isek-ai/danbooru-tags-2016-2023
收藏Hugging Face2024-02-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/isek-ai/danbooru-tags-2016-2023
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
license: cc0-1.0
size_categories:
- 1M<n<10M
task_categories:
- text-classification
- text-generation
- text2text-generation
dataset_info:
- config_name: all
features:
- name: id
dtype: int64
- name: copyright
dtype: string
- name: character
dtype: string
- name: artist
dtype: string
- name: general
dtype: string
- name: meta
dtype: string
- name: rating
dtype: string
- name: score
dtype: int64
- name: created_at
dtype: string
splits:
- name: train
num_bytes: 2507757369
num_examples: 4601557
download_size: 991454905
dataset_size: 2507757369
- config_name: safe
features:
- name: id
dtype: int64
- name: copyright
dtype: string
- name: character
dtype: string
- name: artist
dtype: string
- name: general
dtype: string
- name: meta
dtype: string
- name: rating
dtype: string
- name: score
dtype: int64
- name: created_at
dtype: string
splits:
- name: train
num_bytes: 646613535.5369519
num_examples: 1186490
download_size: 247085114
dataset_size: 646613535.5369519
configs:
- config_name: all
data_files:
- split: train
path: all/train-*
- config_name: safe
data_files:
- split: train
path: safe/train-*
tags:
- danbooru
---
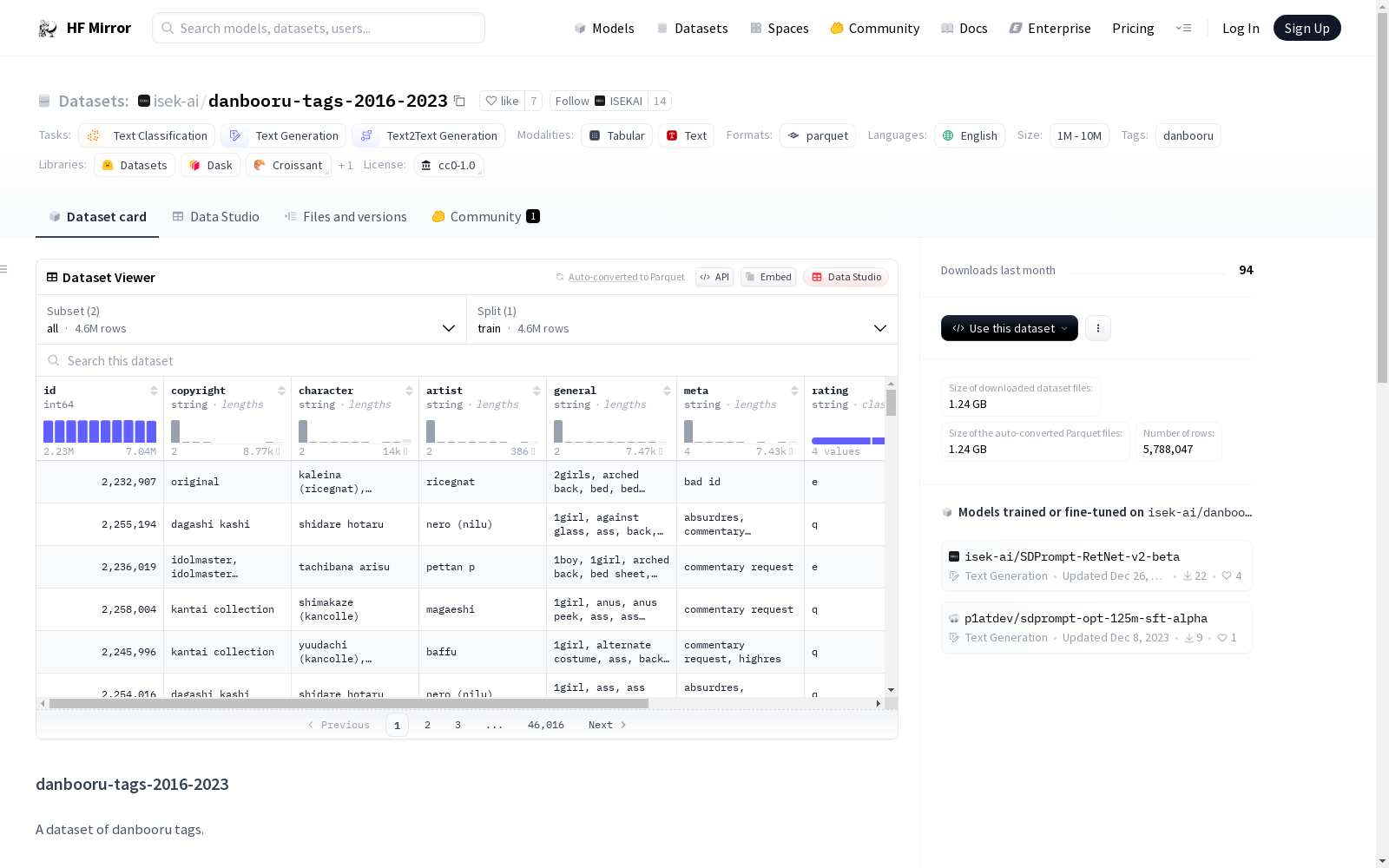
# danbooru-tags-2016-2023
A dataset of danbooru tags.
