TCGA_Reports_ja_structured-filtered
收藏Hugging Face2025-11-13 更新2025-11-14 收录
下载链接:
https://huggingface.co/datasets/morizon/TCGA_Reports_ja_structured-filtered
下载链接
链接失效反馈官方服务:
资源简介:
TCGA日语翻译和结构化数据集是基于The Cancer Genome Atlas(TCGA)公开的英语病理报告的数据集。它使用大型语言模型进行了日语翻译和信息抽取的结构化处理。数据集包含唯一标识符、英语原文、日语翻译和结构化数据(JSON格式),其中结构化数据包括器官、诊断、病期等多个键的信息。
创建时间:
2025-11-09
原始信息汇总
TCGA日本語翻訳・構造化データセット
数据集概述
本数据集基于The Cancer Genome Atlas (TCGA)公开的英文病理报告,通过大语言模型(LLM)进行日语翻译和信息提取结构化处理。
数据来源
- 原始数据:Mendeley Data — TCGA Pathology Reports (Version 1)
- 原始数据地址:https://data.mendeley.com/datasets/hyg5xkznpx/1
数据特征
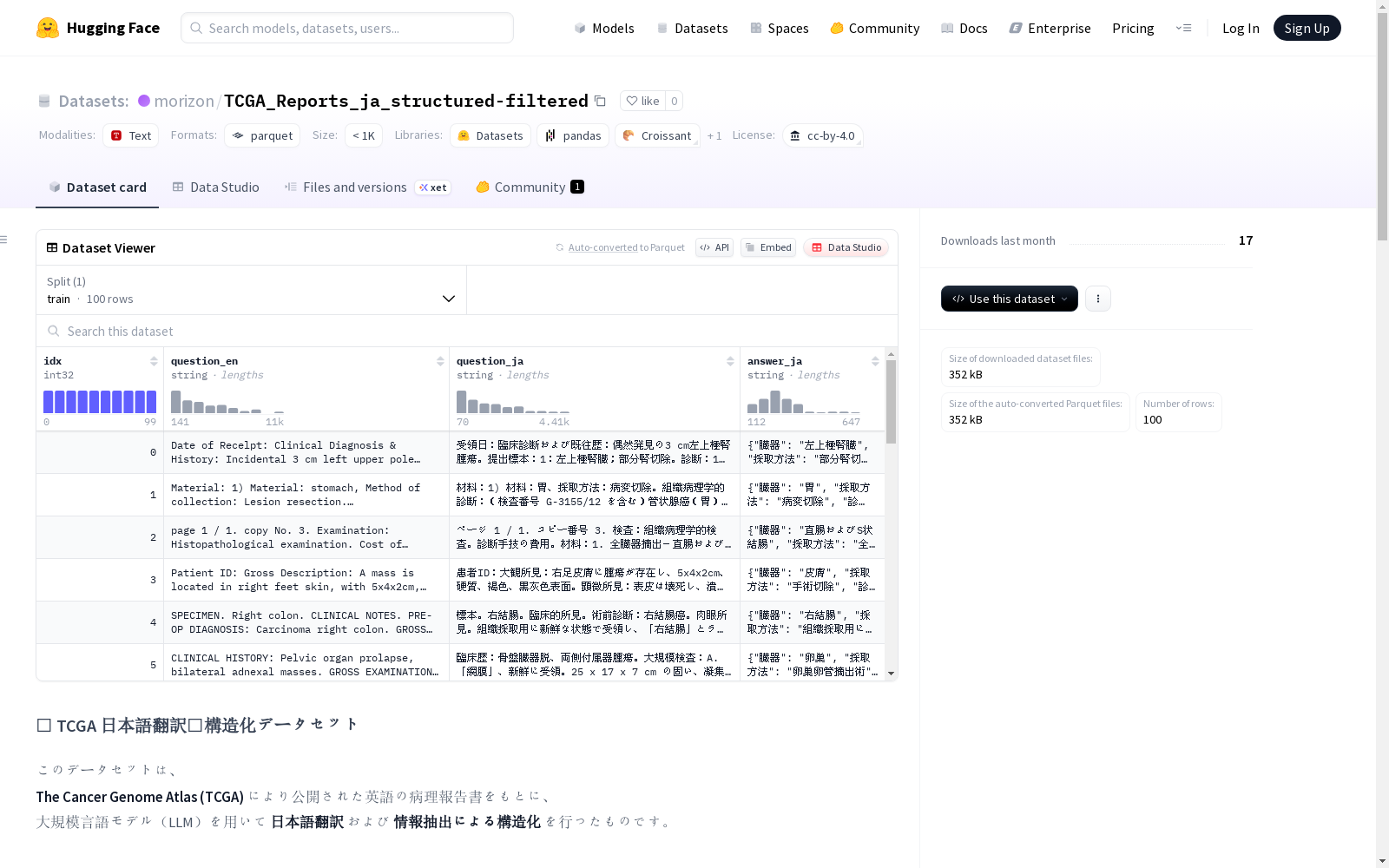
数据结构
- idx:唯一识别编号(int32)
- question_en:英文原文(string)
- question_ja:英文原文的日语翻译(string)
- answer_ja:从日语报告中提取的结构化数据(JSON格式,string)
数据规模
- 训练集:100个样本
- 数据文件路径:data/train-*
结构化数据内容
answer_ja字段包含以下JSON键值对:
- 臓器:检体器官名称
- 採取方法:手术・采集种类(例:部分切除、全摘等)
- 診断:主要病理诊断(例:肾细胞癌、乳腺浸润癌等)
- 分化度:等级(例:G2、高分化等)
- 病期:TNM分类和病期(例:pT1a)
- 腫瘍径:最大肿瘤直径(例:2.4 cm)
- 浸潤範囲:局部・血管・周围组织浸润信息
- 断端:手术断端肿瘤有无
- その他所見:非肿瘤部位所见・炎症等补充所见
生成流程
-
英语→日语翻译
- 使用模型:Qwen3-30B-A3B-Instruct-2507
- 方针:尽可能保持文章结构和数值・标点的自然日语翻译
-
日语→结构化信息提取
- 使用模型:Qwen3-30B-A3B-Instruct-2507
- 方针:基于固定的日语键提取信息,以STRICT JSON格式输出
许可证信息
- 许可证类型:Creative Commons Attribution 4.0 International (CC BY 4.0)
- 许可证地址:https://creativecommons.org/licenses/by/4.0/
- 使用限制:仅限于教育・研究用途使用
使用示例
python from datasets import load_dataset
ds = load_dataset("morizon/TCGA_Reports_JA_Structured") print(ds["train"][0]["question_ja"]) print(ds["train"][0]["answer_ja"])
