TabularDataHW1
收藏Hugging Face2025-09-16 更新2025-09-17 收录
下载链接:
https://huggingface.co/datasets/emkessle/TabularDataHW1
下载链接
链接失效反馈官方服务:
资源简介:
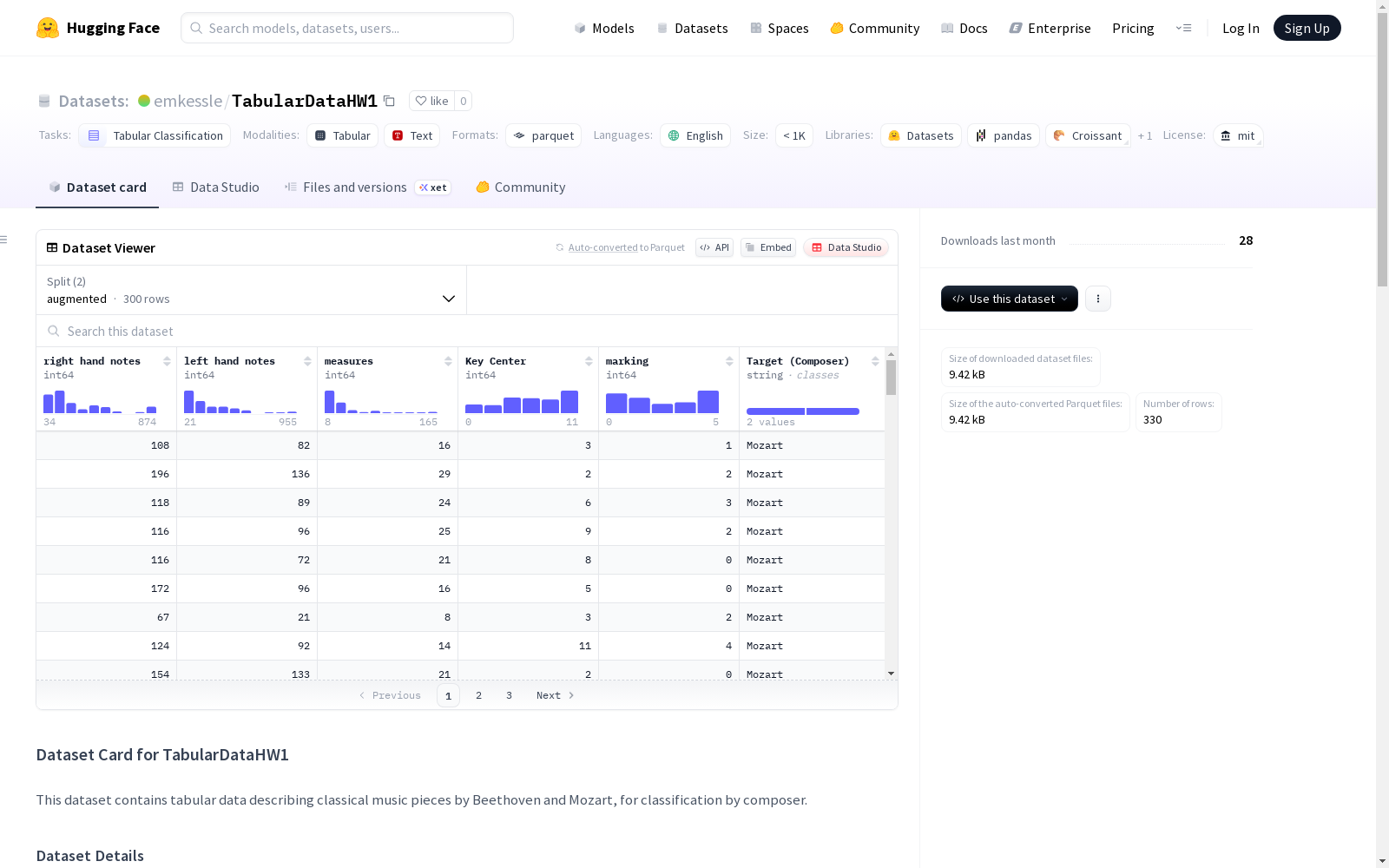
这是一个包含古典音乐作品信息的表格数据集,用于区分作曲家是莫扎特还是贝多芬。包含30首古典钢琴曲的相关数据,如右手和左手音符数、小节数、调中心和音乐标记等。
创建时间:
2025-09-15
原始信息汇总
TabularDataHW1 数据集概述
数据集基本信息
- 名称:TabularDataHW1
- 创建者:Ethan Kessler
- 语言:英语
- 许可证:MIT
- 多语言性:单语
- 规模:100<n<1K
- 任务类别:表格分类
数据集描述
该数据集包含描述贝多芬和莫扎特古典音乐作品的表格数据,用于按作曲家进行分类。原始分割包含30首古典钢琴曲,用于预测作曲家是莫扎特还是贝多芬。
数据集结构
测量参数
- 右手音符数量
- 左手音符数量
- 小节数量
- 调性中心
- 标记数据
标签编码
调性中心标签
- "A": 0
- "Bb": 1
- "B": 2
- "C": 3
- "Db": 4
- "D": 5
- "Eb": 6
- "E": 7
- "F": 8
- "Gb": 9
- "G": 10
- "Ab": 11
标记数据标签
- 0 = Minuet
- 1 = Allegro
- 2 = Andante
- 3 = Moderato
- 4 = Allegretto
- 5 = Dance
数据增强
- 120行Jittering增强
- 90行Mixup增强
- 90行CTGAN增强
- 303行EDA增强
- 202行字符级噪声增强
- 303行回译增强
- 202行释义增强
数据收集与处理
数据由数据集作者手动收集,使用Microsoft Copilot的建议选择作品,并使用开源乐谱进行分析。Google Gemini仅用于代码调试。
使用目的
直接用途
用于训练表格数据的分类器模型
超出范围用途
需要更多信息
注意事项
用户应了解数据集的风险、偏见和局限性。需要更多信息以提供进一步建议。
搜集汇总
数据集介绍
构建方式
在音乐信息检索领域,TabularDataHW1数据集源于对贝多芬与莫扎特古典钢琴曲目的系统性分析。原始数据通过人工采集30首经典作品,依托开源乐谱资源提取右手音符数、左手音符数、小节数、调性中心与表情标记五大特征维度,并采用Jittering、Mixup和CTGAN三种数据增强技术分别生成120行、90行与90行合成样本,显著扩充了数据规模。
