---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets: []
task_categories:
- token-classification
task_ids:
- named-entity-recognition
pretty_name: FabNER is a manufacturing text dataset for Named Entity Recognition.
tags:
- manufacturing
- 2000-2020
dataset_info:
- config_name: fabner
features:
- name: id
dtype: string
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-MATE
'2': I-MATE
'3': E-MATE
'4': S-MATE
'5': B-MANP
'6': I-MANP
'7': E-MANP
'8': S-MANP
'9': B-MACEQ
'10': I-MACEQ
'11': E-MACEQ
'12': S-MACEQ
'13': B-APPL
'14': I-APPL
'15': E-APPL
'16': S-APPL
'17': B-FEAT
'18': I-FEAT
'19': E-FEAT
'20': S-FEAT
'21': B-PRO
'22': I-PRO
'23': E-PRO
'24': S-PRO
'25': B-CHAR
'26': I-CHAR
'27': E-CHAR
'28': S-CHAR
'29': B-PARA
'30': I-PARA
'31': E-PARA
'32': S-PARA
'33': B-ENAT
'34': I-ENAT
'35': E-ENAT
'36': S-ENAT
'37': B-CONPRI
'38': I-CONPRI
'39': E-CONPRI
'40': S-CONPRI
'41': B-MANS
'42': I-MANS
'43': E-MANS
'44': S-MANS
'45': B-BIOP
'46': I-BIOP
'47': E-BIOP
'48': S-BIOP
splits:
- name: train
num_bytes: 4394010
num_examples: 9435
- name: validation
num_bytes: 934347
num_examples: 2183
- name: test
num_bytes: 940136
num_examples: 2064
download_size: 1265830
dataset_size: 6268493
- config_name: fabner_bio
features:
- name: id
dtype: string
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-MATE
'2': I-MATE
'3': B-MANP
'4': I-MANP
'5': B-MACEQ
'6': I-MACEQ
'7': B-APPL
'8': I-APPL
'9': B-FEAT
'10': I-FEAT
'11': B-PRO
'12': I-PRO
'13': B-CHAR
'14': I-CHAR
'15': B-PARA
'16': I-PARA
'17': B-ENAT
'18': I-ENAT
'19': B-CONPRI
'20': I-CONPRI
'21': B-MANS
'22': I-MANS
'23': B-BIOP
'24': I-BIOP
splits:
- name: train
num_bytes: 4394010
num_examples: 9435
- name: validation
num_bytes: 934347
num_examples: 2183
- name: test
num_bytes: 940136
num_examples: 2064
download_size: 1258672
dataset_size: 6268493
- config_name: fabner_simple
features:
- name: id
dtype: string
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': MATE
'2': MANP
'3': MACEQ
'4': APPL
'5': FEAT
'6': PRO
'7': CHAR
'8': PARA
'9': ENAT
'10': CONPRI
'11': MANS
'12': BIOP
splits:
- name: train
num_bytes: 4394010
num_examples: 9435
- name: validation
num_bytes: 934347
num_examples: 2183
- name: test
num_bytes: 940136
num_examples: 2064
download_size: 1233960
dataset_size: 6268493
- config_name: text2tech
features:
- name: id
dtype: string
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': Technological System
'2': Method
'3': Material
'4': Technical Field
splits:
- name: train
num_bytes: 4394010
num_examples: 9435
- name: validation
num_bytes: 934347
num_examples: 2183
- name: test
num_bytes: 940136
num_examples: 2064
download_size: 1192966
dataset_size: 6268493
configs:
- config_name: fabner
data_files:
- split: train
path: fabner/train-*
- split: validation
path: fabner/validation-*
- split: test
path: fabner/test-*
default: true
- config_name: fabner_bio
data_files:
- split: train
path: fabner_bio/train-*
- split: validation
path: fabner_bio/validation-*
- split: test
path: fabner_bio/test-*
- config_name: fabner_simple
data_files:
- split: train
path: fabner_simple/train-*
- split: validation
path: fabner_simple/validation-*
- split: test
path: fabner_simple/test-*
- config_name: text2tech
data_files:
- split: train
path: text2tech/train-*
- split: validation
path: text2tech/validation-*
- split: test
path: text2tech/test-*
---
# Dataset Card for FabNER
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://figshare.com/articles/dataset/Dataset_NER_Manufacturing_-_FabNER_Information_Extraction_from_Manufacturing_Process_Science_Domain_Literature_Using_Named_Entity_Recognition/14782407](https://figshare.com/articles/dataset/Dataset_NER_Manufacturing_-_FabNER_Information_Extraction_from_Manufacturing_Process_Science_Domain_Literature_Using_Named_Entity_Recognition/14782407)
- **Paper:** ["FabNER": information extraction from manufacturing process science domain literature using named entity recognition](https://par.nsf.gov/servlets/purl/10290810)
- **Size of downloaded dataset files:** 3.79 MB
- **Size of the generated dataset:** 6.27 MB
### Dataset Summary
FabNER is a manufacturing text corpus of 350,000+ words for Named Entity Recognition.
