,
title = "{RACE}: Large-scale {R}e{A}ding Comprehension Dataset From Examinations",
author = "Lai, Guokun and
Xie, Qizhe and
Liu, Hanxiao and
Yang, Yiming and
Hovy, Eduard",
booktitle = "Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing",
month = sep,
year = "2017",
address = "Copenhagen, Denmark",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D17-1082",
doi = "10.18653/v1/D17-1082",
pages = "785--794",
}
### 贡献
本数据集的翻译工作由[@MangoHiller](https://huggingface.co/MangoHiller)完成。如需了解原始数据集的贡献信息,请参阅RACE数据集的GitHub仓库:[https://github.com/qizhex/RACE_AR_baselines](https://github.com/qizhex/RACE_AR_baselines)。