有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
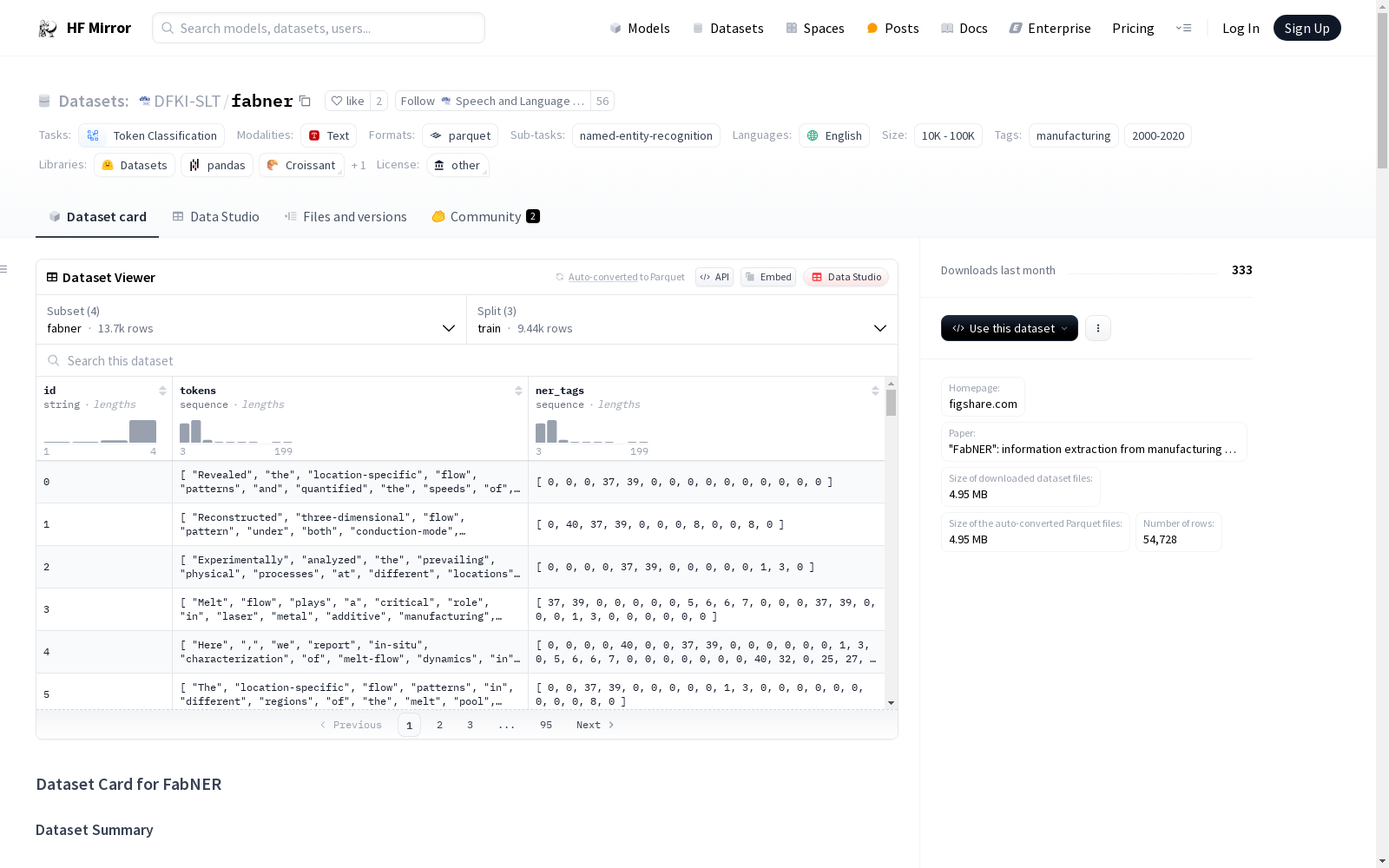
FabNER 是一个用于命名实体识别(Named Entity Recognition, NER)的制造业文本数据集,包含超过350,000个单词。该数据集是从Web of Science中的已知期刊中收集的摘要,涵盖了制造业过程科学研究的领域。每个单词都有定义的类别/实体标签,包括材料(MATE)、制造过程(MANP)、机器/设备(MACEQ)、应用(APPL)、特征(FEAT)、机械性能(PRO)、表征(CHAR)、参数(PARA)、使能技术(ENAT)、概念/原理(CONPRI)、制造标准(MANS)和生物医学(BIOP)。注释以BIOES格式进行:B=开始,I=中间,O=外部,E=结束,S=单个。
该数据集支持的任务是命名实体识别(Named Entity Recognition, NER)。
数据集中的语言是英语。
一个训练实例的示例如下: json { "id": "0", "tokens": ["Revealed", "the", "location-specific", "flow", "patterns", "and", "quantified", "the", "speeds", "of", "various", "types", "of", "flow", "."], "ner_tags": [0, 0, 0, 46, 49, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] }
id: 句子实例的ID,字符串类型。tokens: 句子中的单词列表,字符串列表类型。ner_tags: 实体标签列表,分类标签列表类型。标签映射如下: json {"O": 0, "B-MATE": 1, "I-MATE": 2, "O-MATE": 3, "E-MATE": 4, "S-MATE": 5, "B-MANP": 6, "I-MANP": 7, "O-MANP": 8, "E-MANP": 9, "S-MANP": 10, "B-MACEQ": 11, "I-MACEQ": 12, "O-MACEQ": 13, "E-MACEQ": 14, "S-MACEQ": 15, "B-APPL": 16, "I-APPL": 17, "O-APPL": 18, "E-APPL": 19, "S-APPL": 20, "B-FEAT": 21, "I-FEAT": 22, "O-FEAT": 23, "E-FEAT": 24, "S-FEAT": 25, "B-PRO": 26, "I-PRO": 27, "O-PRO": 28, "E-PRO": 29, "S-PRO": 30, "B-CHAR": 31, "I-CHAR": 32, "O-CHAR": 33, "E-CHAR": 34, "S-CHAR": 35, "B-PARA": 36, "I-PARA": 37, "O-PARA": 38, "E-PARA": 39, "S-PARA": 40, "B-ENAT": 41, "I-ENAT": 42, "O-ENAT": 43, "E-ENAT": 44, "S-ENAT": 45, "B-CONPRI": 46, "I-CONPRI": 47, "O-CONPRI": 48, "E-CONPRI": 49, "S-CONPRI": 50, "B-MANS": 51, "I-MANS": 52, "O-MANS": 53, "E-MANS": 54, "S-MANS": 55, "B-BIOP": 56, "I-BIOP": 57, "O-BIOP": 58, "E-BIOP": 59, "S-BIOP": 60}
id: 句子实例的ID,字符串类型。tokens: 句子中的单词列表,字符串列表类型。ner_tags: 实体标签列表,分类标签列表类型。标签映射如下: json {"O": 0, "B-MATE": 1, "I-MATE": 2, "B-MANP": 3, "I-MANP": 4, "B-MACEQ": 5, "I-MACEQ": 6, "B-APPL": 7, "I-APPL": 8, "B-FEAT": 9, "I-FEAT": 10, "B-PRO": 11, "I-PRO": 12, "B-CHAR": 13, "I-CHAR": 14, "B-PARA": 15, "I-PARA": 16, "B-ENAT": 17, "I-ENAT": 18, "B-CONPRI": 19, "I-CONPRI": 20, "B-MANS": 21, "I-MANS": 22, "B-BIOP": 23, "I-BIOP": 24}