It is a collection of abstracts obtained from Web of Science through known journals available in manufacturing process
science research.
For every word, there were categories/entity labels defined, namely Material (MATE), Manufacturing Process (MANP),
Machine/Equipment (MACEQ), Application (APPL), Features (FEAT), Mechanical Properties (PRO), Characterization (CHAR),
Parameters (PARA), Enabling Technology (ENAT), Concept/Principles (CONPRI), Manufacturing Standards (MANS) and
BioMedical (BIOP). Annotation was performed in all categories along with the output tag in 'BIOES' format:
B=Beginning, I-Intermediate, O=Outside, E=End, S=Single.
For details about the dataset, please refer to the paper: ["FabNER": information extraction from manufacturing process science domain literature using named entity recognition](https://par.nsf.gov/servlets/purl/10290810)
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
The language in the dataset is English.
## Dataset Structure
### Data Instances
- **Size of downloaded dataset files:** 3.79 MB
- **Size of the generated dataset:** 6.27 MB
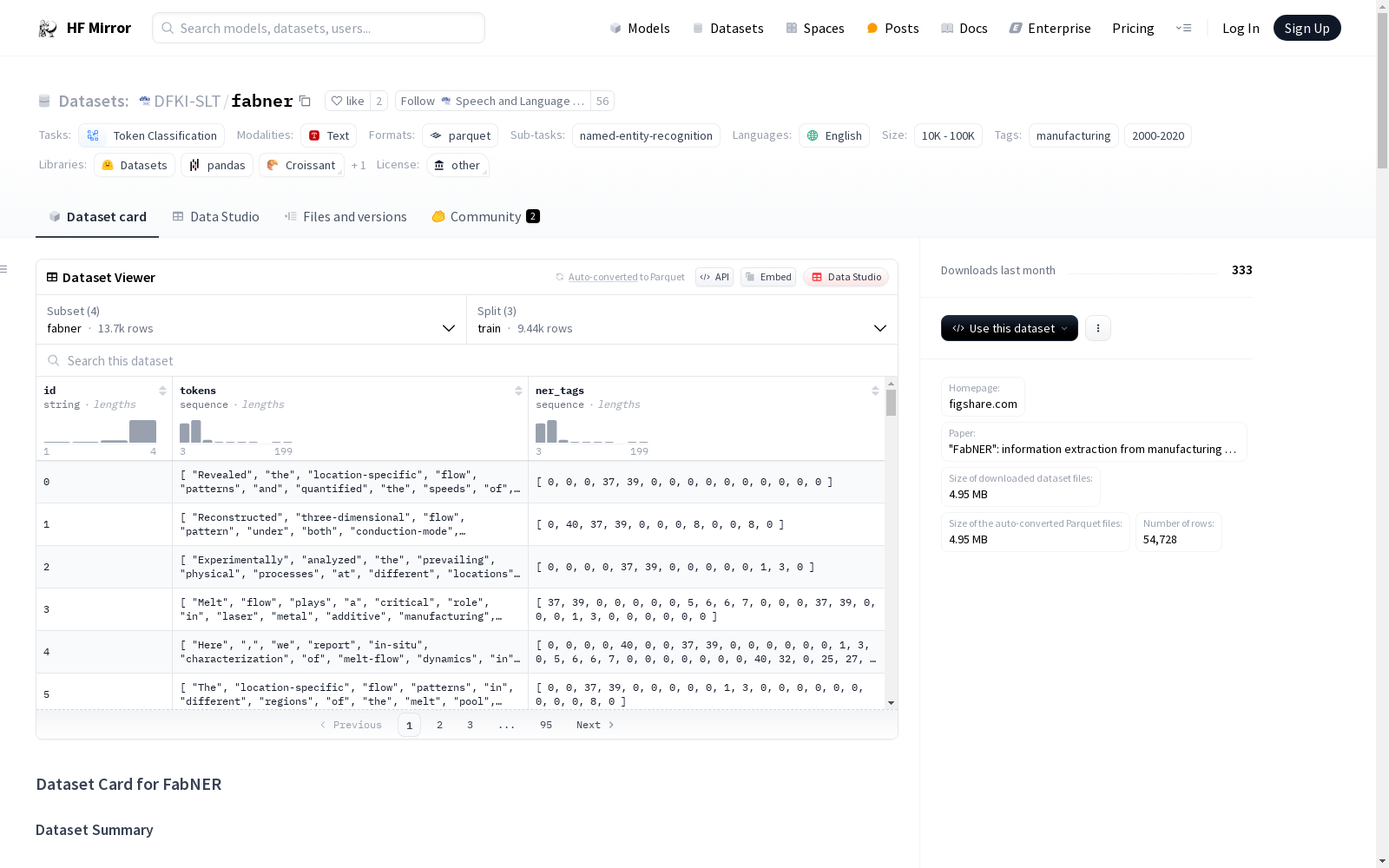
An example of 'train' looks as follows:
```json
{
"id": "0",
"tokens": ["Revealed", "the", "location-specific", "flow", "patterns", "and", "quantified", "the", "speeds", "of", "various", "types", "of", "flow", "."],
"ner_tags": [0, 0, 0, 46, 49, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}
```
### Data Fields
#### fabner
- `id`: the instance id of this sentence, a `string` feature.
