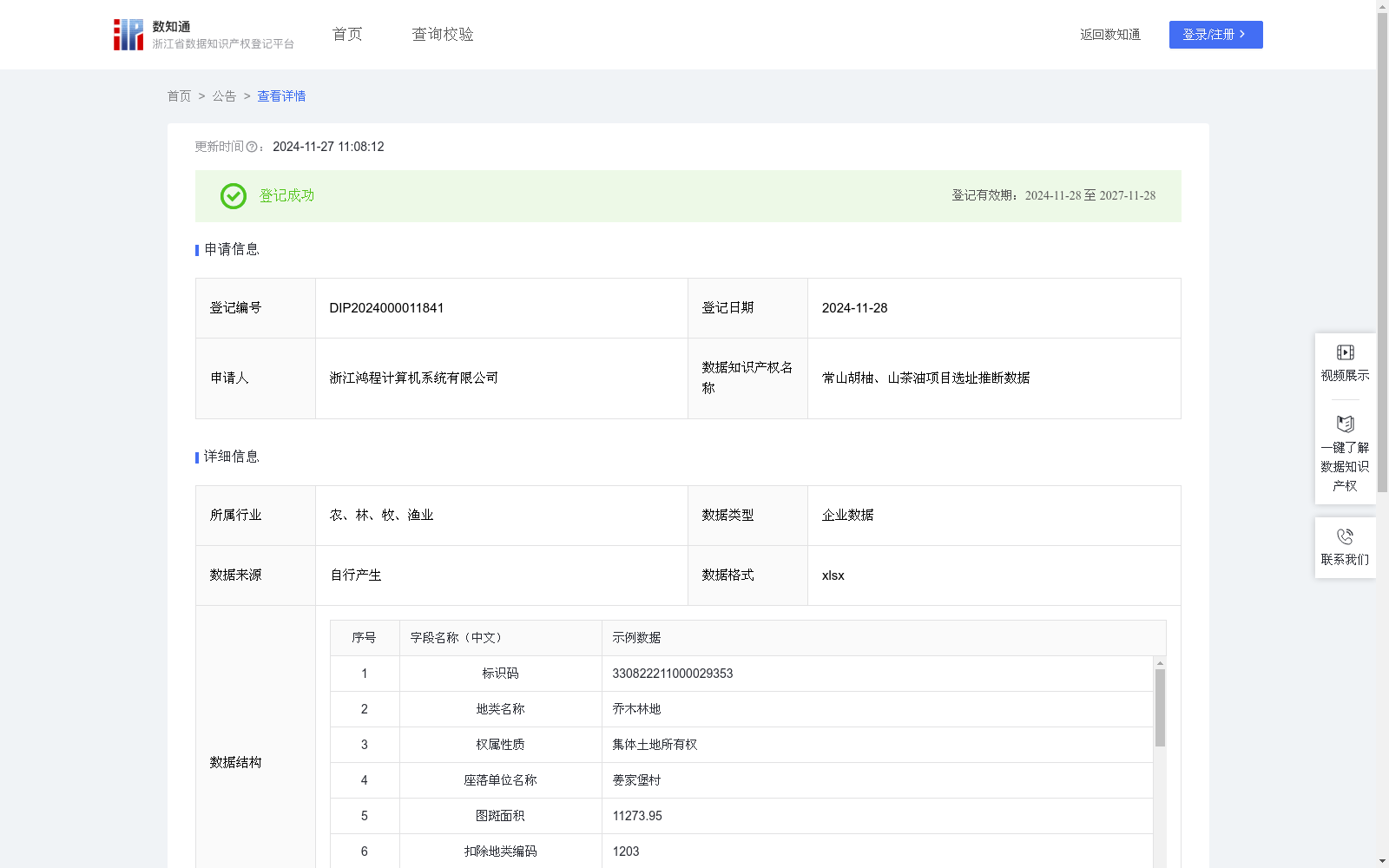
常山胡柚、山茶油项目选址推断数据
收藏浙江省数据知识产权登记平台2024-11-27 更新2024-11-28 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/89947
下载链接
链接失效反馈官方服务:
资源简介:
胡柚和山茶油是常山的重要农业产业,但是项目用地的选址是项目落地的重要步骤,地理位置直接决定了项目的好坏,因此需要大量的时间去相关部门了解情况,和实地探查。由于对地块信息不了解,对企业来说项目用地的选择实际上存在信息偏差和不透明的情况,处于比较被动的地位。如果企业能够在地图上直接选择相应的地块构成项目,或者直接选则成片的项目地块,则极大的提高了项目选址的效率。基于此背景,利用机器学习算法以acgis为依托,形成智能化的胡柚和山茶油项目用地推荐,以此提高项目落地的效率。
模型通过三调数据、胡柚一张图、山茶一张图数据,使用随机森林算法拟合地块和项目之间的关系,即什么样的地块适用于什么农业项目,从而得到农业项目预测模型;将未标记三调地块属性数据代入农业项目预测模型中运算,推测出各地块适用于的项目,将小地块以不同的中心和面积聚类后得到潜在农业项目地址数据;数据来源于三调数据的地块属性数据,通过数据表中地块名称、权属性质、图斑面积、扣除地类编码、扣除地类系数、扣除地类面积、图斑地类面积、耕地类型、耕地坡度级别、线性图斑宽度、耕地种植属性名称、耕地等别、周长、面积作为特征,该编号地块种植的类别作为结果,通过随机森林模型进行训练得到种植类别推断模型,以地块特征作为输入参数从而得到该地块能够种植的农业类别(山茶油、胡柚),由于三调地块面积比较小,且存在跨镇街的情况,分布较为分散,在实际选址过程中不具备可行性,需要对微小地块进行聚类,对每个种植类别,每个镇街的不同地块,以经纬度为参数通过knn模型聚类为不同数量的簇作为一个项目,并编码。完成了在不同种植类别下,不同镇街下,对地块作为项目的打包和选址。
Honey pomelo and camellia oil are pillar agricultural industries in Changshan. However, site selection for project land is a critical step for project implementation, as geographic location directly determines the success of a project. Traditionally, this process requires significant time spent consulting relevant government departments and conducting field surveys. Due to limited understanding of parcel information, enterprises often face information asymmetry and opacity when selecting project land, putting them in a relatively passive position. If enterprises can directly select corresponding parcels or contiguous land parcels to form a project on a map, it would greatly improve the efficiency of site selection. Against this background, this work leverages machine learning algorithms based on ArcGIS to develop an intelligent site recommendation system for honey pomelo and camellia oil projects, so as to enhance the efficiency of project implementation.
