FinSearchComp
收藏arXiv2025-09-16 更新2025-09-18 收录
下载链接:
https://randomtutu.github.io/FinSearchComp/
下载链接
链接失效反馈官方服务:
资源简介:
FinSearchComp是一个开源的端到端代理基准,用于评估开放域的金融搜索和推理能力。数据集包括三个任务:时效性数据获取、简单历史查询和复杂历史调查,共635个问题,覆盖全球和中国市场。数据集由70名专业金融专家进行标注,并通过多阶段的质量保证流程确保难度和可靠性。
FinSearchComp is an open-source end-to-end agent benchmark designed to evaluate open-domain financial search and reasoning capabilities. The dataset consists of three tasks: timely data acquisition, simple historical queries, and complex historical investigations, with a total of 635 questions covering both global and Chinese markets. It was annotated by 70 professional financial experts, and a multi-stage quality assurance process was adopted to ensure the difficulty and reliability of the dataset.
提供机构:
字节跳动
创建时间:
2025-09-16
原始信息汇总
FinSearchComp 数据集概述
数据集简介
FinSearchComp 是首个专为开放域金融搜索设计的开源基准测试,旨在评估金融数据检索与分析的核心技能,包括查找正确信号、核对和协调来源,以及在时间压力下形成有根据的判断。
数据集规模与结构
- 问题数量:635 个专家精心设计的问题,确保真实世界的相关性和准确性。
- 子任务类型:包含 3 个子任务(时间敏感数据获取、简单历史查询、复杂历史调查),覆盖全球和大中华区两个子集。
子任务详情
T1: 时间敏感数据获取
测试检索时间敏感、频繁更新的数据的能力。
- 示例:IBM 最新收盘价。
- 答案特性:动态变化,通过实时 API 查询获取。
T2: 简单历史查询
测试检索特定的、非时间敏感的历史事实的能力。
- 示例:截至 2020 年 9 月 27 日,星巴克的总资产是多少?
- 答案特性:允许四舍五入误差。
T3: 复杂历史调查
测试执行多步推理、聚合和计算的能力。
- 示例:从 2010 年 1 月到 2025 年 4 月,标普 500 指数在哪个月份出现了最大的单月涨幅?
- 答案特性:允许误差范围。
