iarbel/amazon-product-data-sample
收藏Hugging Face2023-10-29 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/iarbel/amazon-product-data-sample
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: asin
dtype: string
- name: category
dtype: string
- name: img_url
dtype: string
- name: title
dtype: string
- name: feature-bullets
sequence: string
- name: tech_data
sequence:
sequence: string
- name: labels
dtype: string
- name: tech_process
dtype: string
splits:
- name: train
num_bytes: 75797
num_examples: 20
download_size: 62474
dataset_size: 75797
license: cc-by-nc-4.0
task_categories:
- text-generation
language:
- en
size_categories:
- n<1K
---
# Dataset Card for "amazon-product-data-filter"
## Dataset Description
- **Homepage:** [τenai.io - AI Consulting](https://www.tenai.io/)
- **Point of Contact:** [Iftach Arbel](mailto:ia@momentum-ai.io)
### Dataset Summary
The Amazon Product Dataset contains product listing data from the Amazon US website. It can be used for various NLP and classification tasks, such as text generation, product type classification, attribute extraction, image recognition and more.
**NOTICE:** This is a sample of the full [Amazon Product Dataset](https://huggingface.co/datasets/iarbel/amazon-product-data-filter), which contains 1K examples. Follow the link to gain access to the full dataset.
### Languages
The text in the dataset is in English.
## Dataset Structure
### Data Instances
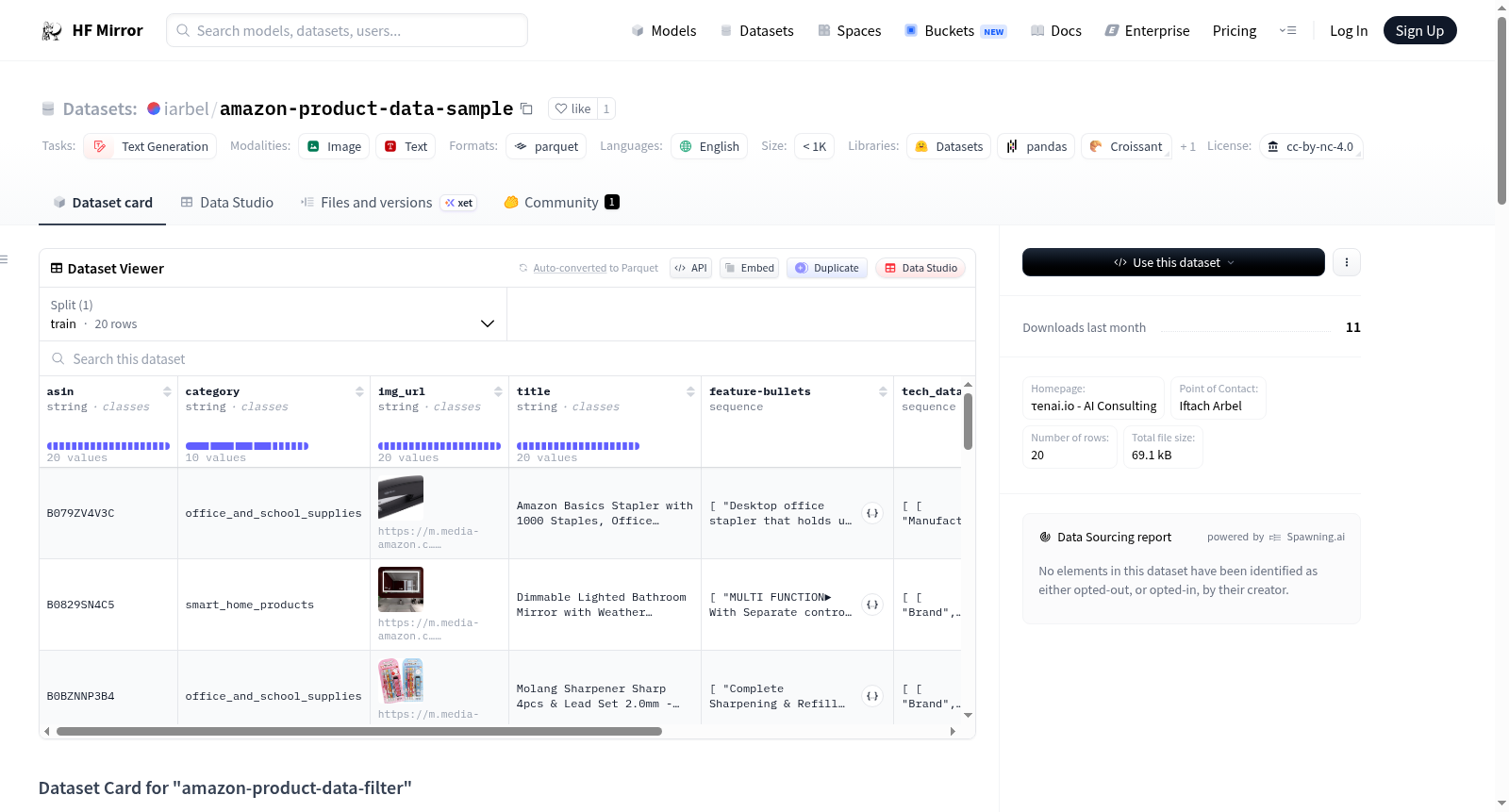
Each data point provides product information, such as ASIN (Amazon Standard Identification Number), title, feature-bullets, and more.