The model first uses the Third National Land Survey data, "Honey pomelo one-map" dataset and "Camellia oil one-map" dataset to fit the relationship between land parcels and agricultural projects via the Random Forest algorithm, i.e., determining which land parcels are suitable for which agricultural projects, thereby obtaining an agricultural project prediction model. Unlabeled attribute data of Third National Land Survey parcels are then input into the agricultural project prediction model to infer the suitable projects for each parcel. Small parcels are clustered with varying centers and areas to generate potential agricultural project site datasets.
The data source is the parcel attribute data from the Third National Land Survey, with features including parcel name, ownership nature, patch area, deducted land type code, deducted land type coefficient, deducted land type area, patch land type area, cultivated land type, cultivated land slope grade, linear patch width, cultivated land planting attribute name, cultivated land grade, perimeter and area. The planting category of the numbered parcel is taken as the target label. A planting category inference model is trained using the Random Forest algorithm, which takes parcel features as input parameters to predict the applicable agricultural planting categories (camellia oil or honey pomelo) for the parcel.
Since the Third National Land Survey parcels are small in size and dispersedly distributed across multiple towns and sub-districts, they are not feasible for direct use in actual site selection. Therefore, micro parcels need to be clustered. For each planting category and each town/sub-district, different parcels are clustered into a specified number of clusters via the K-Nearest Neighbors (KNN) model using longitude and latitude as parameters, and each cluster is encoded as a project. This completes the packaging and site selection of land parcels into projects across different planting categories and towns/sub-districts.
提供机构:
浙江鸿程计算机系统有限公司
创建时间:
2024-10-17
搜集汇总
数据集介绍
特点
该数据集利用机器学习算法分析地块属性,预测适合种植胡柚或山茶油的地块,并通过聚类方法提供农业项目选址推荐,旨在提高农业项目选址的效率和透明度。
以上内容由遇见数据集搜集并总结生成


