YakugakuQA
收藏Hugging Face2025-04-26 更新2025-04-27 收录
下载链接:
https://huggingface.co/datasets/EQUES/YakugakuQA
下载链接
链接失效反馈官方服务:
资源简介:
YakugakuQA是一个包含日本药剂师国家执照考试过去13年(2012-2024)的问题、答案和评论的问答数据集。该数据集由EQUES Inc.策划,用于评估大型语言模型在药学领域的知识。
创建时间:
2025-04-26
搜集汇总
数据集介绍
构建方式
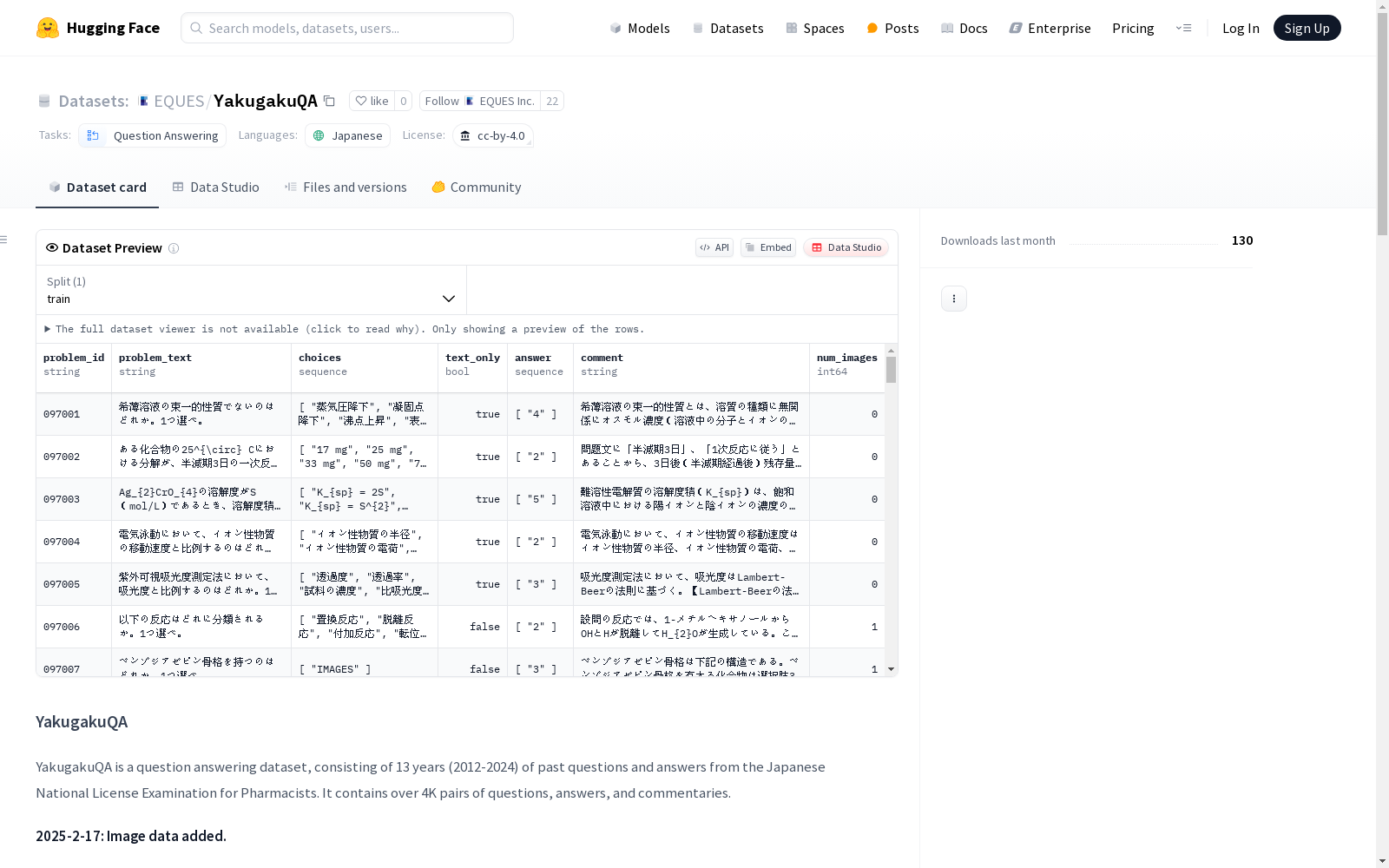
YakugakuQA数据集的构建基于日本国家药剂师执照考试历年真题,覆盖2012至2024年间的考题资源。通过自动化解析流程,系统整合了超过4000组包含问题、选项、标准答案及解析说明的数据对。每道题目均标注唯一六位数ID,高三位标识考试场次,低三位对应题号,并采用JSONL格式分层存储试题内容与元数据,其中图像类素材以独立文件形式关联。数据源严格遵循日本厚生劳动省官方出版物及第三方学术平台yakugaku lab的标准化内容。
特点
该数据集专为药学领域知识评估设计,突出表现为全日语多选试题库的构建特色。题目涵盖物理学、药理学、法律法规等九大学科类别,部分题目存在无正确答案的特殊标注。数据字段设计精细,除基础文本外还包含图像数量标记及扩展注释,其中元数据文件详细记录了试题分类体系和命题背景说明。这种结构既保留了原始考试的严谨性,又为机器学习模型提供了丰富的语义分析维度。
使用方法
作为药剂学专业语言模型的基准测试工具,建议通过加载JSONL文件直接获取结构化试题数据。研究者可依据problem_id关联主数据与元数据文件,结合text_only字段筛选纯文本题目进行基础测试,或利用category字段实现分学科能力评估。对于含图像标识的题目,需注意原始素材需另行获取。典型应用场景包括模型药学知识掌握度测试、多轮问答系统训练,但需规避超出药剂师考试范畴的迁移使用。
