Mega-SSum, CSJ-SSum
收藏arXiv2024-08-01 更新2024-08-05 收录
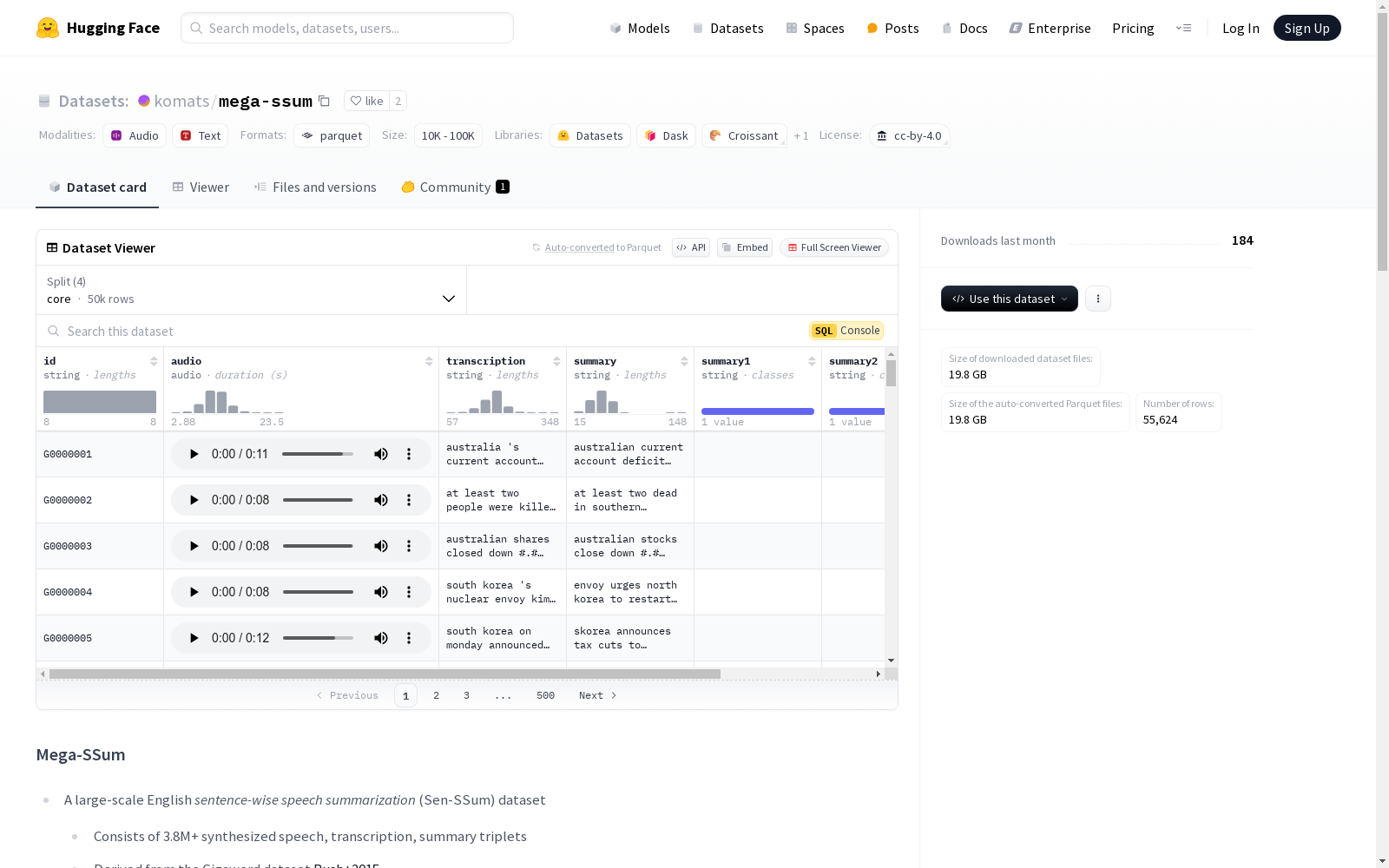
下载链接:
https://huggingface.co/datasets/komats/Mega-SSum
下载链接
链接失效反馈官方服务:
资源简介:
Mega-SSum和CSJ-SSum是由NTT Corporation创建的句子级语音摘要数据集,分别包含380万条英语和38,515条日语的合成语音、转录和摘要三元组。这些数据集基于Gigaword和Corpus of Spontaneous Japanese构建,用于研究句子级语音摘要技术。数据集的创建过程包括使用先进的文本到语音模型合成高质量语音,并由专业标注人员提供摘要。这些数据集主要应用于实时语音摘要和提高语音内容的可理解性,旨在解决传统语音识别和摘要技术在实时性和简洁性上的不足。
Mega-SSum and CSJ-SSum are sentence-level speech summarization datasets created by NTT Corporation. They contain 3.8 million English and 38,515 Japanese synthetic speech, transcription and summary triplets respectively. These datasets are built upon Gigaword and the Corpus of Spontaneous Japanese, and are intended for research on sentence-level speech summarization technologies. The dataset creation process involves synthesizing high-quality speech using state-of-the-art text-to-speech models, with summaries provided by professional annotators. These datasets are mainly applied in real-time speech summarization and improving the comprehensibility of speech content, aiming to address the shortcomings of traditional speech recognition and summarization technologies in terms of real-time performance and conciseness.
提供机构:
NTT Corporation
创建时间:
2024-08-01
原始信息汇总
Mega-SSum 数据集
概述
Mega-SSum 是一个用于研究基于 Gigaword 数据集的句子级语音摘要的数据集。它包含 380 万个高质量、多说话人生成的语音、转录和摘要(标题)三元组。