- `tokens`: the list of tokens of this sentence, a `list` of `string` features.
- `ner_tags`: the list of entity tags, a `list` of classification labels.
```json
{"O": 0, "B-MATE": 1, "I-MATE": 2, "O-MATE": 3, "E-MATE": 4, "S-MATE": 5, "B-MANP": 6, "I-MANP": 7, "O-MANP": 8, "E-MANP": 9, "S-MANP": 10, "B-MACEQ": 11, "I-MACEQ": 12, "O-MACEQ": 13, "E-MACEQ": 14, "S-MACEQ": 15, "B-APPL": 16, "I-APPL": 17, "O-APPL": 18, "E-APPL": 19, "S-APPL": 20, "B-FEAT": 21, "I-FEAT": 22, "O-FEAT": 23, "E-FEAT": 24, "S-FEAT": 25, "B-PRO": 26, "I-PRO": 27, "O-PRO": 28, "E-PRO": 29, "S-PRO": 30, "B-CHAR": 31, "I-CHAR": 32, "O-CHAR": 33, "E-CHAR": 34, "S-CHAR": 35, "B-PARA": 36, "I-PARA": 37, "O-PARA": 38, "E-PARA": 39, "S-PARA": 40, "B-ENAT": 41, "I-ENAT": 42, "O-ENAT": 43, "E-ENAT": 44, "S-ENAT": 45, "B-CONPRI": 46, "I-CONPRI": 47, "O-CONPRI": 48, "E-CONPRI": 49, "S-CONPRI": 50, "B-MANS": 51, "I-MANS": 52, "O-MANS": 53, "E-MANS": 54, "S-MANS": 55, "B-BIOP": 56, "I-BIOP": 57, "O-BIOP": 58, "E-BIOP": 59, "S-BIOP": 60}
```
#### fabner_bio
- `id`: the instance id of this sentence, a `string` feature.
- `tokens`: the list of tokens of this sentence, a `list` of `string` features.
- `ner_tags`: the list of entity tags, a `list` of classification labels.
```json
{"O": 0, "B-MATE": 1, "I-MATE": 2, "B-MANP": 3, "I-MANP": 4, "B-MACEQ": 5, "I-MACEQ": 6, "B-APPL": 7, "I-APPL": 8, "B-FEAT": 9, "I-FEAT": 10, "B-PRO": 11, "I-PRO": 12, "B-CHAR": 13, "I-CHAR": 14, "B-PARA": 15, "I-PARA": 16, "B-ENAT": 17, "I-ENAT": 18, "B-CONPRI": 19, "I-CONPRI": 20, "B-MANS": 21, "I-MANS": 22, "B-BIOP": 23, "I-BIOP": 24}
```
#### fabner_simple
- `id`: the instance id of this sentence, a `string` feature.
- `tokens`: the list of tokens of this sentence, a `list` of `string` features.
- `ner_tags`: the list of entity tags, a `list` of classification labels.
```json
{"O": 0, "MATE": 1, "MANP": 2, "MACEQ": 3, "APPL": 4, "FEAT": 5, "PRO": 6, "CHAR": 7, "PARA": 8, "ENAT": 9, "CONPRI": 10, "MANS": 11, "BIOP": 12}
```
#### text2tech
- `id`: the instance id of this sentence, a `string` feature.
- `tokens`: the list of tokens of this sentence, a `list` of `string` features.
- `ner_tags`: the list of entity tags, a `list` of classification labels.
