semeru/code-code-DefectDetection
收藏Hugging Face2023-03-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/semeru/code-code-DefectDetection
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
Programminglanguage: "C"
version: "N/A"
Date: "Devign(Jun 2019 - paper release date)"
Contaminated: "Very Likely"
Size: "Standard Tokenizer"
---
### Dataset is imported from CodeXGLUE and pre-processed using their script.
# Where to find in Semeru:
The dataset can be found at /nfs/semeru/semeru_datasets/code_xglue/code-to-code/Defect-detection in Semeru
# CodeXGLUE -- Defect Detection
## Task Definition
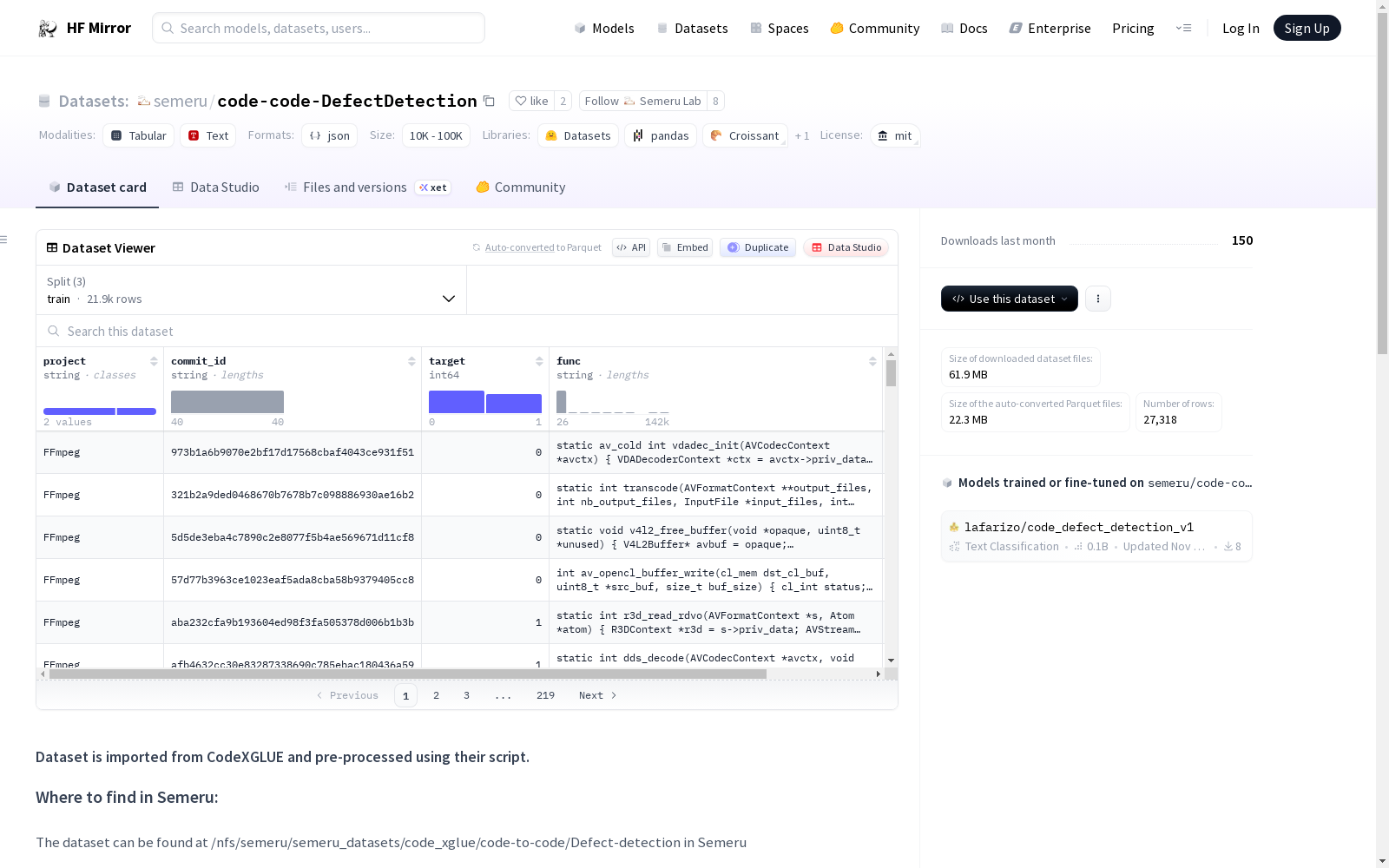
Given a source code, the task is to identify whether it is an insecure code that may attack software systems, such as resource leaks, use-after-free vulnerabilities and DoS attack. We treat the task as binary classification (0/1), where 1 stands for insecure code and 0 for secure code.
