regulation-retrieval
收藏Hugging Face2026-01-23 更新2026-01-24 收录
下载链接:
https://huggingface.co/datasets/newmindai/regulation-retrieval
下载链接
链接失效反馈官方服务:
资源简介:
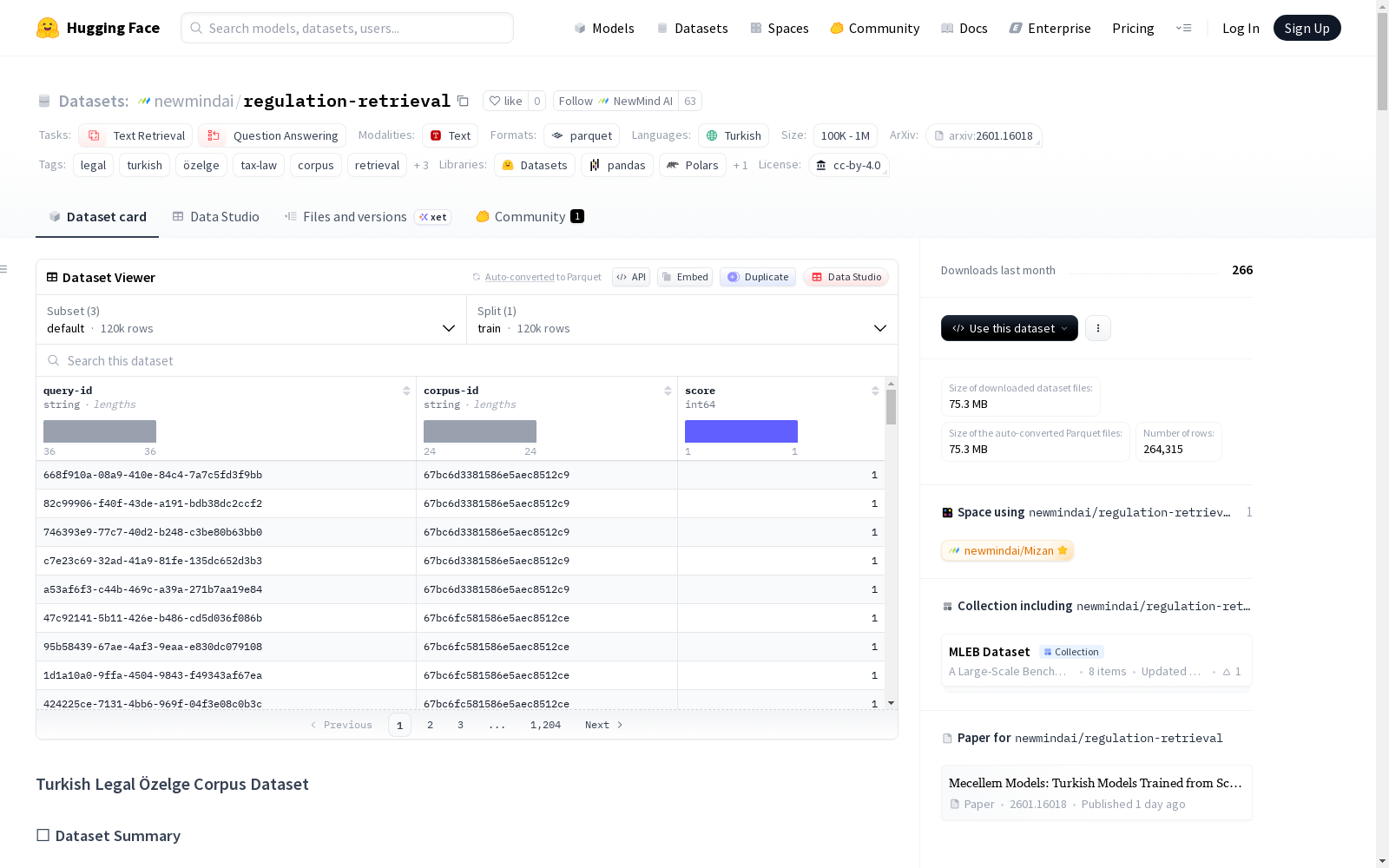
土耳其法律Özelge语料库是一个全面的信息检索数据集,包含土耳其税务局(Gelir İdaresi Başkanlığı - GİB)发布的税收裁决(özelge)决定。数据集采用BEIR(基准信息检索)格式,包含语料库-查询-相关矩阵结构,语言为土耳其语,涉及税法、行政法和土耳其法律领域。数据集可用于信息检索、问答系统和RAG(检索增强生成)应用。语料库包含23,701份文档,查询记录有121,198条,相关记录有121,198条。每个özelge平均由约5.1个不同的查询表示,对应不同的法律领域。
创建时间:
2026-01-16
原始信息汇总
Turkish Legal Özelge Corpus 数据集概述
数据集基本信息
- 数据集名称: Turkish Legal Özelge Corpus
- 语言: 土耳其语 (tr)
- 许可证: CC-BY 4.0
- 任务类别: 文本检索、问答
- 领域: 法律、土耳其语、税务法律
- 数据规模: 10K < n < 100K
- 格式: BEIR (Benchmarking IR) 格式,包含语料库-查询-相关性三元组结构
数据集结构与内容
数据集包含三个主要组件:
1. 语料库
- 记录数量: 23,701 份文档
- 内容: 土耳其税务局发布的完整税务裁定文本
- 特征:
_id: 文档标识符text: 文档文本
2. 查询
- 记录数量: 121,198 条查询
- 内容: 从七个不同法律视角为每份文档提取的法律信息片段
- 查询类型:
- 主题: 裁定的主要议题
- 法律条文文本: 相关法律条款内容
- 公报文本: 相关公报和通函内容
- 法规文本: 法规和立法文本
- 理由文本: 法律理由说明
- 决定文本: 行政意见和最终决定
- 条件文本: 适用条件和要求
- 特征:
_id: 查询标识符text: 查询文本
3. 相关性矩阵
- 记录数量: 121,198 条关系
- 内容: 显示查询与文档归属关系的表格
- 特征:
query-id: 查询标识符corpus-id: 相关文档标识符score: 相关性分数(全部为1)
数据集统计
- 语料库文档总数: 23,701
- 查询总数: 121,198
- 相关性关系总数: 121,198
- 平均每文档查询数: 约5.1条
查询类型覆盖分布
- 2种查询类型: 约0.1%的文档
- 3种查询类型: 约12.3%的文档
- 4种查询类型: 约26.2%的文档
- 5种查询类型: 约23.9%的文档
- 6种查询类型: 约12.6%的文档
- 7种查询类型: 约24.9%的文档
文本长度分布
语料库文本(完整裁定文本):
- 平均长度: 约1,736词
- 中位数: 约1,658词
- 第90百分位数: 约2,393词
查询文本:
- 平均长度: 约41.6词
- 中位数: 约24词