```json
{"O": 0, "Technological System": 1, "Method": 2, "Material": 3, "Technical Field": 4}
```
### Data Splits
| | Train | Dev | Test |
|--------|-------|------|------|
| fabner | 9435 | 2183 | 2064 |
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{DBLP:journals/jim/KumarS22,
author = {Aman Kumar and
Binil Starly},
title = {"FabNER": information extraction from manufacturing process science
domain literature using named entity recognition},
journal = {J. Intell. Manuf.},
volume = {33},
number = {8},
pages = {2393--2407},
year = {2022},
url = {https://doi.org/10.1007/s10845-021-01807-x},
doi = {10.1007/s10845-021-01807-x},
timestamp = {Sun, 13 Nov 2022 17:52:57 +0100},
biburl = {https://dblp.org/rec/journals/jim/KumarS22.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
### Contributions
Thanks to [@phucdev](https://github.com/phucdev) for adding this dataset.
annotations_creators:
- 专家生成
language_creators:
- 采集自现有文本
language:
- en
license:
- 其他
multilinguality:
- 单语
size_categories:
- 10000 < 样本量 < 100000
source_datasets: []
task_categories:
- 令牌分类(Token Classification)
task_ids:
- 命名实体识别(Named Entity Recognition,NER)
pretty_name: FabNER是一款面向命名实体识别的制造领域文本数据集
tags:
- 制造领域
- 2000-2020
# FabNER 数据集卡片
## 目录
- [目录](#目录)
- [数据集描述](#数据集描述)
- [数据集概述](#数据集概述)
- [支持任务与基准测试榜单](#支持任务与基准测试榜单)
- [语言](#语言)
- [数据集结构](#数据集结构)
- [数据实例](#数据实例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [构建初衷](#构建初衷)
- [源数据](#源数据)
- [标注信息](#标注信息)
- [个人与敏感信息](#个人与敏感信息)
- [数据使用注意事项](#数据使用注意事项)
- [数据集的社会影响](#数据集的社会影响)
- [偏差讨论](#偏差讨论)
- [其他已知局限性](#其他已知局限性)
- [附加信息](#附加信息)
- [数据集维护者](#数据集维护者)
- [许可信息](#许可信息)
- [引用信息](#引用信息)
- [贡献致谢](#贡献致谢)
## 数据集描述
- **主页**:[https://figshare.com/articles/dataset/Dataset_NER_Manufacturing_-_FabNER_Information_Extraction_from_Manufacturing_Process_Science_Domain_Literature_Using_Named_Entity_Recognition/14782407](https://figshare.com/articles/dataset/Dataset_NER_Manufacturing_-_FabNER_Information_Extraction_from_Manufacturing_Process_Science_Domain_Literature_Using_Named_Entity_Recognition/14782407)
- **论文**:["FabNER": 基于命名实体识别的制造工艺科学领域文献信息抽取](https://par.nsf.gov/servlets/purl/10290810)
- **下载数据集文件大小**:3.79 MB
- **生成后数据集大小**:6.27 MB
### 数据集概述
FabNER是一个面向命名实体识别(Named Entity Recognition,NER)的制造领域文本语料库,包含超过35万个单词。该语料库采集自Web of Science数据库中制造工艺科学研究领域的知名期刊的摘要集合。
为每个单词定义了分类/实体标签,分别为:材料(Material, MATE)、制造工艺(Manufacturing Process, MANP)、机器/设备(Machine/Equipment, MACEQ)、应用场景(Application, APPL)、特征属性(Features, FEAT)、力学性能(Mechanical Properties, PRO)、表征分析(Characterization, CHAR)、工艺参数(Parameters, PARA)、使能技术(Enabling Technology, ENAT)、概念/原理(Concept/Principles, CONPRI)、制造标准(Manufacturing Standards, MANS)以及生物医学(BioMedical, BIOP)。
所有类别的标注均采用`BIOES`格式:B代表起始(Beginning)、I代表中间(Intermediate)、O代表外部(Outside)、E代表结束(End)、S代表单个实体(Single)。
如需了解数据集的详细信息,请参考论文:["FabNER": 基于命名实体识别的制造工艺科学领域文献信息抽取](https://par.nsf.gov/servlets/purl/10290810)
### 支持任务与基准测试榜单
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 语言
本数据集的语言为英语。
## 数据集结构
### 数据实例
- **下载数据集文件大小**:3.79 MB
- **生成后数据集大小**:6.27 MB
训练集的一个示例如下:
json
{
"id": "0",
"tokens": ["Revealed", "the", "location-specific", "flow", "patterns", "and", "quantified", "the", "speeds", "of", "various", "types", "of", "flow", "."],