### Data Fields
- `asin`: Amazon Standard Identification Number.
- `category`: The product category. This field represents the search-string used to obtain the listing, it is not the product category as appears on Amazon.com.
- `img_url`: Main image URL from the product page.
- `title`: Product title, as appears on the product page.
- `feature-bullets`: Product feature-bullets list, as they appear on the product page.
- `tech_data`: Product technical data (material, style, etc.), as they appear on the product page. Structured as a list of tuples, where the first element is a feature (e.g. material) and the second element is a value (e.g. plastic).
- `labels`: A processed instance of `feature-bullets` field. The original feature-bullets were aligned to form a standard structure with a capitalized prefix, remove emojis, etc. Finally, the list items were concatenated to a single string with a `\n` seperator.
- `tech_process`: A processed instance of `tech_data` field. The original tech data was filtered and transformed from a `(key, value)` structure to a natural language text.
### Data Splits
The sample dataset has 20 train examples. For the full dataset cilck [here](https://huggingface.co/datasets/iarbel/amazon-product-data-filter).
## Dataset Creation
### Curation Rationale
This dataset was built to provide high-quality data in the e-commerce domain, and fine-tuning LLMs for specific tasks. Raw, unstractured data was collected from Amazom.com, parsed, processed, and filtered using various techniques (annotations, rule-based, models).
### Source Data
#### Initial Data Collection and Normalization
The data was obtained by collected raw HTML data from Amazom.com.
### Annotations
The dataset does not contain any additional annotations.
### Personal and Sensitive Information
There is no personal information in the dataset.
## Considerations for Using the Data
### Social Impact of Dataset
To the best of our knowledge, there is no social impact for this dataset. The data is highly technical, and usage for product text-generation or classification does not pose a risk.
### Other Known Limitations
The quality of product listings may vary, and may not be accurate.
## Additional Information
### Dataset Curators
The dataset was collected and curated by [Iftach Arbel](mailto:ia@momentum-ai.io).
### Licensing Information
The dataset is available under the [Creative Commons NonCommercial (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/legalcode).
### Citation Information
```
@misc{amazon_product_filter,
author = {Iftach Arbel},
title = {Amazon Product Dataset Sample},