- 第90百分位数: 约97词
数据来源与处理
- 数据来源: 土耳其税务局官方税务裁定决定
- 处理: 使用MPNetTokenizerFast等七个分词器进行基准测试和数据过滤,移除了超过数据集特定平均值约7000个标记的样本
使用场景
- 信息检索系统: 语义搜索模型训练、密集检索系统、稀疏检索系统基准测试
- RAG应用: 法律聊天机器人、税务咨询助手、自动裁定分析系统
- 问答系统: 法律问答模型、抽取式和抽象式问答、多跳推理
- 模型评估: 土耳其语信息检索模型基准测试、检索性能分析、领域适应研究
引用信息
bibtex @article{mecellem2026, title={Mecellem Models: Turkish Models Trained from Scratch and Continually Pre-trained for the Legal Domain}, author={Uğur, Özgür and Göksu, Mahmut and Çimen, Mahmut and Yılmaz, Musa and Şavirdi, Esra and Demir, Alp Talha and Güllüce, Rumeysa and Çetin, İclal and Sağbaş, Ömer Can}, journal={arXiv preprint arXiv:2601.16018}, year={2026}, month={January}, url={https://arxiv.org/abs/2601.16018}, doi={10.48550/arXiv.2601.16018}, eprint={2601.16018}, archivePrefix={arXiv}, primaryClass={cs.CL} }
许可证
- 数据集许可证: CC-BY 4.0
- 代码许可证: Apache 2.0 License
联系信息
- 邮箱: info@newmind.ai
搜集汇总
数据集介绍
构建方式
在土耳其法律信息检索领域,Turkish Legal Özelge Corpus 的构建体现了严谨的学术方法。该数据集源自土耳其税务局(GİB)公开发布的官方税收裁定(özelge),通过系统化的处理流程,将原始法律文书转化为标准化的信息检索语料。其核心构建逻辑遵循BEIR基准格式,将数据解构为语料库、查询集及相关性矩阵三个独立组件。构建过程中,研究者对原始文本进行了深度解析,从每个裁定文件中提取出七个维度的法律信息片段,形成结构化的查询集合,并通过严格的Tokenizer基准测试与数据过滤流程,移除了序列长度异常的样本,确保了数据分布的均衡性与模型输入的清洁度。
特点
本数据集在土耳其法律文本资源中展现出鲜明的专业特性。其语料库包含超过两万三千份完整的税收裁定文本,内容详实,平均长度约一千七百词,属于典型的长篇、密集的法律裁决文书。查询集则从七个法律视角对每份文书进行解构,生成了超过十二万条精炼的法律信息片段,平均每条查询约包含四十二个词汇,模拟了简短的法律问题或法规摘要。数据结构的精巧之处在于,平均每份裁定文书关联约5.1个不同视角的查询,其中超过六成的案例拥有五个或以上的查询类型,构成了丰富的多视角法律案例,而非简单的单标签样本,这为训练复杂的语义理解模型提供了深度的上下文关联。