id: 句子实例的ID,字符串类型。tokens: 句子中的单词列表,字符串列表类型。ner_tags: 实体标签列表,分类标签列表类型。标签映射如下: json {"O": 0, "MATE": 1, "MANP": 2, "MACEQ": 3, "APPL": 4, "FEAT": 5, "PRO": 6, "CHAR": 7, "PARA": 8, "ENAT": 9, "CONPRI": 10, "MANS": 11, "BIOP": 12}
id: 句子实例的ID,字符串类型。tokens: 句子中的单词列表,字符串列表类型。ner_tags: 实体标签列表,分类标签列表类型。标签映射如下: json {"O": 0, "Technological System": 1, "Method": 2, "Material": 3, "Technical Field": 4}
| 训练集 | 验证集 | 测试集 | |
|---|---|---|---|
| fabner | 9435 | 2183 | 2064 |
数据集是从Web of Science中的已知期刊中收集的摘要,涵盖了制造业过程科学研究的领域。
注释由专家生成,以BIOES格式进行:B=开始,I=中间,O=外部,E=结束,S=单个。
该数据集主要用于提高制造业领域的信息提取和命名实体识别的准确性。
数据集可能包含特定领域的偏见,需要在使用时进行评估和调整。
数据集可能受限于特定领域的术语和表达方式,可能不适用于所有通用场景。
数据集的许可证类型为“其他”。
@article{DBLP:journals/jim/KumarS22, author = {Aman Kumar and Binil Starly}, title = {"FabNER": information extraction from manufacturing process science domain literature using named entity recognition}, journal = {J. Intell. Manuf.}, volume = {33}, number = {8}, pages = {2393--2407}, year = {2022}, url = {https://doi.org/10.1007/s10845-021-01807-x}, doi = {10.1007/s10845-021-01807-x}, timestamp = {Sun, 13 Nov 2022 17:52:57 +0100}, biburl = {https://dblp.org/rec/journals/jim/KumarS22.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
感谢 @phucdev 添加此数据集。
TM-Senti
TM-Senti是由伦敦玛丽女王大学开发的一个大规模、远距离监督的Twitter情感数据集,包含超过1.84亿条推文,覆盖了超过七年的时间跨度。该数据集基于互联网档案馆的公开推文存档,可以完全重新构建,包括推文元数据且无缺失推文。数据集内容丰富,涵盖多种语言,主要用于情感分析和文本分类等任务。创建过程中,研究团队精心筛选了表情符号和表情,确保数据集的质量和多样性。该数据集的应用领域广泛,旨在解决社交媒体情感表达的长期变化问题,特别是在表情符号和表情使用上的趋势分析。
arXiv 收录
FER2013
FER2013数据集是一个广泛用于面部表情识别领域的数据集,包含28,709个训练样本和7,178个测试样本。图像属性为48x48像素,标签包括愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性。
github 收录
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录
猫狗图像数据集
该数据集包含猫和狗的图像,每类各12500张。训练集和测试集分别包含10000张和2500张图像,用于模型的训练和评估。
github 收录
Titanic Dataset
Titanic Data Analysis: A Journey into Passenger Profiles and Survival Dynamics
kaggle 收录