tunis-ai/arabic_speech_corpus
收藏Hugging Face2024-05-04 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/tunis-ai/arabic_speech_corpus
下载链接
链接失效反馈官方服务:
资源简介:
---
pretty_name: Arabic Speech Corpus
annotations_creators:
- expert-generated
language_creators:
- crowdsourced
language:
- ar
license:
- cc-by-4.0
multilinguality:
- monolingual
paperswithcode_id: arabic-speech-corpus
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- automatic-speech-recognition
task_ids: []
train-eval-index:
- config: clean
task: automatic-speech-recognition
task_id: speech_recognition
splits:
train_split: train
eval_split: test
col_mapping:
file: path
text: text
metrics:
- type: wer
name: WER
- type: cer
name: CER
dataset_info:
features:
- name: file
dtype: string
- name: text
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 48000
- name: phonetic
dtype: string
- name: orthographic
dtype: string
config_name: clean
splits:
- name: train
num_bytes: 1002365
num_examples: 1813
- name: test
num_bytes: 65784
num_examples: 100
download_size: 1192302846
dataset_size: 1068149
---
# Dataset Card for Arabic Speech Corpus
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Arabic Speech Corpus](http://en.arabicspeechcorpus.com/)
- **Repository:** [Needs More Information]
- **Paper:** [Modern standard Arabic phonetics for speech synthesis](http://en.arabicspeechcorpus.com/Nawar%20Halabi%20PhD%20Thesis%20Revised.pdf)
- **Leaderboard:** [Paperswithcode Leaderboard][Needs More Information]
- **Point of Contact:** [Nawar Halabi](mailto:nawar.halabi@gmail.com)
### Dataset Summary
This Speech corpus has been developed as part of PhD work carried out by Nawar Halabi at the University of Southampton. The corpus was recorded in south Levantine Arabic (Damascian accent) using a professional studio. Synthesized speech as an output using this corpus has produced a high quality, natural voice.
### Supported Tasks and Leaderboards
[Needs More Information]
### Languages
The audio is in Arabic.
## Dataset Structure
### Data Instances
A typical data point comprises the path to the audio file, usually called `file` and its transcription, called `text`.
An example from the dataset is:
```
{
'file': '/Users/username/.cache/huggingface/datasets/downloads/extracted/baebe85e2cb67579f6f88e7117a87888c1ace390f4f14cb6c3e585c517ad9db0/arabic-speech-corpus/wav/ARA NORM 0002.wav',
'audio': {'path': '/Users/username/.cache/huggingface/datasets/downloads/extracted/baebe85e2cb67579f6f88e7117a87888c1ace390f4f14cb6c3e585c517ad9db0/arabic-speech-corpus/wav/ARA NORM 0002.wav',
'array': array([-0.00048828, -0.00018311, -0.00137329, ..., 0.00079346, 0.00091553, 0.00085449], dtype=float32),
'sampling_rate': 48000},
'orthographic': 'waraj~aHa Alt~aqoriyru Al~a*iy >aEad~ahu maEohadu >aboHaA^i haDabapi Alt~ibiti fiy Alo>akaAdiymiy~api AlS~iyniy~api liloEuluwmi - >ano tasotamir~a darajaAtu AloHaraArapi wamusotawayaAtu Alr~uTuwbapi fiy Alo<irotifaAEi TawaAla ha*aA Aloqarono',
'phonetic': "sil w a r a' jj A H a tt A q r ii0' r u0 ll a * i0 < a E a' dd a h u0 m a' E h a d u0 < a b H aa' ^ i0 h A D A' b a t i0 tt i1' b t i0 f i0 l < a k aa d ii0 m ii0' y a t i0 SS II0 n ii0' y a t i0 l u0 l E u0 l uu0' m i0 sil < a' n t a s t a m i0' rr a d a r a j aa' t u0 l H a r aa' r a t i0 w a m u0 s t a w a y aa' t u0 rr U0 T UU0' b a t i0 f i0 l Ah i0 r t i0 f aa' E i0 T A' w A l a h aa' * a l q A' r n sil",
'text': '\ufeffwaraj~aHa Alt~aqoriyru Al~aTHiy >aEad~ahu maEohadu >aboHaA^i haDabapi Alt~ibiti fiy Alo>akaAdiymiy~api AlS~iyniy~api liloEuluwmi - >ano tasotamir~a darajaAtu AloHaraArapi wamusotawayaAtu Alr~uTuwbapi fiy Alo<irotifaAEi TawaAla haTHaA Aloqarono'
}
```
### Data Fields
- file: A path to the downloaded audio file in .wav format.