## Dataset information
Generated using [danbooru](https://danbooru.donmai.us/) and [safebooru](https://safebooru.donmai.us/) API.
The dataset was created with the following conditions:
|Subset name|`all`|`safe`|
|-|-|-|
|API Endpoint|https://danbooru.donmai.us|https://safebooru.donmai.us|
|Date|`2016-01-01..2023-12-31`|`2016-01-01..2023-12-31`|
|Score|`>0`|`>0`|
|Rating|`g,s,q,e`|`g`|
|Filetype|`png,jpg,webp`|`png,jpg,webp`|
|Size (number of rows)|4,601,557|1,186,490|
## Usage
```
pip install datasets
```
```py
from datasets import load_dataset
dataset = load_dataset(
"isek-ai/danbooru-tags-2016-2023",
"safe", # or "all"
split="train",
)
print(dataset)
print(dataset[0])
# Dataset({
# features: ['id', 'copyright', 'character', 'artist', 'general', 'meta', 'rating', 'score', 'created_at'],
# num_rows: 1186490
# })
# {'id': 2229839, 'copyright': 'kara no kyoukai', 'character': 'ryougi shiki', 'artist': 'momoko (momopoco)', 'general': '1girl, 2016, :|, brown eyes, brown hair, closed mouth, cloud, cloudy sky, dated, day, flower, hair flower, hair ornament, japanese clothes, kimono, long hair, long sleeves, looking at viewer, new year, obi, outdoors, sash, shrine, sky, solo, standing, wide sleeves', 'meta': 'commentary request, partial commentary', 'rating': 'g', 'score': 76, 'created_at': '2016-01-01T00:43:18.369+09:00'}
```
language:
- 英语
license: CC0 1.0
size_categories:
- 100万 < 样本数 < 1000万
task_categories:
- 文本分类
- 文本生成
- 文本到文本生成
dataset_info:
- config_name: 全量子集(all)
features:
- name: id
dtype: 64位整数(int64)
- name: copyright
dtype: 字符串
- name: character
dtype: 字符串
- name: artist
dtype: 字符串
- name: general
dtype: 字符串
- name: meta
dtype: 字符串
- name: rating
dtype: 字符串
- name: score
dtype: 64位整数(int64)
- name: created_at
dtype: 字符串
splits:
- name: 训练集(train)
num_bytes: 2507757369
num_examples: 4601557
download_size: 991454905
dataset_size: 2507757369
- config_name: 安全子集(safe)
features:
- name: id
dtype: 64位整数(int64)
- name: copyright
dtype: 字符串
- name: character
dtype: 字符串
- name: artist
dtype: 字符串
- name: general
dtype: 字符串
- name: meta
dtype: 字符串
- name: rating
dtype: 字符串
- name: score
dtype: 64位整数(int64)
- name: created_at
dtype: 字符串
splits:
- name: 训练集(train)
num_bytes: 646613535.5369519
num_examples: 1186490
download_size: 247085114
dataset_size: 646613535.5369519
configs:
- config_name: 全量子集(all)
data_files:
- split: 训练集(train)
path: all/train-*
- config_name: 安全子集(safe)
data_files:
- split: 训练集(train)
path: safe/train-*
tags:
- Danbooru
# Danbooru标签数据集(2016-2023)
本数据集为Danbooru平台的标签数据集。
## 数据集详情
本数据集通过[Danbooru](https://danbooru.donmai.us/)与[Safebooru](https://safebooru.donmai.us/)的应用程序编程接口(API)生成。
本数据集的构建遵循以下筛选条件:
| 子集名称 | `all`(全量子集) | `safe`(安全子集) |
| ---- | ---- | ---- |
| API接口地址 | https://danbooru.donmai.us | https://safebooru.donmai.us |
| 数据采集日期 | `2016-01-01 至 2023-12-31` | `2016-01-01 至 2023-12-31` |
| 点赞分数 | `>0` | `>0` |
| 内容分级 | `g,s,q,e` | `g` |
| 文件格式 | `png、jpg、webp` | `png、jpg、webp` |
| 样本量(行数) | 4,601,557 | 1,186,490 |
## 使用方法
bash
pip install datasets