"ner_tags": [0, 0, 0, 46, 49, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}
### 数据字段
#### fabner配置
- `id`:该语句的实例ID,为字符串类型特征。
- `tokens`:该语句的Token列表,为字符串类型特征的列表。
- `ner_tags`:实体标签列表,为分类标签的列表。
json
{"O": 0, "B-MATE": 1, "I-MATE": 2, "E-MATE": 3, "S-MATE": 4, "B-MANP": 5, "I-MANP": 6, "E-MANP": 7, "S-MANP": 8, "B-MACEQ": 9, "I-MACEQ": 10, "E-MACEQ": 11, "S-MACEQ": 12, "B-APPL": 13, "I-APPL": 14, "E-APPL": 15, "S-APPL": 16, "B-FEAT": 17, "I-FEAT": 18, "E-FEAT": 19, "S-FEAT": 20, "B-PRO": 21, "I-PRO": 22, "E-PRO": 23, "S-PRO": 24, "B-CHAR": 25, "I-CHAR": 26, "E-CHAR": 27, "S-CHAR": 28, "B-PARA": 29, "I-PARA": 30, "E-PARA": 31, "S-PARA": 32, "B-ENAT": 33, "I-ENAT": 34, "E-ENAT": 35, "S-ENAT": 36, "B-CONPRI": 37, "I-CONPRI": 38, "E-CONPRI": 39, "S-CONPRI": 40, "B-MANS": 41, "I-MANS": 42, "E-MANS": 43, "S-MANS": 44, "B-BIOP": 45, "I-BIOP": 46, "E-BIOP": 47, "S-BIOP": 48}
#### fabner_bio配置
- `id`:该语句的实例ID,为字符串类型特征。
- `tokens`:该语句的Token列表,为字符串类型特征的列表。
- `ner_tags`:实体标签列表,为分类标签的列表。
json
{"O": 0, "B-MATE": 1, "I-MATE": 2, "B-MANP": 3, "I-MANP": 4, "B-MACEQ": 5, "I-MACEQ": 6, "B-APPL": 7, "I-APPL": 8, "B-FEAT": 9, "I-FEAT": 10, "B-PRO": 11, "I-PRO": 12, "B-CHAR": 13, "I-CHAR": 14, "B-PARA": 15, "I-PARA": 16, "B-ENAT": 17, "I-ENAT": 18, "B-CONPRI": 19, "I-CONPRI": 20, "B-MANS": 21, "I-MANS": 22, "B-BIOP": 23, "I-BIOP": 24}
#### fabner_simple配置
- `id`:该语句的实例ID,为字符串类型特征。
- `tokens`:该语句的Token列表,为字符串类型特征的列表。
- `ner_tags`:实体标签列表,为分类标签的列表。
json
{"O": 0, "MATE": 1, "MANP": 2, "MACEQ": 3, "APPL": 4, "FEAT": 5, "PRO": 6, "CHAR": 7, "PARA": 8, "ENAT": 9, "CONPRI": 10, "MANS": 11, "BIOP": 12}
#### text2tech配置
- `id`:该语句的实例ID,为字符串类型特征。
- `tokens`:该语句的Token列表,为字符串类型特征的列表。
- `ner_tags`:实体标签列表,为分类标签的列表。
json
{"O": 0, "Technological System": 1, "Method": 2, "Material": 3, "Technical Field": 4}
### 数据划分
| | 训练集 | 验证集 | 测试集 |
|--------|-------|------|------|
| fabner | 9435 | 2183 | 2064 |
## 数据集构建
### 构建初衷
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 源数据
#### 初始数据采集与标准化
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 源语言生产者是谁?
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 标注信息
#### 标注流程
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 标注人员是谁?
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 个人与敏感信息
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据使用注意事项
### 数据集的社会影响
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 偏差讨论
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 其他已知局限性
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 附加信息
### 数据集维护者
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 许可信息
[更多信息请参阅](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 引用信息
@article{DBLP:journals/jim/KumarS22,
author = {Aman Kumar and
Binil Starly},
title = {"FabNER": 基于命名实体识别的制造工艺科学领域文献信息抽取},
journal = {J. Intell. Manuf.},
volume = {33},
number = {8},
pages = {2393--2407},
year = {2022},
url = {https://doi.org/10.1007/s10845-021-01807-x},
doi = {10.1007/s10845-021-01807-x},
timestamp = {Sun, 13 Nov 2022 17:52:57 +0100},
biburl = {https://dblp.org/rec/journals/jim/KumarS22.bib},
bibsource = {dblp 计算机科学文献库, https://dblp.org}
}
### 贡献致谢
感谢 [@phucdev](https://github.com/phucdev) 为本数据集的添加工作。