year = {2023},
publisher = {Huggingface},
journal = {Huggingface dataset},
howpublished = {https://huggingface.co/datasets/iarbel/amazon-product-data-sample},
}
```
数据集信息:
特征字段:
- 名称:asin,数据类型:字符串
- 名称:category,数据类型:字符串
- 名称:img_url,数据类型:字符串
- 名称:title,数据类型:字符串
- 名称:feature-bullets,数据类型:字符串序列
- 名称:tech_data,数据类型:字符串序列的序列
- 名称:labels,数据类型:字符串
- 名称:tech_process,数据类型:字符串
拆分集:
- 名称:train,字节数:75797,样本数:20
下载大小:62474,数据集大小:75797
许可协议:CC BY-NC 4.0
任务类别:
- 文本生成
语言:
- 英语
样本规模:
- n<1000
# 「亚马逊产品数据筛选」数据集卡片
## 数据集说明
- **官网**:[tenai.io - AI咨询](https://www.tenai.io/)
- **联系人**:[伊夫塔赫·阿贝尔(Iftach Arbel)](mailto:ia@momentum-ai.io)
### 数据集概述
本亚马逊产品数据集包含来自美国亚马逊网站的商品上架数据,可应用于各类自然语言处理(NLP)与分类任务,例如文本生成、产品类型分类、属性提取、图像识别等。
**注意**:本数据集为完整亚马逊产品数据集的样本,完整数据集包含1000条样本,可通过[完整亚马逊产品数据集](https://huggingface.co/datasets/iarbel/amazon-product-data-filter)获取完整数据集。
### 语言说明
本数据集内的文本语言为英语。
## 数据集结构
### 数据样本
每个数据样本包含商品相关信息,例如ASIN(亚马逊标准识别码,Amazon Standard Identification Number)、商品标题、特性要点列表(Feature-Bullets)等。
### 数据字段
- `asin`:亚马逊标准识别码(ASIN,Amazon Standard Identification Number)。
- `category`:商品类别。该字段为用于获取商品上架信息的搜索字符串,并非亚马逊官网展示的商品分类。
- `img_url`:商品页面的主图片URL。
- `title`:商品页面展示的商品标题。
- `feature-bullets`:商品页面展示的产品特性要点列表(Feature-Bullets)。
- `tech_data`:商品页面展示的产品技术数据(如材质、款式等)。其结构为元组列表,其中第一个元素为特性名称(例如材质),第二个元素为对应属性值(例如塑料)。
- `labels`:`feature-bullets`字段的处理后版本。原始特性要点列表已被标准化处理:添加大写前缀、移除表情符号等。最终所有列表项以换行符(`
`)作为分隔符拼接为单个字符串。
- `tech_process`:`tech_data`字段的处理后版本。原始技术数据已经过筛选,并从`(键, 值)`结构转换为自然语言文本。
### 数据拆分
本样本数据集包含20条训练样本。完整数据集可通过[此链接](https://huggingface.co/datasets/iarbel/amazon-product-data-filter)获取。
## 数据集构建
### 构建逻辑
本数据集旨在为电商领域提供高质量数据,并用于针对特定任务微调大语言模型(LLMs)。原始非结构化数据采集自亚马逊官网,随后通过各类技术(包括标注、基于规则的方法、模型等)进行解析、处理与筛选。
### 源数据
#### 初始数据采集与标准化
本数据集通过采集亚马逊官网的原始HTML数据获取。
### 标注信息
本数据集不包含额外标注内容。
### 个人与敏感信息
本数据集不包含任何个人敏感信息。
## 数据使用注意事项
### 数据集的社会影响
据我们所知,本数据集无潜在社会影响。该数据为纯技术类数据,用于产品文本生成或分类任务不会带来风险。
### 已知其他局限性
商品上架信息的质量可能存在差异,且部分信息可能不准确。
## 补充信息
### 数据集管理者
本数据集由[伊夫塔赫·阿贝尔(Iftach Arbel)](mailto:ia@momentum-ai.io)采集与整理。
### 许可协议
本数据集采用[知识共享署名-非商业性使用4.0国际许可协议(CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/legalcode)进行授权。
### 引用信息
@misc{amazon_product_filter,
author = {Iftach Arbel},
title = {Amazon Product Dataset Sample},
year = {2023},
publisher = {Huggingface},
journal = {Huggingface dataset},
howpublished = {https://huggingface.co/datasets/iarbel/amazon-product-data-sample},
}
提供机构:
iarbel
原始信息汇总
数据集卡片 "amazon-product-data-filter"
数据集描述
数据集摘要
Amazon Product Dataset 包含来自 Amazon US 网站的产品列表数据。它可用于各种 NLP 和分类任务,如文本生成、产品类型分类、属性提取、图像识别等。
语言
数据集中的文本为英语。
数据集结构
数据实例
每个数据点提供产品信息,如 ASIN(Amazon Standard Identification Number)、标题、特征列表等。
