shuaishuaicdp/GUI-World
收藏Hugging Face2024-06-23 更新2024-06-22 收录
下载链接:
https://hf-mirror.com/datasets/shuaishuaicdp/GUI-World
下载链接
链接失效反馈官方服务:
资源简介:
GUI-World数据集引入了一个全面的基准,用于评估多模态大语言模型(MLLMs)在动态和复杂的图形用户界面(GUI)环境中的表现。它包含了六种GUI场景和八种GUI导向的问题类型的广泛注释,评估了当前最先进的图像和视频大语言模型在处理动态和多步骤任务时的局限性。该数据集为未来研究提供了宝贵的见解和基础,旨在增强MLLMs对动态GUI内容的理解和交互能力,推动能够感知和交互静态及动态GUI元素的强大GUI代理的发展。
GUI-World introduces a comprehensive benchmark for evaluating MLLMs in dynamic and complex GUI environments. It features extensive annotations covering six GUI scenarios and eight types of GUI-oriented questions. The dataset assesses state-of-the-art ImageLLMs and VideoLLMs, highlighting their limitations in handling dynamic and multi-step tasks. It provides valuable insights and a foundation for future research in enhancing the understanding and interaction capabilities of MLLMs with dynamic GUI content. This dataset aims to advance the development of robust GUI agents capable of perceiving and interacting with both static and dynamic GUI elements.
提供机构:
shuaishuaicdp
原始信息汇总
数据集:GUI-World
概述
GUI-World 引入了一个全面的基准,用于评估多模态大型语言模型(MLLMs)在动态和复杂图形用户界面(GUI)环境中的表现。该数据集包含六个 GUI 场景和八种类型的 GUI 导向问题的广泛注释。它评估了最先进的图像大型语言模型(ImageLLMs)和视频大型语言模型(VideoLLMs),突出了它们在处理动态和多步骤任务方面的局限性。GUI-World 提供了宝贵的见解,并为未来在增强 MLLMs 对动态 GUI 内容的理解和交互能力方面的研究奠定了基础。该数据集旨在推动开发能够感知和与静态和动态 GUI 元素交互的强大 GUI 代理的发展。
