haronbenfaida/FATURA_MODIF
收藏Hugging Face2024-07-11 更新2024-07-13 收录
下载链接:
https://hf-mirror.com/datasets/haronbenfaida/FATURA_MODIF
下载链接
链接失效反馈官方服务:
资源简介:
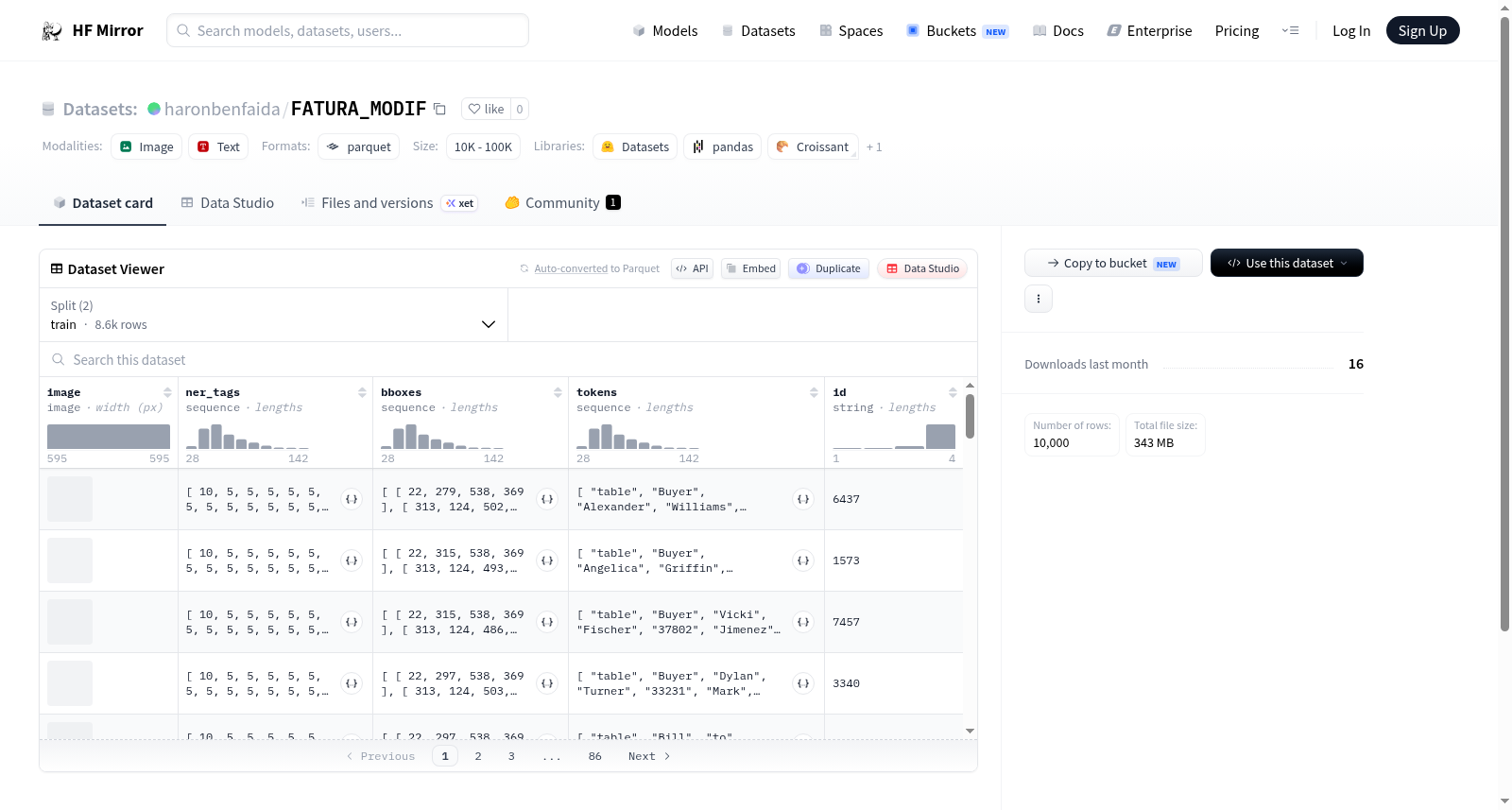
该数据集包含图像和文本信息,主要用于命名实体识别(NER)任务。数据集的特征包括图像、NER标签、边界框(bboxes)、文本标记(tokens)和唯一标识符(id)。NER标签涵盖了多种发票相关的实体类别,如总金额、发票日期、买方、卖方等。数据集分为训练集和测试集,训练集包含8600个样本,测试集包含1400个样本。
This dataset contains image and text information, primarily used for Named Entity Recognition (NER) tasks. The dataset features include images, NER tags, bounding boxes (bboxes), text tokens, and unique identifiers (id). The NER tags cover various invoice-related entity categories such as total amount, invoice date, buyer, seller, etc. The dataset is divided into a training set and a test set, with the training set containing 8600 samples and the test set containing 1400 samples.
提供机构:
haronbenfaida
原始信息汇总
数据集概述
数据集特征
- image: 图像数据
- ner_tags: 命名实体识别标签
- 类别标签:
- 0: $
- 1: Total
- 2: Total in Words
- 3: Invoice Date
- 4: Due Date
- 5: Send_to
- 6: Seller name
- 7: 7
- 8: Buyer
- 9: Tax
- 10: Table
- 11: Logo
- 12: Invoice Number
- 13: O
- 类别标签:
- bboxes: 边界框坐标,数据类型为float32
- tokens: 文本序列
- id: 字符串类型,用于标识
数据集划分
- train: 训练集
- 样本数量: 8600
- 数据大小: 379555516.0字节
- test: 测试集
- 样本数量: 1400
- 数据大小: 62615050.0字节
数据集大小
- 下载大小: 342745405字节
- 总数据集大小: 442170566.0字节
配置
- config_name: default
- 数据文件路径:
- 训练集: data/train-*
- 测试集: data/test-*
- 数据文件路径:
搜集汇总
数据集介绍
背景与挑战
背景概述
FATURA_MODIF是一个多模态数据集,包含图像和文本数据,主要用于文档处理任务,如发票分析。数据集规模为10,000行,以Parquet格式存储,并提供训练和测试分割,带有命名实体识别(NER)标签和边界框标注,适用于计算机视觉和自然语言处理应用。
以上内容由遇见数据集搜集并总结生成