- 完整的训练集由于内部错误目前不可用。
- 可以使用核心分割集开始工作,该分割集包含 50,000 个样本。
分割详情
| 分割 | 样本数量 | 说话人数量 | 时长(小时) |
|---|---|---|---|
| train | 3,800,000 | 2,559 | 11,678.2 |
| core* | 50,000 | 2,559 | 154.6 |
| valid | 1,000 | 96 | 3.0 |
| duc2003 | 624 | 80 | 2.1 |
| eval** | 4,000 | 80 | 12.5 |
(*) 核心分割集包含在训练集中。
(**) 评估分割集用于评估域内准确性。
基准模型
- 端到端模型:Conformer-Transformer 编码器-解码器模型(139M)
- 级联模型:ASR 模型 + T5 模型(142M+220M)
评估分割集(域内)
| 模型 | ROUGE-L | BERTScore | 压缩率(%) |
|---|---|---|---|
| 端到端(核心) | 39.9 | 64.2 | 23.4 |
| 端到端(训练) | 50.4 | 71.1 | 23.2 |
| 端到端(核心+KD) | 45.5 | 68.1 | 25.3 |
| 级联(核心) | 46.1 | 68.7 | 26.2 |
| 级联(训练) | 51.9 | 72.5 | 25.2 |
(*) 核心+KD:使用“级联(核心)”生成的 375 万个伪摘要和 5 万个核心真实摘要进行训练(即知识蒸馏)。
DUC2003 分割集(域外)
- 最佳分数是从四个参考摘要中选出的。
| 模型 | ROUGE-L | BERTScore | 压缩率(%) |
|---|---|---|---|
| 端到端(核心) | 30.7 | 58.0 | 21.3 |
| 端到端(训练) | 36.9 | 62.1 | 20.6 |
| 端到端(核心+KD) | 35.6 | 61.9 | 23.5 |
| 级联(核心) | 36.0 | 62.6 | 25.0 |
| 级联(训练) | 37.9 | 64.2 | 23.7 |
搜集汇总
数据集介绍
构建方式
Mega-SSum and CSJ-SSum数据集的构建基于将自动语音识别(ASR)和语音摘要(SSum)相结合的理念,旨在生成从语音文档中逐句生成的文本摘要。Mega-SSum数据集基于Gigaword数据集,包含3.8M个英语语音三元组,包括合成的语音、转录和摘要。为了提高实验结果的可靠性,研究还使用了基于CSJ语料库的CSJ-SSum数据集,包含38k个日语语音三元组。这两个数据集为研究Sen-SSum任务提供了丰富的训练和评估资源。
特点
Mega-SSum数据集的特点在于其大规模的英语语音数据,包含合成的语音、转录和摘要,有助于探索训练数据规模对模型性能的影响。CSJ-SSum数据集则提供了真实语音数据,包含日语语音、转录和摘要,为Sen-SSum任务在真实场景中的应用提供了验证。此外,Mega-SSum数据集的训练集被分为核心集和剩余集,以模拟低资源和实际应用场景。