- audio: A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
- text: the transcription of the audio file.
- phonetic: the transcription in phonentics format.
- orthographic: the transcriptions written in orthographic format.
### Data Splits
| | Train | Test |
| ----- | ----- | ---- |
| dataset | 1813 | 100 |
## Dataset Creation
### Curation Rationale
The corpus was created with Speech Synthesis as the main application in mind. Although it has been used as part of a larger corpus for speech recognition and speech denoising. Here are some explanations why the corpus was built the way it is:
* Corpus size: Budget limitations and the research goal resulted in the decision not to gather more data. The goal was to show that high quality speech synthesis is possible with smaller corpora.
* Phonetic diversity: Just like with many corpora, the phonetic diversity was acheived using greedy methods. Start with a core set of utterances and add more utterances which contribute to adding more phonetic diversity the most iterativly. The measure of diversity is based on the diphone frequency.
* Content: News, sports, economics, fully diacritised content from the internet was gathered. The choice of utterances was random to avoid copyright issues. Because of corpus size, acheiving diversity of content type was difficult and was not the goal.
* Non-sense utterances: The corpus contains a large set of utterances that are generated computationally to compensate for the diphones missing in the main part of the corpus. The usefullness of non-sense utterances was not proven in the PhD thesis.
* The talent: The voice talent had a Syrian dialect from Damascus and spoke in formal Arabic.
Please refer to [PhD thesis](#Citation-Information) for more detailed information.
### Source Data
#### Initial Data Collection and Normalization
News, sports, economics, fully diacritised content from the internet was gathered. The choice of utterances was random to avoid copyright issues. Because of corpus size, acheiving diversity of content type was difficult and was not the goal. We were restricted to content which was fully diacritised to make the annotation process easier.
Just like with many corpora, the phonetic diversity was acheived using greedy methods. Start with a core set of utterances and add more utterances which contribute to adding more phonetic diversity the most iterativly. The measure of diversity is based on the diphone frequency.
Please refer to [PhD thesis](#Citation-Information).
#### Who are the source language producers?
Please refer to [PhD thesis](#Citation-Information).
### Annotations
#### Annotation process
Three annotators aligned audio with phonemes with the help of HTK forced alignment. They worked on overlapping parts as well to assess annotator agreement and the quality of the annotations. The entire corpus was checked by human annotators.
Please refer to [PhD thesis](#Citation-Information).
#### Who are the annotators?
Nawar Halabi and two anonymous Arabic language teachers.
### Personal and Sensitive Information
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in this dataset. The voice talent agreed in writing for their voice to be used in speech technologies as long as they stay anonymous.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
The corpus was recorded in south Levantine Arabic (Damascian accent) using a professional studio by Nawar Halabi.
### Licensing Information
[CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)
### Citation Information
```
@phdthesis{halabi2016modern,
title={Modern standard Arabic phonetics for speech synthesis},
author={Halabi, Nawar},
year={2016},
school={University of Southampton}
}
```
### Contributions
This dataset was created by:
* Nawar Halabi [@nawarhalabi](https://github.com/nawarhalabi) main creator and annotator.
* Two anonymous Arabic langauge teachers as annotators.
* One anonymous voice talent.
* Thanks to [@zaidalyafeai](https://github.com/zaidalyafeai) for adding this dataset.
