Lipophilicity
收藏moleculenet.org2024-11-01 收录
下载链接:
https://moleculenet.org/datasets-1
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含超过4000个化合物及其对应的实验测定的脂溶性(LogD)值。脂溶性是药物发现中的一个关键性质,因为它影响药物在体内的分布和代谢。数据集中的每个条目都包括化合物的SMILES表示、实验测定的LogD值、分子量、分子表面积等属性。
This dataset contains over 4,000 compounds along with their experimentally determined lipophilicity (LogD) values. Lipophilicity is a critical property in drug discovery, as it affects the distribution and metabolism of drugs in the human body. Each entry in the dataset includes attributes such as the compound's SMILES representation, experimentally measured LogD value, molecular weight, molecular surface area, and other relevant properties.
提供机构:
moleculenet.org
搜集汇总
数据集介绍
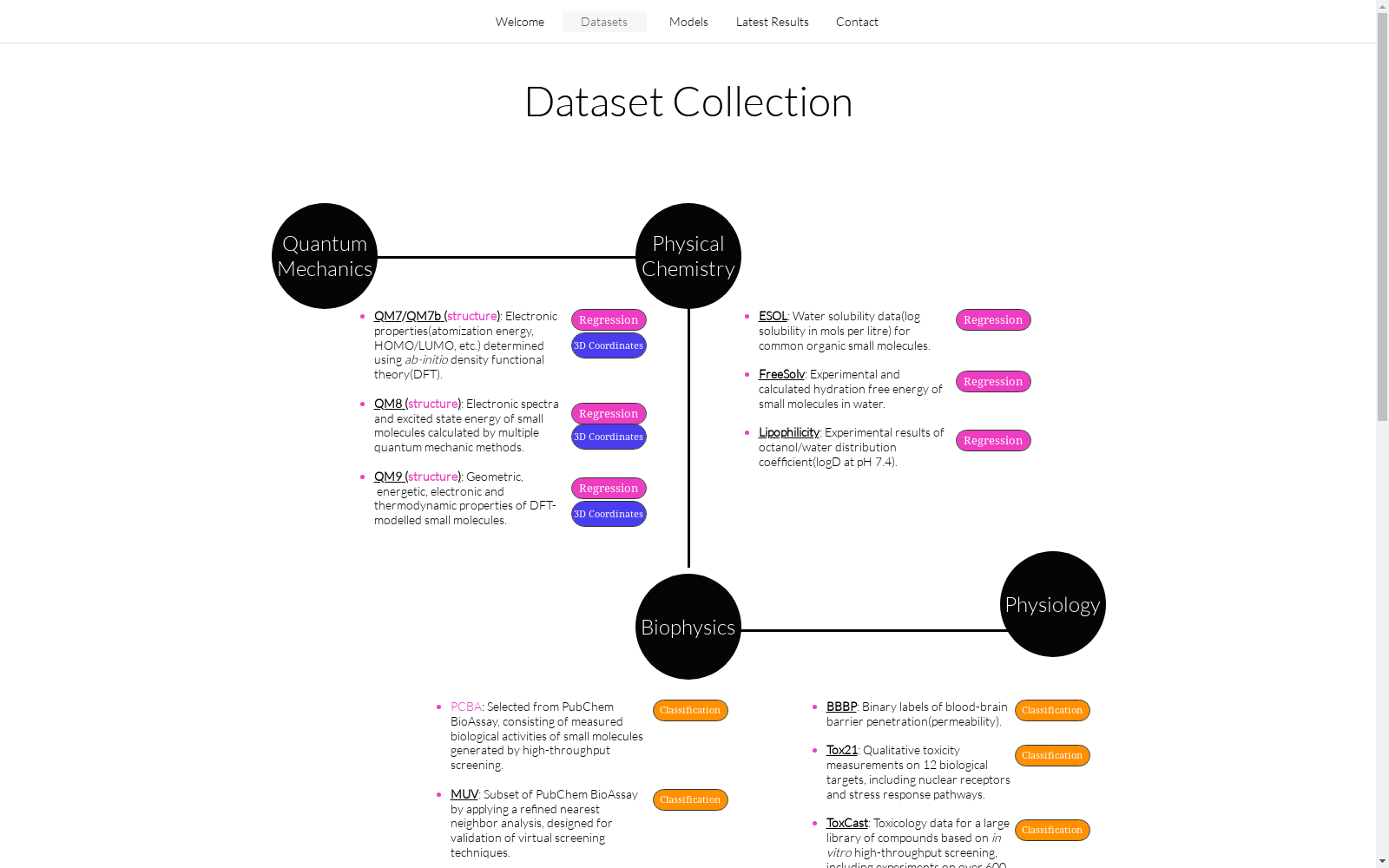
构建方式
Lipophilicity数据集的构建基于大量实验测定的化合物亲脂性数据,涵盖了多种化学结构和分子量范围。数据来源于公开的化学数据库和文献,经过严格的筛选和验证,确保数据的准确性和可靠性。构建过程中,研究人员采用了标准化方法对化合物进行分类和编码,同时记录了实验条件和测量误差,以提供全面的数据背景。
特点
Lipophilicity数据集的特点在于其广泛性和多样性,包含了超过4000种化合物的亲脂性数据,适用于不同类型的化学研究和药物设计。数据集中的化合物涵盖了从简单有机分子到复杂生物分子的广泛范围,具有高度的代表性。此外,数据集还提供了详细的实验条件和误差分析,增强了数据的可解释性和应用价值。
使用方法
Lipophilicity数据集可用于多种科学研究和工业应用,如药物设计、化学品筛选和环境毒理学研究。研究人员可以通过数据集中的亲脂性数据预测化合物的生物活性,优化药物分子的设计,或评估化学品的环境影响。使用时,用户需根据研究目的选择合适的化合物子集,并结合其他化学性质数据进行综合分析。数据集的详细实验记录和误差信息也为进一步的实验验证提供了参考。
背景与挑战
背景概述
Lipophilicity数据集,由瑞士苏黎世联邦理工学院的药物设计与发现实验室于2019年创建,主要研究人员包括Riniker和Landrum。该数据集的核心研究问题集中在预测化合物的亲脂性,这是一个在药物设计和开发中至关重要的参数。亲脂性不仅影响药物的吸收、分布、代谢和排泄(ADME)特性,还与药物的生物利用度和毒性密切相关。Lipophilicity数据集的发布,极大地推动了计算化学和药物设计领域的发展,为研究人员提供了一个标准化的工具,用于评估和优化新药物分子的亲脂性特性。