数据构建与来源
时间敏感数据获取
- 构建策略:金融专家设计实时数据问题,通过 API 调用代码获取实时数据点,并根据实际市场数据验证结果。
- 数据来源:证券交易所、外汇市场、商品交易平台,以及 Bloomberg、Reuters 和 Yahoo Finance 等金融数据提供商。
简单历史查询
- 构建策略:覆盖历史市场数据、公司财务和宏观统计数据,直接从官方来源和专业金融数据库收集。
- 数据来源:公司文件(10-K、10-Q、8-K 报告)、监管网站(SEC、FINRA、交易所网站)、专业金融数据库(Bloomberg Terminal、Refinitiv)和央行出版物。
复杂历史调查
- 构建策略:涉及需要从多个历史数据点进行计算和推理的金融数据,通过专家设计的真实场景和已验证的数据库表创建问题。
- 数据来源:多数据源交叉验证,确保准确性和教育价值。
答案验证机制
采用盲审模块进行答案验证。金融专家独立解决问题,如有分歧由高级专家仲裁,确保问题或答案的修改或废弃。
关键发现
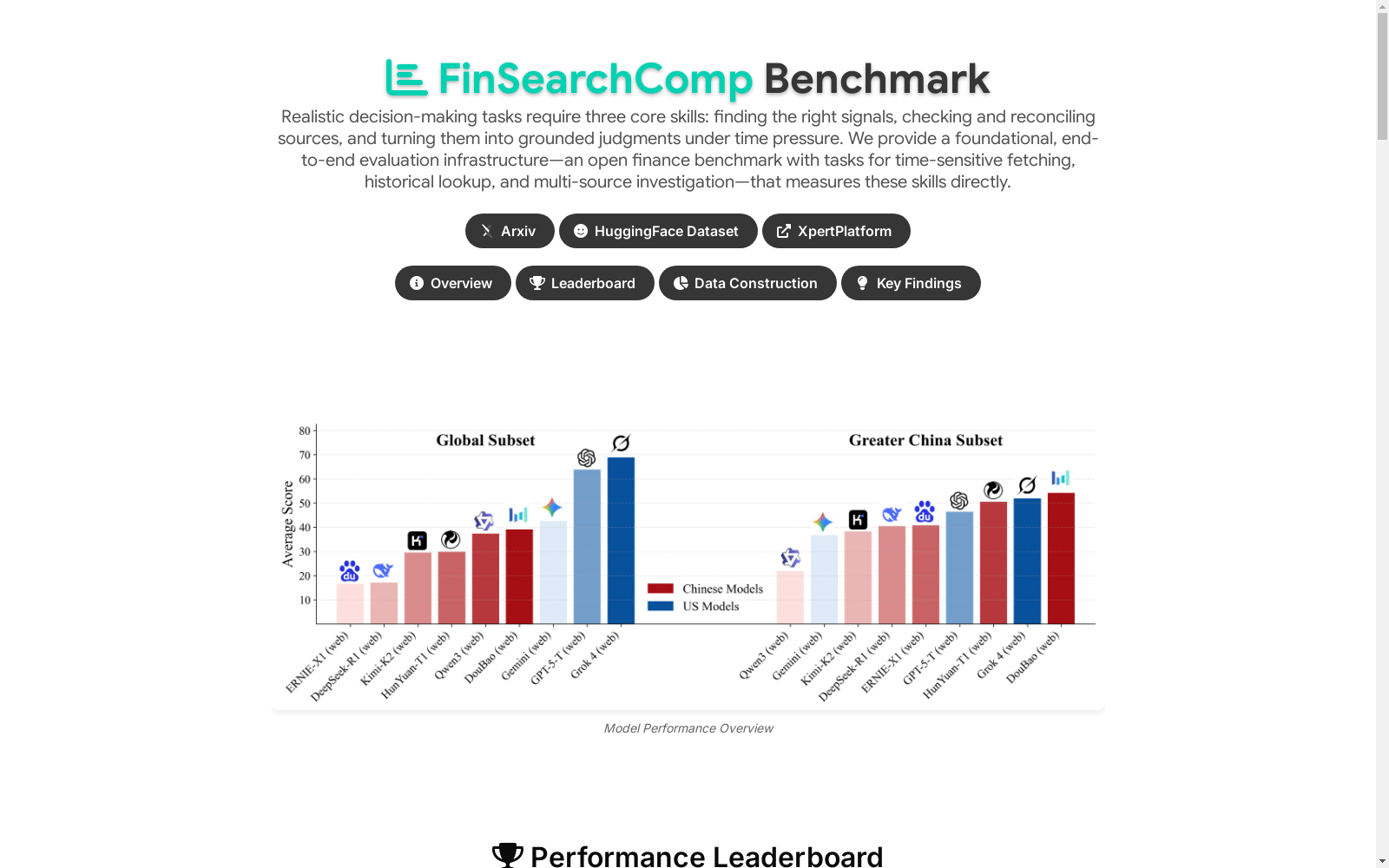
- 顶级模型表现挣扎:在时间敏感数据获取和简单历史查询任务中,顶级模型的平均准确率分别低于 60% 和 40%,在复杂历史调查任务中准确率暴跌至 20% 以下。
- 实时网络搜索必不可少:没有搜索工具的模型在时间敏感任务上得分为零,在历史数据搜索任务上得分极低。
- 强烈的区域偏见影响性能:中国模型在大中华区市场查询上表现出色,但在全球市场问题上落后于国际同行。
数据集可用性
整个数据集和评估套件公开可用。
搜集汇总
数据集介绍
构建方式
FinSearchComp数据集的构建过程深度融合了金融领域的专业实践,通过70位资深金融专家的多轮协作完成。构建策略依据任务类型差异进行定制化设计:时间敏感型数据通过实时API接口动态获取并设定资产类别特定的容错阈值;简单历史查询基于上市公司财报、监管机构文件及专业金融数据库进行权威数据提取,并采用多源交叉验证机制确保准确性;复杂历史调查则通过专家设计的真实业务场景问题与结构化表格标注相结合,形成需要多步推理的合成性问题。所有问题均经过严格的盲审仲裁流程与多阶段质量管控,最终形成涵盖全球与大中华区市场的635个高质量样本。
特点
该数据集的核心特征体现在其高度专业化与多维度复杂性。任务设计紧密贴合金融分析师实际工作流,包含时间敏感数据获取、简单历史查询与复杂历史调查三大类别,全面覆盖实时性验证、时点对齐与多源证据整合等核心能力。数据集采用双语构建并区分全球与大中华区子集,充分体现跨市场泛化需求。其评估体系创新性地引入基于规则指导的LLM评判机制,结合专家抽查验证,支持数值容错与动态答案验证,有效解决金融数据修订与多源差异问题。
使用方法
