FailSafeQA
收藏arXiv2025-02-10 更新2025-02-12 收录
下载链接:
https://huggingface.co/datasets/Writer/FailSafeQA
下载链接
链接失效反馈官方服务:
资源简介:
FailSafeQA数据集是由Writer, Inc创建的,用于测试大型语言模型在金融领域中面对用户界面交互变化的鲁棒性和上下文感知能力。该数据集包含220个示例,每个示例由一个上下文和五个问题组成,其中包括原始问题、三个扰动变种和一个无关问题。数据集的上下文是截断的美国公开上市公司10-K年度报告,这些问题和上下文经过人工和自动化的生成和扰动处理。该数据集旨在评估LLM在金融应用中的可靠性,并解决模型在面对非理想条件下的输入扰动时的问题。
The FailSafeQA dataset was developed by Writer, Inc. to evaluate the robustness and contextual awareness of large language models (LLMs) when faced with user interface interaction variations in the financial domain. This dataset consists of 220 instances, each comprising a context and five questions: the original query, three perturbed variants, and one irrelevant question. The contexts within the dataset are truncated 10-K annual reports of publicly traded U.S. companies, and both the questions and contexts were generated and perturbed through a combination of manual and automated processes. This dataset is designed to assess the reliability of LLMs in financial applications and address the challenges that models encounter when exposed to input perturbations under non-ideal conditions.
提供机构:
Writer, Inc
创建时间:
2025-02-10
原始信息汇总
数据集概述
数据集名称
FailSafeQA
许可
MIT
任务类别
- 文本生成
- 问题回答
语言
- 英语 (en)
标签
- 金融 (finance)
- 合成 (synthetic)
数据配置
- 配置名称:默认
- 测试集:
FAILSAFEQA_benchmark_data-FINAL.jsonl
- 测试集:
数据集简介
该数据集是基于论文《Expect the Unexpected: FailSafeQA Long Context for Finance》引入的基准数据。
数据集数量
220
数据结构
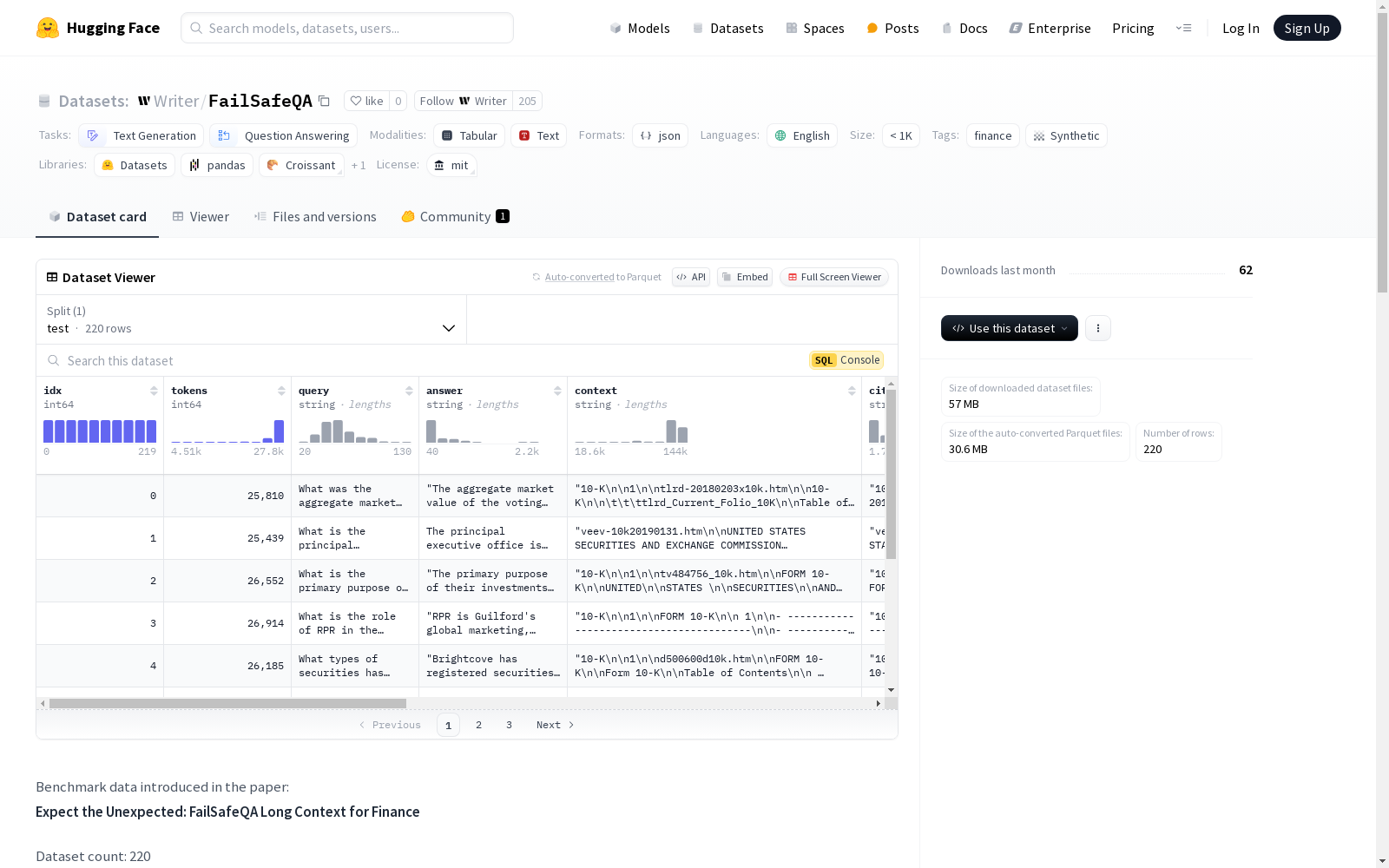
json { "idx": int, "tokens": int, "context": string, "ocr_context": string, "answer": string, "query": string, "incomplete_query": string, "out-of-domain_query": string, "error_query": string, "out-of-scope_query": string, "citations": string, "citations_tokens": int }
任务多样性
- 根动词及其直接宾语:展示了每个标准化查询的第一句中的前20个动词及其前五个直接宾语。
- 任务类型:
- 83.0% 问题回答 (QA)
- 17.0% 涉及文本生成 (TG)
引用信息
@misc{kiran2024failsafeqa, title={Expect the Unexpected: FailSafeQA Long Context for Finance}, author={Kiran Kamble and Melisa Russak and Dmytro Mozolevskyi and Muayad Ali and Mateusz Russak and Waseem AlShikh}, year={2024}, eprint={todo}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