### Dataset
The dataset we use comes from the paper [*Devign*: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks](http://papers.nips.cc/paper/9209-devign-effective-vulnerability-identification-by-learning-comprehensive-program-semantics-via-graph-neural-networks.pdf). We combine all projects and split 80%/10%/10% for training/dev/test.
### Data Format
Three pre-processed .jsonl files, i.e. train.jsonl, valid.jsonl, test.jsonl are present
For each file, each line in the uncompressed file represents one function. One row is illustrated below.
- **func:** the source code
- **target:** 0 or 1 (vulnerability or not)
- **idx:** the index of example
### Data Statistics
Data statistics of the dataset are shown in the below table:
| | #Examples |
| ----- | :-------: |
| Train | 21,854 |
| Dev | 2,732 |
| Test | 2,732 |
## Reference
<pre><code>@inproceedings{zhou2019devign,
title={Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks},
author={Zhou, Yaqin and Liu, Shangqing and Siow, Jingkai and Du, Xiaoning and Liu, Yang},
booktitle={Advances in Neural Information Processing Systems},
pages={10197--10207},
year={2019}
}</code></pre>
许可证:MIT许可证
编程语言:C语言
版本:无可用
日期:Devign论文发布日期(2019年6月)
数据污染情况:极有可能存在污染
数据集处理:采用标准分词器
本数据集源自CodeXGLUE,并采用其官方脚本完成预处理。
# 在Semeru中的存储位置
该数据集在Semeru中的存储路径为:/nfs/semeru/semeru_datasets/code_xglue/code-to-code/Defect-detection
# CodeXGLUE——缺陷检测任务
## 任务定义
给定一段源代码,本任务旨在识别其是否为可能攻击软件系统的不安全代码,例如资源泄漏、使用后释放(use-after-free)漏洞以及拒绝服务(Denial of Service, DoS)攻击。本任务被视为二分类任务(0/1),其中1代表不安全代码,0代表安全代码。
### 数据集
本数据集源自论文《Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks》,链接为:http://papers.nips.cc/paper/9209-devign-effective-vulnerability-identification-by-learning-comprehensive-program-semantics-via-graph-neural-networks.pdf。我们将所有项目的样本整合,并按照80%/10%/10%的比例划分为训练集、开发集与测试集。
### 数据格式
数据集包含三个预处理后的.jsonl文件,即train.jsonl、valid.jsonl与test.jsonl。
对于每个文件,解压后每一行对应一个函数。以下展示一行示例的结构:
- **func**:源代码内容
- **target**:0或1(分别代表存在漏洞或不存在漏洞)
- **idx**:样本索引
### 数据统计
数据集的统计信息如下表所示:
| 数据集划分 | 样本数量 |
| :-------: | :-------: |
| 训练集 | 21,854 |
| 开发集 | 2,732 |
| 测试集 | 2,732 |
## 参考文献
<pre><code>@inproceedings{zhou2019devign,
title={Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks},
author={Zhou, Yaqin and Liu, Shangqing and Siow, Jingkai and Du, Xiaoning and Liu, Yang},
booktitle={Advances in Neural Information Processing Systems},
pages={10197--10207},
year={2019}
}</code></pre>
提供机构:
semeru
原始信息汇总