数据集展示名称: Arabic Speech Corpus(阿拉伯语语音语料库)
标注生成方式:
- expert-generated(专家生成)
语言生成方式:
- crowdsourced(众包生成)
语言:
- ar(阿拉伯语)
许可协议:
- cc-by-4.0(CC BY 4.0)
多语言属性:
- monolingual(单语言)
PapersWithCode 编号: arabic-speech-corpus
样本规模类别:
- 1K<n<10K(1000<n<10000)
源数据集:
- original(原始数据集)
任务类别:
- automatic-speech-recognition(自动语音识别)
任务子项: []
训练-评估索引:
- 配置: clean
任务: automatic-speech-recognition(自动语音识别)
任务ID: speech_recognition(语音识别)
拆分:
训练集: train
评估集: test
列映射:
file: path
text: text
评估指标:
- 类型: wer(词错误率, Word Error Rate)
名称: WER
- 类型: cer(字符错误率, Character Error Rate)
名称: CER
数据集信息:
特征:
- 名称: file
数据类型: 字符串
- 名称: text
数据类型: 字符串
- 名称: audio
数据类型:
音频:
采样率: 48000
- 名称: phonetic
数据类型: 字符串
- 名称: orthographic
数据类型: 字符串
配置名称: clean
拆分:
- 名称: train
字节数: 1002365
样本数: 1813
- 名称: test
字节数: 65784
样本数: 100
下载大小: 1192302846
数据集总大小: 1068149
---
# 阿拉伯语语音语料库数据集卡片
## 目录
- [数据集概述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据拆分](#data-splits)
- [数据集构建](#dataset-creation)
- [数据集构建初衷](#curation-rationale)
- [源数据](#source-data)
- [标注信息](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献者](#contributions)
## 数据集概述
- **主页**:[阿拉伯语语音语料库](http://en.arabicspeechcorpus.com/)
- **代码仓库**:[需补充更多信息]
- **相关论文**:[面向语音合成的现代标准阿拉伯语语音学](http://en.arabicspeechcorpus.com/Nawar%20Halabi%20PhD%20Thesis%20Revised.pdf)
- **排行榜**:[PapersWithCode 排行榜][需补充更多信息]
- **联系人**:[Nawar Halabi](mailto:nawar.halabi@gmail.com)
### 数据集摘要
本语音语料库是南安普顿大学Nawar Halabi博士研究工作的成果。该语料库采用专业录音棚录制,使用南黎凡特阿拉伯语(大马士革口音)。使用该语料库合成的语音可生成高质量、自然的人声。
### 支持任务与排行榜
[需补充更多信息]
### 语言
音频内容为阿拉伯语。
## 数据集结构
### 数据实例
典型的数据样本包含音频文件路径(通常命名为`file`)及其转录文本(命名为`text`)。数据集的一个示例如下:
{
'file': '/Users/username/.cache/huggingface/datasets/downloads/extracted/baebe85e2cb67579f6f88e7117a87888c1ace390f4f14cb6c3e585c517ad9db0/arabic-speech-corpus/wav/ARA NORM 0002.wav',
'audio': {'path': '/Users/username/.cache/huggingface/datasets/downloads/extracted/baebe85e2cb67579f6f88e7117a87888c1ace390f4f14cb6c3e585c517ad9db0/arabic-speech-corpus/wav/ARA NORM 0002.wav',