数据集信息
- 任务类别: 问答、文本生成
- 语言: 英语
- 数据集大小: 10K<n<100K
- 许可证: Creative Commons Attribution 4.0 International License
引用
@article{chen2024gui, title={GUI-WORLD: A Dataset for GUI-Orientated Multimodal Large Language Models}, author={GUI-World Team}, year={2024} }
搜集汇总
数据集介绍
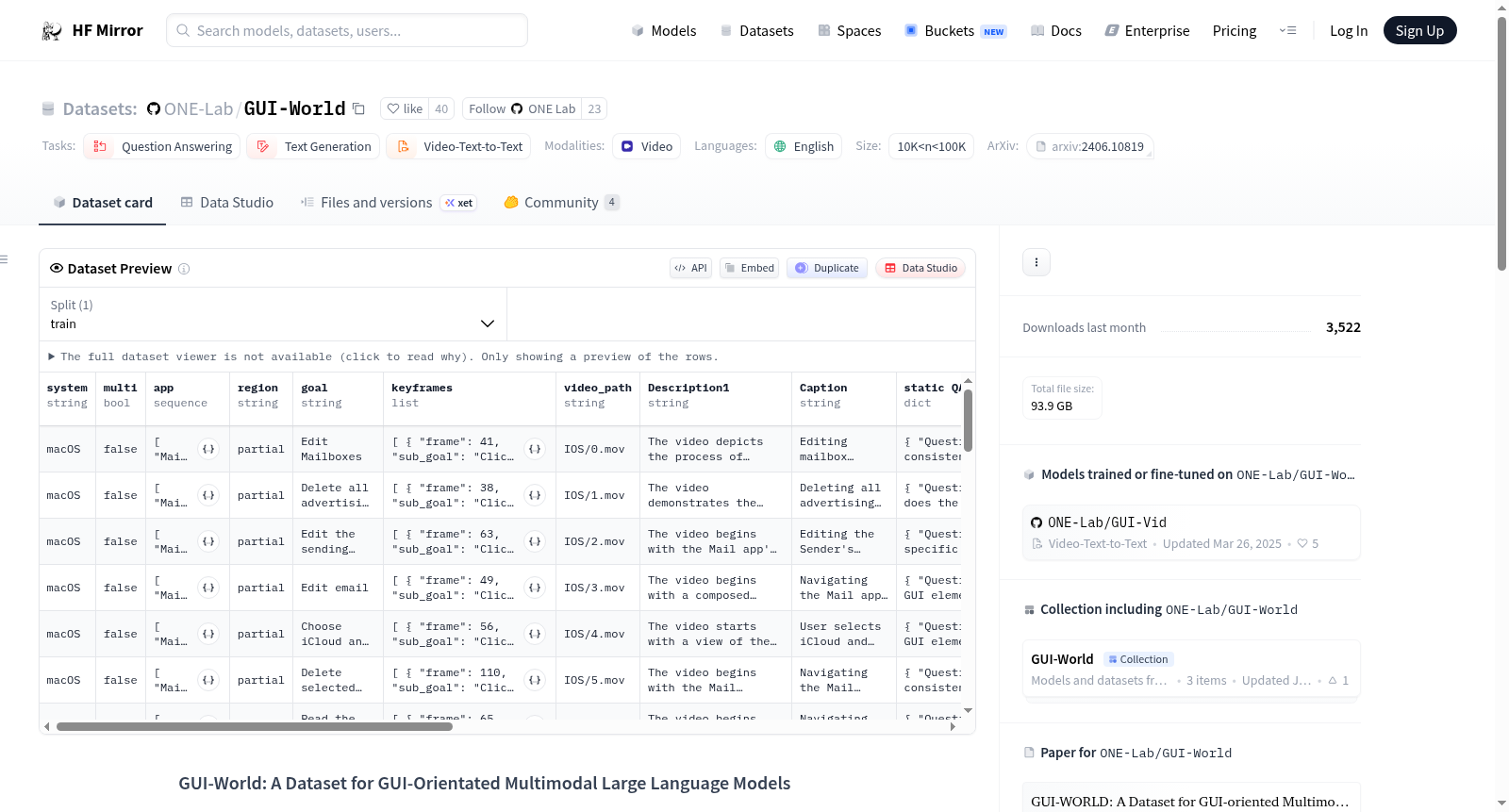
构建方式
在图形用户界面(GUI)领域,多模态大语言模型(MLLMs)的感知与交互能力面临动态复杂环境的挑战。GUI-World数据集应运而生,旨在构建一个系统化的评估基准。其构建方式涵盖六个典型GUI场景的详细标注,并设计八类面向GUI的问答任务,通过整合静态图像与动态视频数据,形成对MLLMs在现实界面中理解与操作能力的全面测试框架。
使用方法
研究者可参照配套的GitHub仓库获取详细使用指南。基于GUI-World,团队已训练出首个具备强大GUI理解能力的视频大语言模型GUI-Vid。用户可通过加载HuggingFace上的数据集与模型,结合标准问答或视频到文本任务接口,复现实验或自定义评估流程,从而在真实或合成的GUI环境中验证模型性能。
背景与挑战
背景概述
随着多模态大语言模型(MLLMs)在视觉与语言融合领域的迅猛发展,如何使其具备对图形用户界面(GUI)的深度理解与交互能力,已成为人机协作研究的前沿课题。在此背景下,由GUI-World团队于2024年创建的GUI-World数据集应运而生,旨在系统性地评估并推动MLLMs在动态与复杂GUI环境中的表现。该数据集由来自多个顶尖机构的研究人员共同构建,聚焦于六大GUI场景与八种面向GUI的问题类型,覆盖了静态界面识别与动态操作序列的广泛需求。通过引入视频级与图像级的联合标注,GUI-World不仅揭示了现有ImageLLMs与VideoLLMs在处理多步骤动态任务时的显著局限,还为后续开发具备鲁棒感知能力的GUI智能体奠定了坚实基础,对自动化用户界面理解与智能助手领域产生了深远影响。
当前挑战