使用FinSearchComp需通过其开放的评估框架执行端到端智能体测试。评估时需配置外部工具调用能力(如网络搜索、金融API插件),系统会在市场收盘后统一执行时间敏感型任务以保证公平性。对于静态历史问题,采用预定义的误差容限与规则化评判标准。评估流程自动调用LLM评判器,将智能体输出与参考答案按预设规则(如数值范围匹配、单位一致性等)进行比对,并输出二进制评分。研究者可通过分析不同任务类型与市场子集的性能差异,深入诊断智能体在金融搜索与推理中的具体缺陷。
背景与挑战
背景概述
FinSearchComp由字节跳动Seed团队与哥伦比亚商学院于2025年联合推出,旨在填补金融领域开源代理基准的空白。该数据集聚焦于开放域金融搜索与推理任务,核心研究问题在于评估大型语言模型代理在实时、多源金融数据检索与复杂推理中的专业能力。通过模拟金融分析师的真实工作流程,涵盖全球与大中华区市场,其构建依托70名金融专家的标注与多阶段质控流程,对金融智能代理的发展具有里程碑意义。
当前挑战
FinSearchComp解决的领域挑战在于金融搜索需兼顾时效性、多源证据整合与领域知识推理,例如实时股价查询需对抗数据陈旧性,而跨周期财务分析需处理会计准则差异。构建过程中,挑战包括时间敏感数据的动态验证困难、金融指标定义歧义消除(如PE-TTM计算标准不一),以及跨市场数据源的一致性保障,需通过专家交叉验证与容错评分机制克服。
常用场景
经典使用场景
在金融信息检索与推理领域,FinSearchComp数据集被广泛用于评估大语言模型代理在开放域金融搜索任务中的表现。该数据集通过模拟真实金融分析师的工作流程,设计了时间敏感数据获取、简单历史查询和复杂历史调查三类任务,要求模型结合实时API调用、多源证据整合与时间序列推理能力完成端到端评估。其经典应用场景包括测试模型在动态市场环境下的信息新鲜度管理、跨来源数据对齐与冲突解决能力,已成为衡量智能代理在高压金融决策环境中可靠性的黄金标准。
实际应用
在实际金融业务中,FinSearchComp直接服务于投资银行、资产管理公司与金融科技平台的智能决策系统开发。该数据集支撑的交易监控模块可实时验证股价、汇率等动态数据准确性;投研自动化工具利用其历史查询任务实现财报关键指标的高效提取;风险管理系统则依赖复杂调查任务评估多源数据融合能力。例如,对冲基金通过该基准测试代理对跨国企业财务数据的跨市场对齐能力,而监管科技公司则借鉴其时间敏感性问题设计市场异常波动监测方案,显著提升了金融从业者在高频数据处理与宏观趋势分析中的操作效率。
衍生相关工作
FinSearchComp的发布催生了多个重要研究方向,包括基于其任务结构的金融插件优化研究(如YuanBao平台的专用数据接口)、跨市场泛化评估框架(如针对新兴市场数据的扩展基准)以及混合检索-推理架构的创新。该数据集启发的典型工作包括:对Grok-4与GPT-5-Thinking等模型的搜索深度分析,揭示了时间戳对齐错误与来源冲突解决的关键瓶颈;后续研究进一步探索了多模态金融文档(如财报表格与新闻文本)的联合检索方案,以及基于强化学习的工具调用策略优化,推动了金融领域Agent评估从静态问答向动态决策的重大范式转变。
以上内容由遇见数据集搜集并总结生成