py
from datasets import load_dataset
dataset = load_dataset(
"isek-ai/danbooru-tags-2016-2023",
"safe", # 或 "all"
split="train",
)
print(dataset)
print(dataset[0])
# 数据集对象({
# 特征字段:['id', 'copyright', 'character', 'artist', 'general', 'meta', 'rating', 'score', 'created_at'],
# 样本总数:1186490
# })
# {'id': 2229839, 'copyright': '空之境界(kara no kyoukai)', 'character': '两仪式(ryougi shiki)', 'artist': 'momoko (momopoco)', 'general': '1girl, 2016, :|, brown eyes, brown hair, closed mouth, cloud, cloudy sky, dated, day, flower, hair flower, hair ornament, japanese clothes, kimono, long hair, long sleeves, looking at viewer, new year, obi, outdoors, sash, shrine, sky, solo, standing, wide sleeves', 'meta': '请求补充注释、部分注释', 'rating': 'g', 'score': 76, 'created_at': '2016-01-01T00:43:18.369+09:00'}
提供机构:
isek-ai
原始信息汇总
数据集概述
基本信息
- 语言: 英语
- 许可: CC0-1.0
- 大小类别: 1M<n<10M
- 任务类别:
- 文本分类
- 文本生成
- 文本到文本生成
数据集配置
-
配置名称: all
- 特征:
- id: int64
- copyright: string
- character: string
- artist: string
- general: string
- meta: string
- rating: string
- score: int64
- created_at: string
- 分割:
- train
- 字节数: 2507757369
- 样本数: 4601557
- train
- 下载大小: 991454905
- 数据集大小: 2507757369
- 特征:
-
配置名称: safe
- 特征:
- id: int64
- copyright: string
- character: string
- artist: string
- general: string
- meta: string
- rating: string
- score: int64
- created_at: string
- 分割:
- train
- 字节数: 646613535.5369519
- 样本数: 1186490
- train
- 下载大小: 247085114
- 数据集大小: 646613535.5369519
- 特征:
数据文件
-
配置名称: all
- 数据文件:
- 分割: train
- 路径: all/train-*
- 数据文件:
-
配置名称: safe
- 数据文件:
- 分割: train
- 路径: safe/train-*
- 数据文件:
标签
- danbooru
搜集汇总
数据集介绍
构建方式
isek-ai/danbooru-tags-2016-2023数据集的构建,是基于danbooru和safebooru的API,从2016年至2023年间,筛选评分大于0的图片,涵盖g,s,q,e等级(在safe子集中仅包含g级),包括png,jpg,webp三种文件类型。数据集分为'all'和'safe'两个子集,其中'all'子集包含4,601,557条记录,而'safe'子集则包含1,186,490条记录,每个记录包含id、版权、角色、艺术家、通用标签、元数据、评分等级、得分和时间戳等字段。
使用方法
使用该数据集前,需先安装datasets库。通过调用load_dataset函数,指定数据集名称和配置('all'或'safe'),以及数据分割(此处为'train'),即可加载相应的数据集。加载后,数据集以Dataset对象形式呈现,包含多个字段,可通过索引访问单个数据样本,便于进行后续的数据处理和分析任务。
背景与挑战
背景概述
danbooru-tags-2016-2023数据集,源自danbooru与safebooru的API,汇集了自2016年至2023年间,评分大于0的图像及其标签信息。该数据集由isek-ai组织创建,旨在为文本分类、文本生成等任务提供丰富多样的训练资源,对于图像内容识别、版权管理、艺术风格分析等领域的研究具有显著推动作用。
当前挑战
在构建danbooru-tags-2016-2023数据集的过程中,研究人员面临着数据清洗、版权标注、标签一致性等多重挑战。此外,数据集在处理图像内容的多样性与敏感性问题上也需克服重大难题,以确保数据的质量与应用的广泛性。在研究领域,如何有效利用该数据集进行文本到文本的生成任务,同时保持标签的准确性与相关性,亦是一个待解决的挑战。
常用场景
经典使用场景
在自然语言处理领域,isek-ai/danbooru-tags-2016-2023数据集被广泛用于图像标注与文本分类任务。其通过提供详尽的标签信息,使得研究人员能够训练模型识别图像中的元素、角色、艺术家风格等,进而实现图像内容的自动化描述与分类。
解决学术问题
该数据集解决了图像标注中的细粒度识别问题,以及文本分类中的多标签问题。通过这一数据集,学者们能够更好地理解图像与标签之间的复杂关系,提高了机器学习模型在图像理解领域的准确性和泛化能力。
实际应用
在实际应用中,isek-ai/danbooru-tags-2016-2023数据集可用于图像搜索引擎的优化,提升图像检索的准确性和相关性。此外,它还可用于内容审核系统,自动识别和过滤不适宜的内容,保障网络环境的健康。
数据集最近研究
最新研究方向
在计算机视觉与自然语言处理领域,isek-ai/danbooru-tags-2016-2023数据集的近期研究集中于深度学习模型在图像标签自动分类与生成任务中的应用。该数据集因其丰富的图像与标签信息,成为评价模型在处理具有复杂语义关系图像时的性能基准。研究者们正致力于探索如何通过该数据集提升模型对艺术风格、角色特征及情感表达的识别能力,以期在图像内容理解与生成对抗网络(GANs)领域取得突破性进展。此外,该数据集在维护网络内容的健康传播方面也具有重要意义,通过构建安全可控的图像过滤机制,为网络空间治理提供了有力支持。
以上内容由遇见数据集搜集并总结生成