使用方法
Mega-SSum和CSJ-SSum数据集可用于训练和评估句子级语音摘要(Sen-SSum)模型。研究人员可以使用这两个数据集来训练级联模型和端到端(E2E)模型,并评估不同模型架构和训练数据规模对模型性能的影响。此外,这两个数据集还可用于研究知识蒸馏等技术,以提高E2E模型的性能。
背景与挑战
背景概述
随着语音识别(ASR)和语音摘要(SSum)技术的发展,对实时且简洁的语音摘要的需求日益增长。传统的语音摘要技术往往无法满足实时应用的需求,因为它们通常需要处理整个语音文档。为了解决这一问题,Matsuura等人提出了句子级语音摘要(Sen-SSum)的概念,它结合了ASR的实时处理能力和SSum的简洁性,可以逐句生成文本摘要。为了探索这一方法,他们创建了两个数据集:Mega-SSum和CSJ-SSum。Mega-SSum是一个基于Gigaword数据集的英语数据集,包含380万个合成的语音句子及其对应的转录和摘要。CSJ-SSum是一个基于CSJ语料库的日语数据集,包含3.85万个真实的语音句子及其对应的转录和摘要。这些数据集的创建为句子级语音摘要的研究提供了重要的资源,并对相关领域产生了深远的影响。
当前挑战
句子级语音摘要面临着一些挑战。首先,它需要在实时环境下工作,因此需要高效的模型来处理大量的语音数据。其次,由于语音数据的多样性和复杂性,构建高质量的摘要模型需要大量的语音-摘要对进行训练,而这些数据往往难以获取。此外,句子级摘要需要在逐句的基础上保持信息的连贯性和完整性,这对于模型的设计和训练提出了更高的要求。为了解决这些挑战,研究人员提出了基于级联模型和端到端模型的方法,并使用了知识蒸馏技术来提高端到端模型的性能。这些方法在Mega-SSum和CSJ-SSum数据集上取得了显著的成果,但仍需进一步探索和改进。
常用场景
经典使用场景
Mega-SSum 和 CSJ-SSum 数据集被广泛应用于句级语音摘要生成任务。这些数据集提供了大量的语音、转录文本和摘要文本,为研究者提供了丰富的训练数据,以便开发高效的语音摘要模型。研究者可以利用这些数据集训练端到端模型,实现语音到文本摘要的直接转换,或者训练级联模型,将自动语音识别(ASR)和文本摘要模型相结合,以生成高质量的摘要。
解决学术问题
Mega-SSum 和 CSJ-SSum 数据集解决了句级语音摘要任务中训练数据稀缺的问题。由于语音摘要任务需要大量的语音-摘要对进行训练,而收集这些数据对成本高且耗时。Mega-SSum 和 CSJ-SSum 数据集提供了大规模的语音摘要数据,使得研究者可以更有效地训练语音摘要模型。此外,这些数据集还支持研究级联模型和端到端模型的性能差异,以及知识蒸馏技术在提升端到端模型性能方面的有效性。
衍生相关工作
Mega-SSum 和 CSJ-SSum 数据集衍生了许多相关的工作。例如,研究者利用这些数据集训练了多种语音摘要模型,包括级联模型和端到端模型,并通过实验比较了这些模型的性能。此外,研究者还利用这些数据集研究了知识蒸馏技术在提升端到端模型性能方面的有效性,以及自监督模型在语音摘要任务中的应用。这些工作为语音摘要技术的发展提供了重要的理论基础和实践经验。
以上内容由遇见数据集搜集并总结生成