'array': array([-0.00048828, -0.00018311, -0.00137329, ..., 0.00079346, 0.00091553, 0.00085449], dtype=float32),
'sampling_rate': 48000},
'orthographic': 'waraj~aHa Alt~aqoriyru Al~a*iy >aEad~ahu maEohadu >aboHaA^i haDabapi Alt~ibiti fiy Alo>akaAdiymiy~api AlS~iyniy~api liloEuluwmi - >ano tasotamir~a darajaAtu AloHaraArapi wamusotawayaAtu Alr~uTuwbapi fiy Alo<irotifaAEi TawaAla ha*aA Aloqarono',
'phonetic': "sil w a r a' jj A H a tt A q r ii0' r u0 ll a * i0 < a E a' dd a h u0 m a' E h a d u0 < a b H aa' ^ i0 h A D A' b a t i0 tt i1' b t i0 f i0 l < a k aa d ii0 m ii0' y a t i0 SS II0 n ii0' y a t i0 l u0 l E u0 l uu0' m i0 sil < a' n t a s t a m i0' rr a d a r a j aa' t u0 l H a r aa' r a t i0 w a m u0 s t a w a y aa' t u0 rr U0 T UU0' b a t i0 f i0 l Ah i0 r t i0 f aa' E i0 T A' w A l a h aa' * a l q A' r n sil",
'text': 'ufeffwaraj~aHa Alt~aqoriyru Al~aTHiy >aEad~ahu maEohadu >aboHaA^i haDabapi Alt~ibiti fiy Alo>akaAdiymiy~api AlS~iyniy~api liloEuluwmi - >ano tasotamir~a darajaAtu AloHaraArapi wamusotawayaAtu Alr~uTuwbapi fiy Alo<irotifaAEi TawaAla haTHaA Aloqarono'
}
### 数据字段
- `file`:下载得到的.wav格式音频文件的路径。
- `audio`:包含音频文件路径、解码后的音频数组以及采样率的字典。请注意,当访问音频列时:`dataset[0]["audio"]`会自动对音频文件进行解码并重采样至`dataset.features["audio"].sampling_rate`指定的采样率。批量解码和重采样大量音频文件会耗费大量时间,因此建议优先通过样本索引访问,即**始终优先使用`dataset[0]["audio"]`而非`dataset["audio"][0]`**。
- `text`:音频文件的转录文本。
- `phonetic`:采用语音学格式的转录文本。
- `orthographic`:采用正字法格式的转录文本。
### 数据拆分
| | 训练集 | 测试集 |
| ----- | ----- | ---- |
| 数据集 | 1813 | 100 |
## 数据集构建
### 数据集构建初衷
本语料库最初以语音合作为核心应用场景而构建,不过也已被用于更大规模的语音识别与语音去噪相关研究中。以下为该语料库构建方式的相关说明:
1. **语料库规模**:受预算限制与研究目标影响,最终未采集更多数据。本研究旨在证明小型语料库即可实现高质量语音合成。
2. **语音多样性**:与多数语料库类似,本语料库通过贪心算法实现语音多样性:以核心语句集为基础,迭代添加对提升语音多样性贡献最大的语句,多样性衡量基于双音素(diphone)出现频率。
3. **内容来源**:采集自互联网的新闻、体育、经济领域全标音文本。为规避版权问题,语句选择采用随机方式。受语料库规模限制,未能实现内容类型的多样化,且这也并非本研究的目标。