数据字段
asin: Amazon Standard Identification Number。category: 产品类别。此字段表示用于获取列表的搜索字符串,并非 Amazon.com 上显示的产品类别。img_url: 产品页面的主图像 URL。title: 产品页面上显示的产品标题。feature-bullets: 产品页面上显示的产品特征列表。tech_data: 产品技术数据(材料、样式等),产品页面上显示。结构为元组列表,第一个元素是特征(如材料),第二个元素是值(如塑料)。labels:feature-bullets字段的处理实例。原始特征列表被对齐以形成标准结构,删除表情符号等。最后,列表项被连接成一个带有tech_process:tech_data字段的处理实例。原始技术数据被过滤并从(key, value)结构转换为自然语言文本。
数据分割
样本数据集有 20 个训练示例。完整数据集请点击这里。
数据集创建
策划理由
此数据集旨在提供高质量的电子商务领域数据,并针对特定任务微调 LLM。从 Amazon.com 收集的原始非结构化数据经过解析、处理和过滤(注释、基于规则、模型)。
源数据
初始数据收集和规范化
数据通过从 Amazon.com 收集原始 HTML 数据获得。
注释
数据集不包含任何额外注释。
个人和敏感信息
数据集中没有个人信息。
使用数据的考虑
数据集的社会影响
据我们所知,此数据集没有社会影响。数据高度技术化,用于产品文本生成或分类不会构成风险。
其他已知限制
产品列表的质量可能有所不同,可能不准确。
附加信息
数据集策展人
数据集由 Iftach Arbel 收集和策展。
许可信息
数据集在 Creative Commons NonCommercial (CC BY-NC 4.0) 下提供。
引用信息
@misc{amazon_product_filter, author = {Iftach Arbel}, title = {Amazon Product Dataset Sample}, year = {2023}, publisher = {Huggingface}, journal = {Huggingface dataset}, howpublished = {https://huggingface.co/datasets/iarbel/amazon-product-data-sample}, }
搜集汇总
数据集介绍
构建方式
在电子商务领域,高质量的产品数据对于自然语言处理任务至关重要。该数据集通过采集亚马逊美国网站的原始HTML页面构建而成,随后运用多种技术手段进行解析、处理和筛选,包括基于规则的清洗和模型辅助的过滤。原始的非结构化数据经过系统化整理,转化为包含产品标识、类别、图像链接、标题及技术属性等结构化字段的样本集合,为后续的文本生成与分类研究奠定了数据基础。
特点
该数据集涵盖了亚马逊平台上的多样化产品信息,其核心特征在于提供了丰富的多模态数据字段,例如产品标题、特性要点列表以及结构化的技术参数。特别值得注意的是,数据集包含经过处理的标签字段和技术流程字段,前者将特性要点标准化并整合为连贯文本,后者则将原始技术数据转化为自然语言描述,增强了数据的可读性与可用性。这些特征使其特别适用于产品文本生成、属性提取及分类模型训练等任务。
使用方法
在自然语言处理与机器学习研究中,该数据集可作为训练与评估模型的重要资源。用户可通过加载数据集,直接访问其结构化字段,如asin、title、feature-bullets及labels等,用于文本生成模型的微调或产品分类任务的训练。鉴于数据集规模较小,建议将其作为原型开发或方法验证的样本,完整数据集则需访问指定链接获取。使用时应遵循CC BY-NC 4.0许可协议,并注意产品列表质量可能存在的差异。
背景与挑战
背景概述
在电子商务与自然语言处理交叉领域,高质量产品数据的稀缺性长期制约着相关模型的发展。iarbel/amazon-product-data-sample数据集由Iftach Arbel于2023年构建并发布,旨在为电子商务领域的文本生成、产品分类及属性提取等任务提供结构化数据支持。该数据集源自亚马逊美国网站的真实产品列表,通过解析原始HTML数据并经过多轮处理与过滤,形成了包含产品标题、特征描述、技术参数等多模态信息的高质量样本。其核心研究问题聚焦于如何将非结构化的网页内容转化为适用于大语言模型微调的规范化数据,从而推动电子商务智能化应用的进步,对产品推荐、自动摘要及知识图谱构建等领域产生了积极影响。
当前挑战
该数据集致力于解决电子商务领域中产品信息结构化与语义理解的复杂挑战,具体包括从异构网页中准确提取并标准化产品属性,以及处理自然语言描述中的歧义性与噪声。在构建过程中,面临多重技术难题:原始HTML数据的解析需要应对动态页面结构与多样化的信息呈现方式;特征描述与技术参数的自动化对齐与清洗过程需克服文本格式不一致、符号冗余及信息缺失等问题;同时,在有限标注条件下确保数据质量与一致性,亦对数据处理流程的鲁棒性提出了较高要求。
常用场景
经典使用场景
在电子商务与自然语言处理交叉领域,该数据集为产品文本生成与分类任务提供了典型范例。其结构化特征如产品标题、特性列表及技术数据,能够支持模型学习商品描述的语义模式与属性关联,常用于训练序列到序列模型或分类器,以自动化生成或归类产品信息,提升电商平台内容管理的效率。
解决学术问题
该数据集有效应对了电商领域文本数据稀疏与结构异质性的挑战,为学术研究提供了高质量标注资源。它助力解决产品属性抽取、多模态信息融合及领域自适应语言建模等关键问题,推动自然语言处理技术在真实商业场景中的泛化能力与鲁棒性发展,具有显著的实证研究价值。
衍生相关工作
基于该数据集衍生的经典工作包括端到端的产品标题生成模型、基于注意力机制的多属性分类框架,以及结合图像与文本的跨模态检索系统。这些研究不仅深化了电商文本理解的技术边界,还为后续大规模商品知识图谱构建与个性化服务设计奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