构建方式
FailSafeQA数据集的构建是通过模拟真实世界中的用户交互来进行的。数据集包含了美国上市公司1998年至2018年间提交给SEC EDGAR系统的10-K年度报告,这些报告被截断以适应不超过25k tokens的上下文窗口。数据集构建分为三个阶段:查询生成、查询扰动和上下文扰动。查询生成阶段包括基于截断的10-K文件生成多轮查询和答案对,并通过标准化和过滤来优化查询。查询扰动阶段引入了三种类型的查询扰动:拼写错误、不完整查询和域外查询。上下文扰动阶段则模拟了缺失上下文、OCR错误和无关上下文的情况。为了简化评估过程,所有答案都基于文档中的真实引用,确保评估的准确性和全面性。
特点
FailSafeQA数据集的特点在于其专注于评估大型语言模型在金融领域的鲁棒性和上下文感知能力。数据集通过模拟用户与问答系统之间的真实交互,测试模型在遇到查询失败和上下文失败情况时的表现。查询失败场景中,模型需要应对查询的领域专业知识、完整性和语言准确性方面的变化。上下文失败场景中,模型需要处理退化的、无关的或空的文档。数据集使用了LLM-as-a-Judge方法,并采用细粒度的评分标准来定义和计算鲁棒性、上下文基础和合规性分数。
使用方法
FailSafeQA数据集的使用方法主要包括两个步骤:查询生成和上下文生成。查询生成阶段,用户可以基于数据集中的10-K文件生成查询,并可以选择性地引入拼写错误、不完整查询或域外查询来测试模型的鲁棒性。上下文生成阶段,用户可以模拟缺失上下文、OCR错误或无关上下文的情况,以测试模型在处理这些异常情况时的表现。数据集还提供了评估模型性能的评分标准,包括鲁棒性、上下文基础和合规性分数,以便用户可以根据这些指标来评估模型的性能。
背景与挑战
背景概述
随着金融服务业和大型语言模型(LLMs)的快速发展,金融服务领域越来越多地采用LLMs来揭示数据中的洞察力。FailSafeQA是一个新的长上下文金融基准,旨在测试LLMs在面对六种人类交互变化时的鲁棒性和上下文感知能力。该数据集由Kiran Kamble、Melisa Russak等人创建,主要研究人员来自Writer, Inc。FailSafeQA专注于两个案例研究:查询失败和上下文失败。在查询失败场景中,我们对原始查询进行扰动,使其在领域专业知识、完整性和语言准确性方面发生变化。在上下文失败案例中,我们模拟了上传降级、无关和空文档的情况。我们采用了LLM-as-a-Judge方法,并使用细粒度评分标准来定义和计算24个现成的模型的鲁棒性、上下文基础和合规性分数。结果显示,尽管一些模型在减轻输入扰动方面表现出色,但它们必须平衡鲁棒回答的能力和避免幻觉的能力。FailSafeQA作为开发LLMs的工具,旨在优化金融应用中的可靠性。
当前挑战
FailSafeQA数据集面临的挑战包括:1) LLMs在处理长上下文文本时往往忽视细节或编造响应;2) LLMs对提示格式中的细微变化非常敏感;3) 需要建立评估LLMs风险的措施和区分安全和不安全模型的标准;4) 需要开发更准确的测试场景,以反映用户和查询-回答系统之间的现实世界交互。
常用场景
经典使用场景
FailSafeQA数据集被设计用于评估大型语言模型(LLMs)在金融领域查询-回答系统中的鲁棒性和上下文感知能力。该数据集通过模拟真实世界用户与查询-回答系统之间的交互,评估模型在面对各种输入变化时的表现。在Query Failure场景中,通过改变原始查询的领域专业知识、完整性和语言准确性来扰动查询。在Context Failure场景中,模拟上传的文档质量下降、不相关和空文档的情况。FailSafeQA数据集通过LLM-as-a-Judge方法评估了24个现成的模型,使用细粒度的评分标准来定义和计算鲁棒性、上下文基础和合规性得分。
实际应用
FailSafeQA数据集的实际应用场景包括金融风险分析、客户服务和运营决策等领域。该数据集通过评估LLMs在处理真实世界交互中的表现,有助于开发更可靠的模型,以满足金融领域的需求。FailSafeQA数据集的发布和评估结果为金融领域的LLMs研究和应用提供了重要的参考。
衍生相关工作
FailSafeQA数据集衍生了多个相关的工作,例如HELM (Liang et al., 2023)评估了LLMs在不同条件下的鲁棒性,FinBen (Xie et al., 2024)是一个开源的评估框架,包括24个任务,涵盖风险管理、文本生成等领域。FailSafeQA数据集的发布和评估结果为金融领域的LLMs研究和应用提供了重要的参考。
以上内容由遇见数据集搜集并总结生成