背景与挑战
背景概述
YakugakuQA数据集作为日本药剂师国家资格考试历年试题的集合,由EQUES Inc.在GENIAC项目的资助下精心构建,涵盖了2012至2024年间的超过4000道题目及其答案与解析。该数据集旨在为评估大型语言模型(LLMs)在药学领域的知识水平提供标准化的日语评测基准。通过整合来自yakugaku lab及日本厚生劳动省发布的官方资料,YakugakuQA不仅反映了日本药学教育的核心内容,也为自然语言处理技术在专业领域的应用开辟了新途径。
当前挑战
YakugakuQA数据集面临的挑战主要体现在两个方面:领域问题的复杂性与数据构建的技术难度。在领域问题方面,药剂师考试题目涉及药理学、化学、法律等多个学科,要求模型具备跨学科知识整合与推理能力,这对当前LLMs的专业知识深度提出了严峻考验。在数据构建过程中,原始试题包含大量图像与表格信息,但数据集仅能提供文字描述,导致信息缺失;同时,多选题与‘无解’类题目的特殊标注逻辑也增加了数据标准化处理的复杂度。
常用场景
经典使用场景
在药学领域,YakugakuQA数据集作为日本国家药剂师执照考试的历年真题库,为研究者提供了丰富的问答对资源。该数据集最经典的使用场景是作为大型语言模型(LLMs)在药学知识评估方面的基准测试工具,通过模拟真实考试环境,检验模型对复杂医药学概念的理解和推理能力。
实际应用
在实际应用中,YakugakuQA被广泛应用于智能药学教育系统的开发。基于该数据集训练的模型可辅助药剂师资格考试备考,实现个性化错题分析和知识点强化。医疗机构将其集成至临床决策支持系统,帮助快速检索药品配伍禁忌等专业信息,提升医疗服务的安全性和效率。
衍生相关工作
围绕该数据集衍生的经典工作包括跨语言药学知识迁移研究,如通过翻译增强构建多语种医疗问答系统。部分学者利用其结构化元数据开发了层次化注意力网络,显著提升了模型对复合型医药问题的处理能力。另有研究结合图像数据探索多模态药学知识表示,为药品说明书理解等场景提供新范式。
以上内容由遇见数据集搜集并总结生成