4. **无意义语句**:语料库包含大量由计算机生成的无意义语句,用于补充主语料集中缺失的双音素。本博士论文中未验证无意义语句的实际效用。
5. **配音人员**:配音人员为具有大马士革方言背景的叙利亚人,使用标准阿拉伯语进行录制。
详细信息请参阅[博士论文](#引用信息)。
### 源数据
#### 初始数据采集与标准化
采集自互联网的新闻、体育、经济领域全标音文本。为规避版权问题,语句选择采用随机方式。受语料库规模限制,未能实现内容类型的多样化,且这也并非本研究的目标。为简化标注流程,本研究仅使用全标音内容。
与多数语料库类似,本语料库通过贪心算法实现语音多样性:以核心语句集为基础,迭代添加对提升语音多样性贡献最大的语句,多样性衡量基于双音素出现频率。
详细信息请参阅[博士论文](#引用信息)。
#### 源语言使用者信息
详细信息请参阅[博士论文](#引用信息)。
### 标注信息
#### 标注流程
三名标注人员借助HTK(隐马尔可夫模型工具包,Hidden Markov Model Toolkit)强制对齐工具完成音频与音素的对齐。同时,他们对重叠部分进行标注以评估标注者一致性与标注质量。整个语料库均由人工标注人员进行审核。
详细信息请参阅[博士论文](#引用信息)。
#### 标注人员信息
Nawar Halabi与两名匿名阿拉伯语教师。
### 个人与敏感信息
本数据集由自愿在线贡献语音的人士录制而成。请勿尝试识别数据集中的说话者身份。配音人员已书面同意其语音可用于语音技术研究,且需保持匿名。
## 数据集使用注意事项
### 数据集的社会影响
[需补充更多信息]
### 偏差讨论
[需补充更多信息]
### 其他已知局限性
[需补充更多信息]
## 附加信息
### 数据集维护者
本语料库由Nawar Halabi采用专业录音棚录制,使用南黎凡特阿拉伯语(大马士革口音)。
### 许可信息
[CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)
### 引用信息
@phdthesis{halabi2016modern,
title={Modern standard Arabic phonetics for speech synthesis},
author={Halabi, Nawar},
year={2016},
school={University of Southampton}
}
*注:此处论文标题已译为《面向语音合成的现代标准阿拉伯语语音学》,学校译为南安普顿大学。*
### 贡献者
本数据集由以下人员创建:
* Nawar Halabi [@nawarhalabi](https://github.com/nawarhalabi):主要创建者与标注者。
* 两名匿名阿拉伯语教师:标注人员。
* 一名匿名配音人员。
* 感谢[@zaidalyafeai](https://github.com/zaidalyafeai)添加本数据集。
提供机构:
tunis-ai
原始信息汇总
阿拉伯语音语料库
数据集概述
- 名称: Arabic Speech Corpus
- 标注创建者: 专家生成
- 语言创建者: 众包
- 语言: 阿拉伯语
- 许可证: CC BY 4.0
- 多语言性: 单语种
- 大小类别: 1K<n<10K
- 源数据集: 原始数据
- 任务类别: 自动语音识别
- 训练-评估索引:
- 配置: clean
- 任务: 自动语音识别
- 任务ID: speech_recognition
- 分割:
- 训练分割: train
- 评估分割: test
- 列映射:
- file: path
- text: text
- 评估指标:
- 类型: wer 名称: WER
- 类型: cer 名称: CER
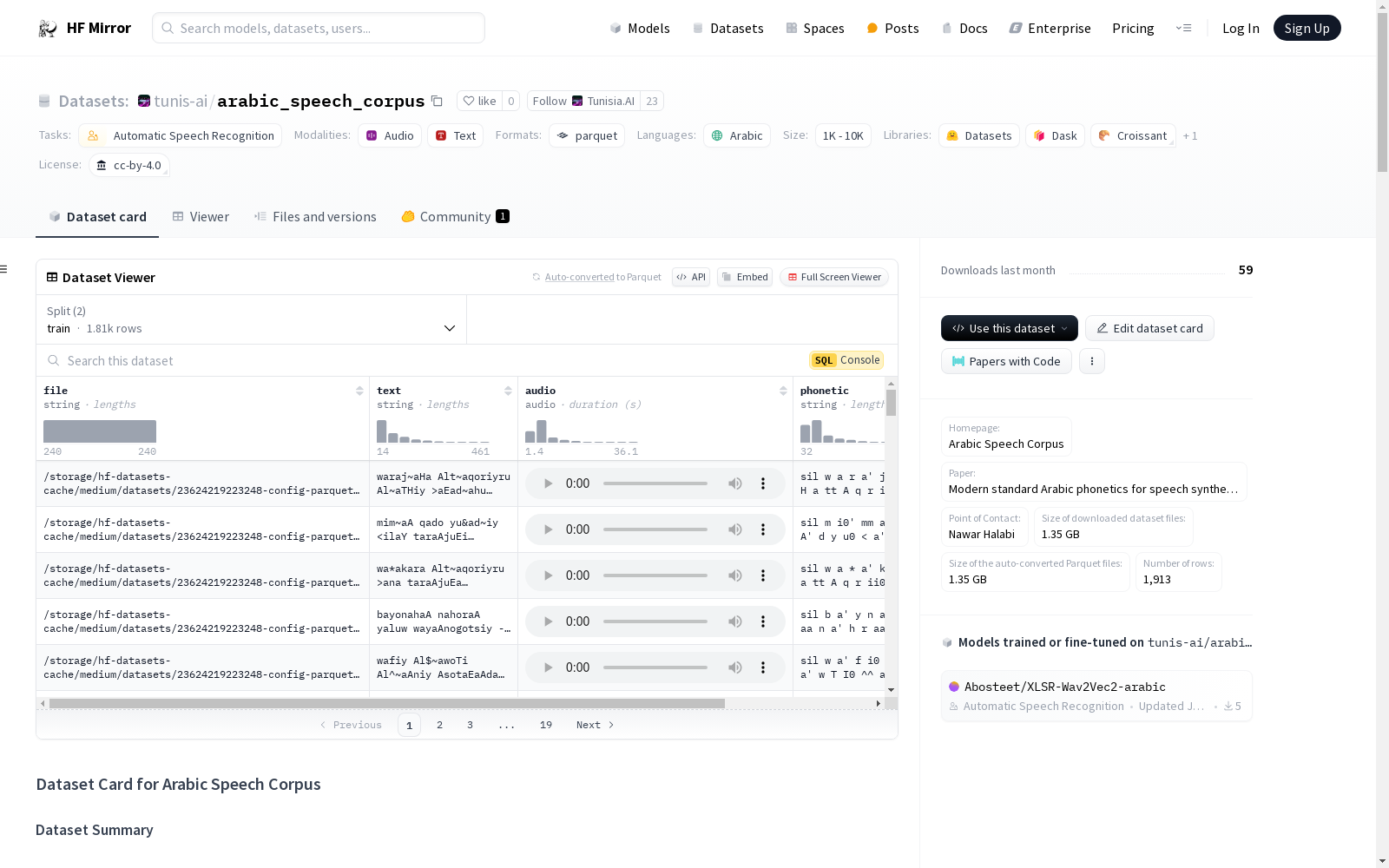
数据集结构
- 特征:
- name: file dtype: string
- name: text dtype: string
- name: audio dtype: audio: sampling_rate: 48000
- name: phonetic dtype: string
- name: orthographic dtype: string