当前挑战
尽管Lipophilicity数据集在药物设计领域具有重要意义,但其构建和应用过程中仍面临若干挑战。首先,数据集的准确性依赖于实验测量的精确性,而实验误差可能导致预测模型的偏差。其次,数据集的多样性问题,即样本是否充分代表了所有可能的化学结构,也是一个关键挑战。此外,随着新化学实体的不断涌现,数据集的更新和扩展需求日益增加,这要求研究人员持续投入以保持数据集的前沿性和实用性。最后,如何有效地将数据集应用于高通量筛选和虚拟筛选,以加速药物发现过程,也是当前研究的热点问题。
发展历史
创建时间与更新
Lipophilicity数据集由Zhenqing Liu等人于2019年创建,旨在为药物发现领域提供一个标准化的亲脂性数据集。该数据集自创建以来未有公开的更新记录。
重要里程碑
Lipophilicity数据集的创建标志着药物化学领域在量化分子亲脂性方面的重要进展。该数据集包含了4200个化合物的实验测定数据,涵盖了广泛的化学空间,为研究人员提供了一个可靠的基准来评估和预测分子的亲脂性。这一数据集的发布促进了基于机器学习的药物设计方法的发展,特别是在分子筛选和优化过程中,显著提高了预测模型的准确性和可靠性。
当前发展情况
目前,Lipophilicity数据集已成为药物发现和化学信息学研究中的重要资源。它不仅被广泛应用于学术研究,还被制药行业用于开发新的药物候选物。随着计算化学和人工智能技术的进步,该数据集的应用范围不断扩大,为新型药物的设计和开发提供了强有力的支持。此外,Lipophilicity数据集的成功也激发了更多类似数据集的创建,进一步推动了药物化学领域的数据标准化和共享。
发展历程
- Lipophilicity数据集首次发表,由Zhenqin Wu等人提出,旨在通过机器学习方法预测化合物的亲脂性。
- Lipophilicity数据集首次应用于药物发现领域,研究人员利用该数据集进行模型训练,以优化药物分子的亲脂性特性。
- Lipophilicity数据集被广泛应用于多个国际研究项目,成为评估化合物亲脂性的标准数据集之一。
常用场景
经典使用场景
在药物化学领域,Lipophilicity数据集被广泛用于研究化合物的亲脂性。亲脂性是药物分子与生物膜相互作用的关键参数,直接影响药物的吸收、分布、代谢和排泄(ADME)特性。通过分析Lipophilicity数据集,研究人员能够预测和优化药物分子的亲脂性,从而提高药物的生物利用度和疗效。
实际应用
在实际应用中,Lipophilicity数据集被制药公司和研究机构用于药物设计和优化。通过分析数据集中的亲脂性数据,研究人员可以筛选出具有理想亲脂性的候选药物,从而提高药物的临床成功率。此外,该数据集还被用于开发新的药物传递系统,如脂质体和纳米颗粒,以改善药物的靶向性和生物利用度。
衍生相关工作
基于Lipophilicity数据集,许多相关的经典工作得以开展。例如,研究人员开发了多种机器学习模型,如支持向量机(SVM)和随机森林(Random Forest),用于预测化合物的亲脂性。此外,该数据集还启发了对药物分子结构与亲脂性之间关系的深入研究,推动了定量结构-活性关系(QSAR)模型的发展。这些工作不仅丰富了药物化学的理论基础,还为实际药物研发提供了有力工具。
以上内容由遇见数据集搜集并总结生成


