gsd-smith-Kikuyu
收藏Hugging Face2026-05-12 更新2026-05-14 收录
下载链接:
https://huggingface.co/datasets/ljvmiranda921/gsd-smith-Kikuyu
下载链接
链接失效反馈官方服务:
资源简介:
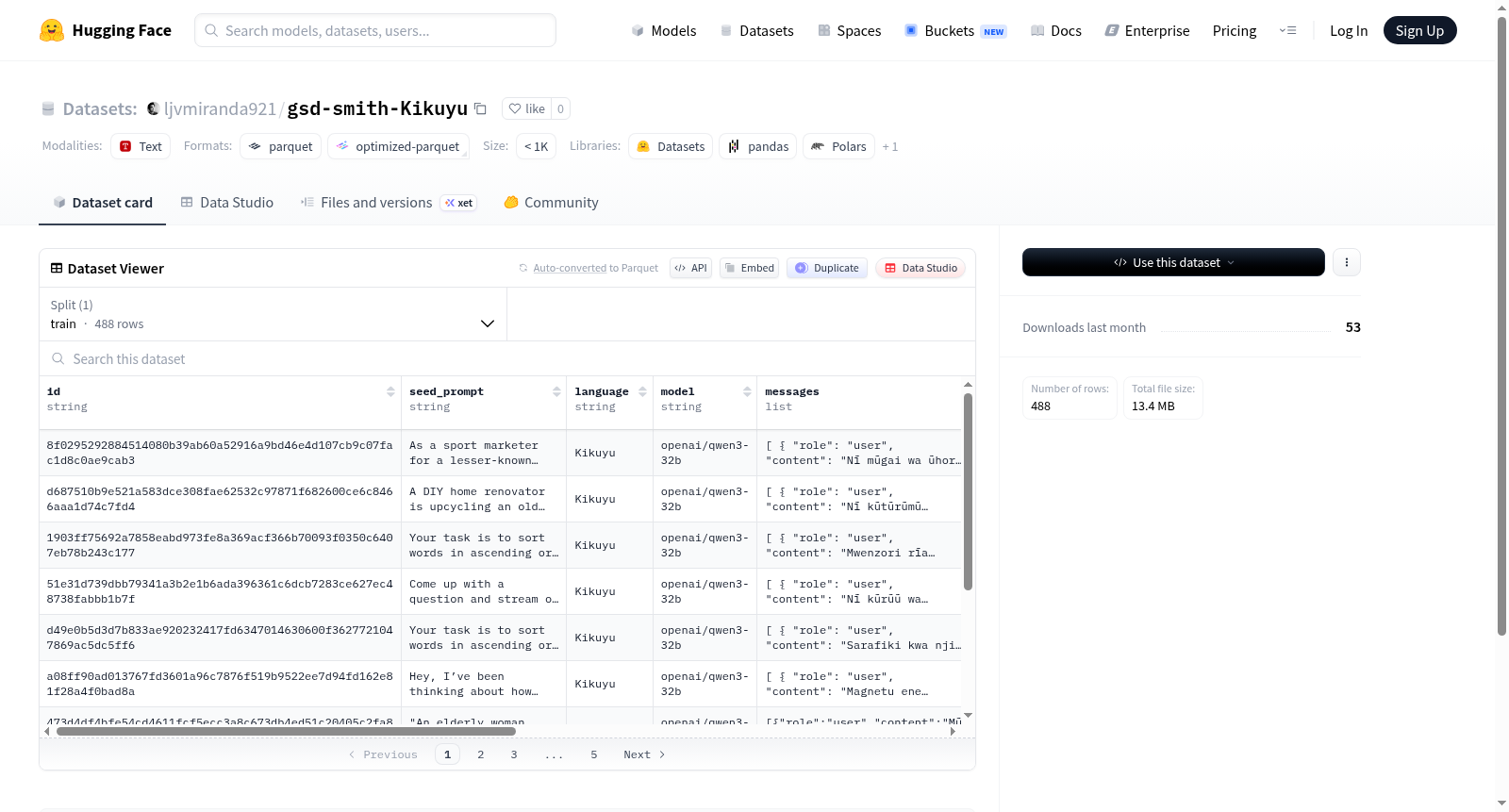
该数据集是一个包含多轮对话交互和代理行为轨迹的数据集。每个数据样本包含以下字段:唯一标识符(id)、初始种子提示(seed_prompt)、语言类型(language)、使用的模型(model)、消息序列(messages,其中每条消息包含角色和内容)、代理执行轨迹(agent_trace,以JSON列表格式记录代理的行为过程)、来源标识(source_id)以及研究早期停止标志(research_early_stopping)。数据集规模为357个训练样本,总数据量约10.5MB。该数据集适用于对话系统研究、多轮对话生成、代理行为分析、人机交互建模等任务,能够为基于大语言模型的对话代理开发和评估提供支持。
This dataset is a collection of multi-turn dialogue interactions and agent behavior trajectories. Each data sample includes the following fields: unique identifier (id), initial seed prompt (seed_prompt), language type (language), model used (model), message sequence (messages, where each message contains a role and content), agent execution trace (agent_trace, recorded in JSON list format detailing the agents behavior process), source identifier (source_id), and research early stopping flag (research_early_stopping). The dataset consists of 357 training samples with a total size of approximately 10.5 MB. It is suitable for tasks such as dialogue system research, multi-turn dialogue generation, agent behavior analysis, and human-computer interaction modeling, providing support for the development and evaluation of large language model-based dialogue agents.