CodeXGLUE -- Defect Detection 数据集
任务定义
给定一个源代码,任务是识别它是否是不安全的代码,可能攻击软件系统,如资源泄漏、使用后释放漏洞和拒绝服务攻击。任务被视为二元分类(0/1),其中1表示不安全代码,0表示安全代码。
数据集
数据集来自论文 Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks。我们将所有项目合并,并按80%/10%/10%的比例分为训练集、开发集和测试集。
数据格式
包含三个预处理的.jsonl文件,即train.jsonl、valid.jsonl和test.jsonl。
每个文件中,每一行代表一个函数。每行包含以下字段:
- func: 源代码
- target: 0或1(是否存在漏洞)
- idx: 示例的索引
数据统计
数据集的统计信息如下表所示:
| #Examples | |
|---|---|
| Train | 21,854 |
| Dev | 2,732 |
| Test | 2,732 |
参考文献
@inproceedings{zhou2019devign, title={Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks}, author={Zhou, Yaqin and Liu, Shangqing and Siow, Jingkai and Du, Xiaoning and Liu, Yang}, booktitle={Advances in Neural Information Processing Systems}, pages={10197--10207}, year={2019} }
搜集汇总
数据集介绍
构建方式
在软件安全分析领域,漏洞检测数据集对于训练高效模型至关重要。本数据集源自Devign研究项目,通过整合多个真实世界C语言项目的源代码构建而成。原始数据经过系统化收集与标注,将每个函数样本标记为安全或存在漏洞两类。随后采用CodeXGLUE框架提供的脚本进行标准化预处理,确保数据格式统一。最终按照80%、10%、10%的比例划分为训练集、验证集和测试集,形成结构化的机器学习数据集。
使用方法
使用者可直接加载预分割的JSONL文件进行模型训练与评估。典型流程包括解析‘func’字段获取源代码,依据‘target’字段构建监督信号。在机器学习应用中,常需结合代码表征技术如抽象语法树或图神经网络提取特征。验证集与测试集分别用于超参数调优与最终性能度量。该数据集兼容主流深度学习框架,支持端到端的漏洞检测模型开发与对比实验。
背景与挑战
背景概述
在软件安全领域,代码缺陷检测是保障系统可靠性的关键环节。semeru/code-code-DefectDetection数据集源自2019年发布的Devign研究,由周亚琴等学者在神经信息处理系统大会上提出,其核心目标是通过图神经网络学习全面的程序语义,以识别C语言代码中的安全漏洞,如资源泄漏、释放后使用等攻击模式。该数据集整合了多个项目的代码样本,划分为训练、验证和测试子集,为自动化漏洞检测提供了标准化基准,推动了软件工程与人工智能的交叉研究,显著提升了代码安全分析的效率与精度。
当前挑战
该数据集旨在解决代码缺陷检测中的二元分类挑战,即区分安全代码与不安全代码,这要求模型能深入理解复杂的程序结构和语义逻辑。构建过程中,研究人员面临数据标注的准确性难题,因为漏洞判定依赖专家知识,且代码样本来自不同项目,需统一处理以消除噪声。此外,数据集的规模相对有限,可能影响模型泛化能力,而代码的多样性和漏洞的隐蔽性进一步增加了学习难度,要求算法具备更强的表征能力。
常用场景
经典使用场景
在软件安全与代码分析领域,semeru/code-code-DefectDetection数据集为研究者提供了一个标准化的基准平台,用于训练和评估缺陷检测模型。该数据集通过将C语言源代码表示为函数级样本,并标注其是否包含安全漏洞,如资源泄漏或拒绝服务攻击风险,使得机器学习模型能够学习代码的语义特征。经典使用场景涉及利用图神经网络等先进技术,对代码进行图结构建模,从而识别潜在的脆弱性模式,推动自动化漏洞检测技术的发展。
解决学术问题
该数据集有效解决了软件工程中自动化漏洞识别的核心学术问题,即如何从复杂代码语义中精准检测安全缺陷。传统方法依赖人工审计或静态分析工具,往往效率低下且覆盖不全。通过提供大规模标注数据,它支持数据驱动的方法,帮助研究者探索代码表征学习、图神经网络在程序分析中的应用,提升了漏洞检测的准确性与泛化能力,对软件安全领域的实证研究具有重要推动作用。
实际应用
在实际应用中,semeru/code-code-DefectDetection数据集被集成到软件开发周期中,辅助构建智能代码审查系统。企业可利用基于该数据集训练的模型,自动扫描代码库中的安全漏洞,提前预防潜在攻击,减少维护成本。例如,在持续集成/持续部署管道中嵌入此类检测工具,能够实时预警开发人员,增强软件产品的鲁棒性与可靠性,为工业级安全实践提供技术支持。
数据集最近研究
最新研究方向
在软件安全领域,代码缺陷检测数据集semeru/code-code-DefectDetection正推动前沿研究向多模态与可解释性方向深化。该数据集源自Devign项目,专注于C语言漏洞的二进制分类,如资源泄漏与后置使用漏洞,为图神经网络等模型提供基准。当前热点集中于结合代码语义图与预训练语言模型,以提升漏洞识别的精确度与泛化能力,同时研究可解释性方法以揭示漏洞成因,增强开发者信任。这一进展对软件供应链安全与自动化审计具有深远意义,助力构建更健壮的软件生态系统。
以上内容由遇见数据集搜集并总结生成