搜集汇总
数据集介绍
构建方式
在癌症基因组图谱(TCGA)病理报告数据集的基础上,本数据集通过大语言模型技术实现了双重转化过程。原始英文病理报告首先经由Qwen3-30B-A3B-Instruct-2507模型进行精准翻译,在保持医学专业术语准确性的同时完成日文本地化处理。随后通过相同模型进行结构化信息抽取,将临床病理特征按照预定义的九大关键字段进行标准化提取,最终形成严格遵循JSON格式的标注体系。
使用方法
研究人员可通过HuggingFace标准接口直接加载数据集,每个样本均包含完整的文本序列与结构化标注。在具体应用中,可分别利用原始英文文本进行跨语言对比研究,借助日文翻译开展本土化医学语言分析,或基于结构化标注开发临床信息抽取模型。该数据集特别适用于医学机器翻译、临床实体识别和病理报告自动生成等研究方向,为智慧医疗领域的算法开发提供重要支撑。
背景与挑战
背景概述
癌症基因组图谱计划作为21世纪初启动的重大生物医学研究项目,系统性地收集了多种癌症类型的分子特征数据。该数据集基于TCGA病理报告原始资料,由研究团队通过大语言模型技术实现了医学文本的跨语言转换与结构化处理,标志着病理学信息数字化进程中的重要突破。其核心价值在于构建了首个公开的日英双语病理报告平行语料库,为亚洲地区的临床研究提供了重要的数据基础设施。
当前挑战
医学文本跨语言转换面临专业术语准确性与文化适配性的双重考验,需确保医学术语在日语语境中的精确对应。结构化处理过程中,非标准化病理描述的模式识别成为技术难点,特别是对TNM分期系统等专业内容的解析。原始数据固有的信息缺失与表述差异进一步增加了信息抽取的复杂度,要求模型具备较强的医学知识推理能力。
常用场景
经典使用场景
在医学信息处理领域,该数据集为跨语言病理报告分析提供了标准化语料。通过将英文病理报告转化为日文结构化数据,研究人员能够构建多语言医疗文本理解模型,支持病理学术语对齐、跨语言实体识别等任务,为全球医疗知识共享建立桥梁。
解决学术问题
该数据集有效解决了医学自然语言处理中的三大核心问题:一是通过标准化JSON结构消解非结构化报告的语义歧义,二是构建跨语言医学术语映射体系以弥合语言鸿沟,三是为低资源语言医疗文本分析提供高质量标注数据。这些突破显著推进了临床决策支持系统的智能化进程。
实际应用
在临床实践中,该数据集支撑的自动化系统可实时解析日文病理报告,辅助医生快速提取关键诊断指标。医疗机构利用其结构化输出实现病例自动归档,医保机构借助标准化数据优化疾病分类编码,制药企业则通过大规模病理特征分析加速靶向药物研发。
数据集最近研究
最新研究方向
在癌症基因组学与数字病理学交叉领域,TCGA_Reports_ja_structured-filtered数据集正推动多语言医疗文本智能处理的前沿探索。研究者聚焦于大语言模型驱动的病理报告跨语言结构化技术,通过将英文病理报告转化为日文结构化数据,为跨国医疗知识共享建立新范式。当前热点集中于利用此类双语对齐数据开发精准医学诊断辅助系统,特别是在肿瘤分级、TNM分期等关键临床指标的自动化提取方面取得突破。这一进展不仅显著提升了非英语地区医疗机构对TCGA宝贵资源的利用率,更通过标准化信息框架为全球癌症研究提供了可互操作的数据基础,对推动个性化诊疗和跨文化医学研究具有深远意义。
以上内容由遇见数据集搜集并总结生成