- 配置名称: clean
- 分割:
- name: train num_bytes: 1002365 num_examples: 1813
- name: test num_bytes: 65784 num_examples: 100
- 下载大小: 1192302846
- 数据集大小: 1068149
数据实例
一个典型的数据点包括音频文件的路径(通常称为 file)及其转录文本(称为 text)。
数据字段
- file: 下载的音频文件的路径,格式为.wav。
- audio: 包含下载的音频文件路径、解码的音频数组和采样率的字典。
- text: 音频文件的转录文本。
- phonetic: 音素格式的转录。
- orthographic: 正字法格式的转录。
数据分割
| Train | Test | |
|---|---|---|
| 数据集 | 1813 | 100 |
搜集汇总
数据集介绍
构建方式
该数据集由Nawar Halabi在南安普顿大学攻读博士学位期间创建,旨在用于语音合成研究。数据集的构建过程包括从互联网上收集新闻、体育和经济等领域的全音标内容,并通过随机选择避免版权问题。由于预算限制和研究目标,数据集规模较小,旨在展示高质量语音合成在小规模语料库中的可行性。通过贪婪方法逐步增加发音多样性,基于双音节频率进行多样性评估。此外,数据集还包含大量计算生成的无意义语句,以弥补主要部分中缺失的双音节。
特点
阿拉伯语音语料库的主要特点在于其高质量的语音合成输出,能够产生自然流畅的语音。数据集包含音频文件路径、音频数组、采样率、音标转录、正字法转录和文本转录等多个字段,提供了丰富的语音信息。此外,数据集在南黎凡特阿拉伯语(大马士革口音)中录制,由专业录音室完成,确保了语音的清晰度和准确性。
使用方法
使用该数据集时,用户可以通过访问音频列来自动解码和重采样音频文件,确保音频处理的效率和准确性。数据集分为训练集和测试集,分别包含1813和100个样本。用户可以通过访问数据集的特征字段,如文件路径、音频数组、文本转录等,进行自动语音识别等任务。此外,数据集还提供了音标和正字法转录,便于进行更深入的语音分析和处理。
背景与挑战
背景概述
阿拉伯语音语料库(Arabic Speech Corpus)是由Nawar Halabi在南安普顿大学攻读博士学位期间创建的,旨在支持语音合成技术的研究。该语料库录制于专业的录音室,使用南黎凡特阿拉伯语(大马士革口音),旨在生成高质量的自然语音。语料库的构建不仅展示了小规模语料库在语音合成中的潜力,还为语音识别和语音去噪等领域的研究提供了宝贵的资源。该语料库的核心研究问题是如何在小规模数据集上实现高质量的语音合成,这一研究对阿拉伯语语音处理领域具有重要影响。
当前挑战
阿拉伯语音语料库在构建过程中面临多项挑战。首先,预算限制和研究目标决定了数据集的规模,如何在有限的数据量下实现高质量的语音合成是一个主要挑战。其次,语料库的语音多样性通过迭代方法实现,确保了音素多样性,但这一过程复杂且耗时。此外,内容多样性的限制也是一个挑战,由于数据集规模较小,难以涵盖多种内容类型。最后,语料库中包含的非意义语音数据的有效性尚未得到充分验证,这为未来的研究提出了新的问题。
常用场景
经典使用场景
阿拉伯语音数据集(Arabic Speech Corpus)在语音合成领域中占据着重要地位。其经典使用场景主要集中在现代标准阿拉伯语的语音合成任务上,通过提供高质量的语音数据和相应的文本转录,该数据集能够显著提升合成语音的自然度和清晰度。研究者们利用这一数据集训练和优化语音合成模型,以生成更加逼真和流畅的阿拉伯语语音输出。
实际应用
在实际应用中,阿拉伯语音数据集被广泛用于开发和优化阿拉伯语的语音助手、语音翻译系统和语音教育工具。通过使用这一数据集,开发者能够构建更加准确和自然的语音交互系统,提升用户体验。此外,该数据集还支持在阿拉伯语地区的语音广播、语音导航和语音娱乐等领域的应用,推动了语音技术在阿拉伯语社区的普及和应用。
衍生相关工作
基于阿拉伯语音数据集,研究者们开展了一系列相关工作,包括但不限于阿拉伯语语音合成模型的优化、语音识别系统的改进以及语音增强技术的研究。这些工作不仅提升了阿拉伯语语音技术的性能,还为其他语言的语音研究提供了借鉴和参考。此外,该数据集还促进了跨语言语音技术的研究,推动了多语言语音处理技术的发展。
以上内容由遇见数据集搜集并总结生成