使用方法
该数据集为法律人工智能研究提供了标准化的评估与训练平台。使用者可依据BEIR格式,直接加载语料库、查询集及默认的相关性评分数据,用于训练和评估各类信息检索模型,包括密集检索系统与稀疏检索算法。在检索增强生成应用场景中,该数据集能够支撑法律聊天机器人、税收咨询助手等系统的开发,通过将简短的法律问题与完整的裁定文书进行关联,实现精准的知识检索。此外,数据集亦适用于构建土耳其语的法律问答系统,支持从裁定文本中进行抽取式或生成式答案的推理,为领域适应研究和模型性能基准测试提供了高质量的土耳其语法律领域资源。
背景与挑战
背景概述
土耳其法律Özelge语料库由Newmind.ai研究团队于2026年构建,旨在为土耳其语法律信息检索领域提供基准资源。该数据集聚焦于土耳其税务局发布的税收裁定(özelge),其核心研究问题在于解决法律文本中复杂语义的精准匹配与检索,特别是在多维度法律视角下的信息关联。该资源的出现,显著推动了土耳其语法律人工智能的发展,为检索增强生成、法律问答系统等应用提供了高质量、结构化的训练与评估基础。
当前挑战
该数据集致力于应对法律信息检索领域的核心挑战,即如何从冗长且专业术语密集的税收裁定文本中,精准定位并提取与特定法律问题相关的片段。构建过程中的主要挑战包括:处理原始法律文档中存在的极端长序列文本,这要求进行精细的令牌化分析与数据过滤以平衡序列分布;同时,从每份裁定中系统性地提取七个独立的法律视角查询,确保多维度语义覆盖的完整性与一致性,也是一项复杂的标注工程。
常用场景
经典使用场景
在土耳其法律信息检索领域,Turkish Legal Özelge Corpus数据集为语义检索模型的训练与评估提供了标准化基准。该数据集遵循BEIR格式,包含税务裁决全文、从七个法律视角提取的查询片段及其相关性标注,使得研究人员能够系统性地开发和测试密集检索与稀疏检索算法。其经典应用场景聚焦于构建针对土耳其税务法规的智能检索系统,通过模拟真实的法律咨询需求,评估模型在复杂法律文本中定位相关信息的能力。
衍生相关工作
围绕该数据集,已衍生出一系列重要的研究工作,特别是在土耳其法律人工智能模型开发方面。例如,Mecellem项目利用此语料库训练了面向法律领域的土耳其语预训练模型,并进行了持续的领域适应性预训练。相关研究进一步探索了基于该数据集的密集段落检索系统优化、多跳法律推理任务构建,以及跨法规条文的语义匹配算法。这些工作共同推动了土耳其语法律信息检索技术的进步,并为后续的跨领域法律文本分析提供了可复现的基准框架。
数据集最近研究
最新研究方向
在土耳其法律信息检索领域,Turkish Legal Özelge Corpus数据集正推动前沿研究聚焦于多视角稠密检索与检索增强生成(RAG)系统的深度融合。该数据集以税务裁定(özelge)为核心,通过七类法律视角构建查询,为模型理解复杂法律语义提供了结构化基础。当前研究热点集中于利用该数据集训练领域自适应的大语言模型,以提升土耳其语法律咨询自动化系统的准确性与可解释性。随着全球对法律人工智能需求的增长,此类高质量、多维度标注的领域数据集,为开发能够处理长文本、多跳推理的智能法律助手奠定了关键数据基石,显著促进了非英语法律自然语言处理技术的发展。
以上内容由遇见数据集搜集并总结生成