特点
该数据集的核心价值体现在其多维度的音乐特征编码体系。调性中心采用十二进制数值映射(如C=3, G=10),表情标记则对应六类演奏术语的数字化分类(如快板=1,行板=2)。数据分布涵盖303行EDA增强样本、202行字符级噪声数据以及505行回译与改写文本,形成了兼具统计规律与语义复杂性的混合特征空间。
使用方法
作为表格分类任务的基准数据集,研究者可通过加载标准化格式的CSV文件直接调用特征矩阵与作曲家标签。建议采用分层抽样保持类别平衡,调性中心与表情标记字段需进行独热编码处理,增强后的数据适合用于决策树、梯度提升机等分类模型的性能验证,同时需注意数据增强可能引入的分布偏移问题。
背景与挑战
背景概述
TabularDataHW1数据集由Ethan Kessler创建,专注于古典音乐作品的表格化分类研究,旨在通过机器学习方法区分贝多芬与莫扎特的钢琴作品。该数据集采集了30首经典钢琴曲目的五项核心特征,包括左右手音符数量、小节数、调性中心及演奏标记数据,并采用数据增强技术扩展样本规模。其研究价值在于探索结构化数据在音乐风格识别领域的应用潜力,为音乐信息检索与计算音乐学提供了新的实验基准。
当前挑战
该数据集需解决音乐作品分类中风格特征的高维稀疏性问题,例如调性标记与演奏符号的语义离散化表征挑战。构建过程中面临原始样本量有限的约束,需通过EDA、回译与生成对抗网络等技术进行数据增强,但增强数据的分布一致性及噪声控制仍需验证。此外,手工标注过程中音乐术语的标准化与多源乐谱数据的异构性亦增加了数据清洗与对齐的复杂度。
常用场景
经典使用场景
在音乐信息检索领域,TabularDataHW1数据集通过结构化特征为古典音乐作品分析提供了重要支撑。该数据集最典型的应用场景是训练机器学习模型进行作曲家分类,研究者利用左右手音符数量、小节数、调性中心和音乐标记等五个维度的特征,构建贝多芬与莫扎特作品的自动识别系统。这种基于表格数据的分类方法为音乐风格量化研究开辟了新途径。
解决学术问题
该数据集有效解决了音乐学中作曲家风格量化分析的难题。通过将音乐作品转化为结构化数据,研究者能够客观比较不同作曲家的创作特征,突破传统主观分析的局限性。这种数据驱动的方法为音乐风格研究提供了可量化的科学依据,显著提升了音乐作品 attribution 研究的精确度和可重复性,对计算音乐学领域的发展具有重要推动作用。
衍生相关工作
该数据集催生了多项重要的衍生研究,特别是在数据增强技术的应用方面。研究者基于原始数据开发了包括Jittering、Mixup和CTGAN等多种数据扩充方法,这些技术显著提升了小样本表格数据的建模效果。后续工作进一步探索了EDA、回译和释义等文本增强技术在结构化数据上的适应性,为表格数据增强领域提供了有价值的参考案例。
以上内容由遇见数据集搜集并总结生成