GUI-World数据集所面临的挑战首先体现在领域问题的复杂性上:动态GUI环境中的多步骤任务要求模型不仅需理解静态元素的空间布局与语义,还需捕捉时间序列上的状态变迁与用户意图,这对当前MLLMs的时序推理与跨帧一致性能力构成了严峻考验。其次,在数据集构建过程中,研究人员遭遇了多维度标注的困难,包括如何精确对齐视频帧中的GUI事件与自然语言描述、如何确保跨场景(如移动端、桌面端、网页端)的标注一致性,以及如何平衡问题类型的多样性以避免偏见。此外,动态GUI的模糊边界与用户操作的非确定性进一步增加了数据清洗与质量控制的难度,使得构建一个既全面又高保真的基准成为一项极具挑战性的工程任务。
常用场景
经典使用场景
GUI-World数据集专为评估多模态大语言模型在动态、复杂图形用户界面环境中的表现而设计。其经典使用场景涵盖六大GUI应用场景与八种面向GUI的问答类型,包括静态界面理解、动态交互推理、多步骤任务解析等。研究者可借助该数据集系统性地检验ImageLLMs与VideoLLMs在感知和响应GUI元素时的性能瓶颈,尤其适用于评估模型在真实操作流程(如软件导航、表单填写、菜单选择)中的理解与生成能力。该数据集以其精细的标注和结构化的任务设计,成为推动GUI智能化研究不可或缺的基准资源。
解决学术问题
GUI-World有效解决了现有多模态模型在动态GUI环境中缺乏标准化评估体系的核心学术问题。此前,研究者难以量化模型对连续界面状态变化、多步操作逻辑及隐含交互意图的理解深度。该数据集通过引入多维度问题类型与场景覆盖,揭示了ImageLLMs在时序依赖任务中的显著短板,以及VideoLLMs在细粒度GUI元素识别上的局限性。其贡献在于为领域建立了一套可复现、可对比的评估框架,为后续研究指明了模型在动态交互理解上的关键改进方向,显著推动了面向GUI的多模态智能体理论发展。
实际应用
在实际应用中,GUI-World为构建能够自主操作软件界面的智能代理提供了关键支撑。基于该数据集训练的模型可应用于自动化测试(如遍历应用功能、检测异常流程)、无障碍辅助技术(如为视障用户生成界面操作指引)、以及数字员工(如自动完成数据录入、报表生成等重复性任务)。此外,其在教学演示场景中亦具潜力,能够生成实时、准确的GUI操作解说。这些应用不仅提升了人机交互效率,还降低了复杂软件的使用门槛,为工业界与消费端带来了切实的智能化变革。
数据集最近研究
最新研究方向
在图形用户界面(GUI)理解与交互的前沿领域,多模态大语言模型(MLLMs)正面临动态与多步骤任务的严峻挑战。GUI-World数据集应运而生,它系统性地覆盖了六种GUI场景与八类面向GUI的问题,为评估ImageLLMs与VideoLLMs在复杂环境中的表现提供了全新基准。当前研究热点聚焦于利用该数据集揭示现有模型在感知动态界面元素时的局限性,并推动首个具备强大GUI理解能力的VideoLLM——GUI-Vid的训练。这一方向不仅呼应了智能体在软件自动化、用户界面导航等实际应用中的迫切需求,更通过精细的时序与多步任务标注,为构建能够稳健处理静态与动态GUI内容的下一代多模态模型奠定了关键基础,对提升人机交互的自然性与效率具有深远意义。
以上内容由遇见数据集搜集并总结生成