创建时间:
2026-05-09
搜集汇总
数据集介绍
构建方式
gsd-smith-Kikuyu数据集基于基库尤语构建,通过g1)smith 提示生成(textsona)方法进行数据生成。该数据集首先利用种子提示(seed_prompt)激发语言模型,生成包含角色与内容的多轮对话(messages),并记录代理轨迹(agent_trace)以追踪生成过程。数据集中每个样本包含唯一标识符(id)、语言标签(language)、模型信息(model)及来源标识(source_id),同时通过研究早期停止(research_early_stopping)标志控制生成是否提前终止。最终数据被整理为训练集,涵盖488个样本,总大小为13.4 MB,以分片形式存储于data/train-*路径下。
特点
该数据集的一个显著特点是聚焦于低资源语言基库尤语,弥补了该语言在对话式指令数据集中的空白。其结构高度结构化,每条记录包含标准的ChatML格式对话(messages),有利于直接用于训练对话型语言模型。同时,数据集记录了丰富的元信息,如种子提示、模型来源和代理执行轨迹,支持对生成过程的可溯性与可重复性研究。此外,通过研究早期停止标志,数据集内置了质量控制机制,确保生成的对话具备合理的终止条件。
使用方法
使用该数据集时,用户可直接从Hugging Face Datasets库加载默认配置,指定split='train'即可获取训练数据。加载后,每个样本的'messages'字段呈现为角色-内容对序列,适用于构建指令微调或对话系统的训练数据。研究人员可基于'seed_prompt'和'agent_trace'字段分析生成行为的动态过程,或利用'language'字段筛选特定语言子集。建议配合适合多语言对话模型的Tokenizer进行预处理,将内容文本转换为输入张量,并依据'research_early_stopping'标志过滤不完整轨迹,以提升训练稳定性。
背景与挑战
背景概述
在大型语言模型(LLM)的快速发展中,多语言和低资源语言的模型对齐与安全研究逐渐成为重要议题。gsd-smith-Kikuyu数据集由GSD Smith研究团队创建,聚焦于基库尤语(Kikuyu),一种在肯尼亚拥有约600万使用者的班图语系语言。该数据集于2024年发布,核心研究问题在于为基库尤语构建高质量、结构化的对话与智能体交互数据,以支持多语言LLM的对齐训练。通过整合488条包含种子提示、多轮对话及智能体轨迹的样本,该数据集为低资源语言的模型微调提供了关键资源,对推动非洲语言的数字化转型与包容性AI发展具有积极影响。
当前挑战
该数据集主要应对两大挑战。其一,基库尤语作为低资源语言,面临语料稀缺、标注规范缺失的领域问题,限制了LLM在该语言中的表现;该数据集通过人工构建多样化的对话路径,缓解了模型在非英语场景下的对齐不足。其二,构建过程中需克服数据收集与质量控制的困难,包括确保多轮对话的逻辑连贯性、智能体轨迹的合理性,以及避免语言偏见;此外,488条样本虽精致但规模有限,如何在扩充数据量时维持文化特异性和语言学准确性,仍是持续挑战。
常用场景
经典使用场景
在自然语言处理与低资源语言研究的交汇处,gsd-smith-Kikuyu数据集为基库尤语(Kikuyu)的对话系统构建提供了宝贵的语料基础。该数据集包含488条精心整理的对话样本,每条样本涵盖了种子提示、多轮消息序列以及智能体轨迹信息,特别适用于训练和评估面向低资源语言的指令微调模型。研究者可借助其结构化的对话格式,探索基于提示的生成式对话范式,进而推动非洲本土语言在人机交互场景中的技术落地。
衍生相关工作
围绕该数据集已衍生出若干具有启发性的研究工作。其中,利用其智能体轨迹信息进行对话策略优化的研究,探讨了如何在训练过程中引入早期停止机制以平衡模型性能与计算成本。此外,有工作基于该数据集的种子提示设计,研发出针对低资源语言的数据增强框架,通过模板填充和回译技术扩增训练样本。这些衍生工作不仅验证了该数据集在跨语言迁移学习任务中的有效性,也为其他低资源语言的数据集构建提供了可复现的方法论参考。
数据集最近研究
最新研究方向
在当前多语言自然语言处理与大型语言模型的蓬勃发展浪潮中,gsd-smith-Kikuyu数据集的出现恰逢其时,为低资源非洲语言的智能化研究注入了关键动力。该数据集聚焦于基库尤语(Kikuyu)这一东非广泛使用却长期缺乏高质量语料的语言,包含488条精心构造的对话样本,每条样本保留了完整的agent trace(代理追踪)与多轮messages结构,显著区别于传统单轮指令数据集。其核心价值体现在两个前沿方向:一是作为评测基准,用于检验大语言模型在低资源语言上的指令遵循能力与多轮对话连贯性;二是作为微调数据,助力开源模型摆脱英语主导的偏见,向肯尼亚等地的本土化应用场景延伸。结合近年来非洲数字主权运动的升温以及Google、Meta等巨头对斯瓦希里语、约鲁巴语等非洲语言的初步覆盖,基库尤语数据集的建立填补了语言多样性拼图中的空白,推动了AI基础设施的普惠性构建,并有望催化医疗、教育等垂直领域的本地化智能服务落地,其学术与社会意义不容小觑。
以上内容由遇见数据集搜集并总结生成


