lambdalabs/naruto-blip-captions
收藏Hugging Face2022-10-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/lambdalabs/naruto-blip-captions
下载链接
链接失效反馈官方服务:
资源简介:
# Dataset Card for Naruto BLIP captions
_Dataset used to train [TBD](TBD)._
The original images were obtained from [narutopedia.com](https://naruto.fandom.com/wiki/Narutopedia) and captioned with the [pre-trained BLIP model](https://github.com/salesforce/BLIP).
For each row the dataset contains `image` and `text` keys. `image` is a varying size PIL jpeg, and `text` is the accompanying text caption. Only a train split is provided.
## Example stable diffusion outputs

> "Bill Gates with a hoodie", "John Oliver with Naruto style", "Hello Kitty with Naruto style", "Lebron James with a hat", "Mickael Jackson as a ninja", "Banksy Street art of ninja"
## Citation
If you use this dataset, please cite it as:
```
@misc{cervenka2022naruto2,
author = {Cervenka, Eole},
title = {Naruto BLIP captions},
year={2022},
howpublished= {\url{https://huggingface.co/datasets/lambdalabs/naruto-blip-captions/}}
}
```
# 火影忍者BLIP标注数据集 数据集卡片
_本数据集用于训练[TBD(待确定)]。_
原始图像取自[narutopedia.com](https://naruto.fandom.com/wiki/Narutopedia),并通过[预训练BLIP模型(pre-trained BLIP model)]完成标注。
数据集中每一行均包含`image`与`text`两个字段。其中`image`为尺寸可变的PIL格式JPEG图像,`text`为对应的配套文本标注。本数据集仅提供训练划分。
## 稳定扩散(Stable Diffusion)生成示例

> "身着连帽衫的比尔·盖茨", "火影风格的约翰·奥利弗", "火影风格的凯蒂猫", "头戴帽子的勒布朗·詹姆斯", "化身忍者的迈克尔·杰克逊", "班克西风格的忍者街头艺术"
## 引用声明
若使用本数据集,请按如下格式引用:
@misc{cervenka2022naruto2,
author = {Cervenka, Eole},
title = {Naruto BLIP captions},
year={2022},
howpublished= {url{https://huggingface.co/datasets/lambdalabs/naruto-blip-captions/}}
}
提供机构:
lambdalabs
原始信息汇总
数据集卡片 for Naruto BLIP captions
数据集描述
原始图像来自 narutopedia.com,并使用 预训练的 BLIP 模型 进行标注。
数据结构
每行数据包含 image 和 text 键:
image:大小可变的 PIL jpeg 图像text:伴随的文本标注
数据集分割
仅提供训练集分割。
引用
如果使用此数据集,请按以下格式引用:
@misc{cervenka2022naruto2, author = {Cervenka, Eole}, title = {Naruto BLIP captions}, year={2022}, howpublished= {url{https://huggingface.co/datasets/lambdalabs/naruto-blip-captions/}} }
搜集汇总
数据集介绍
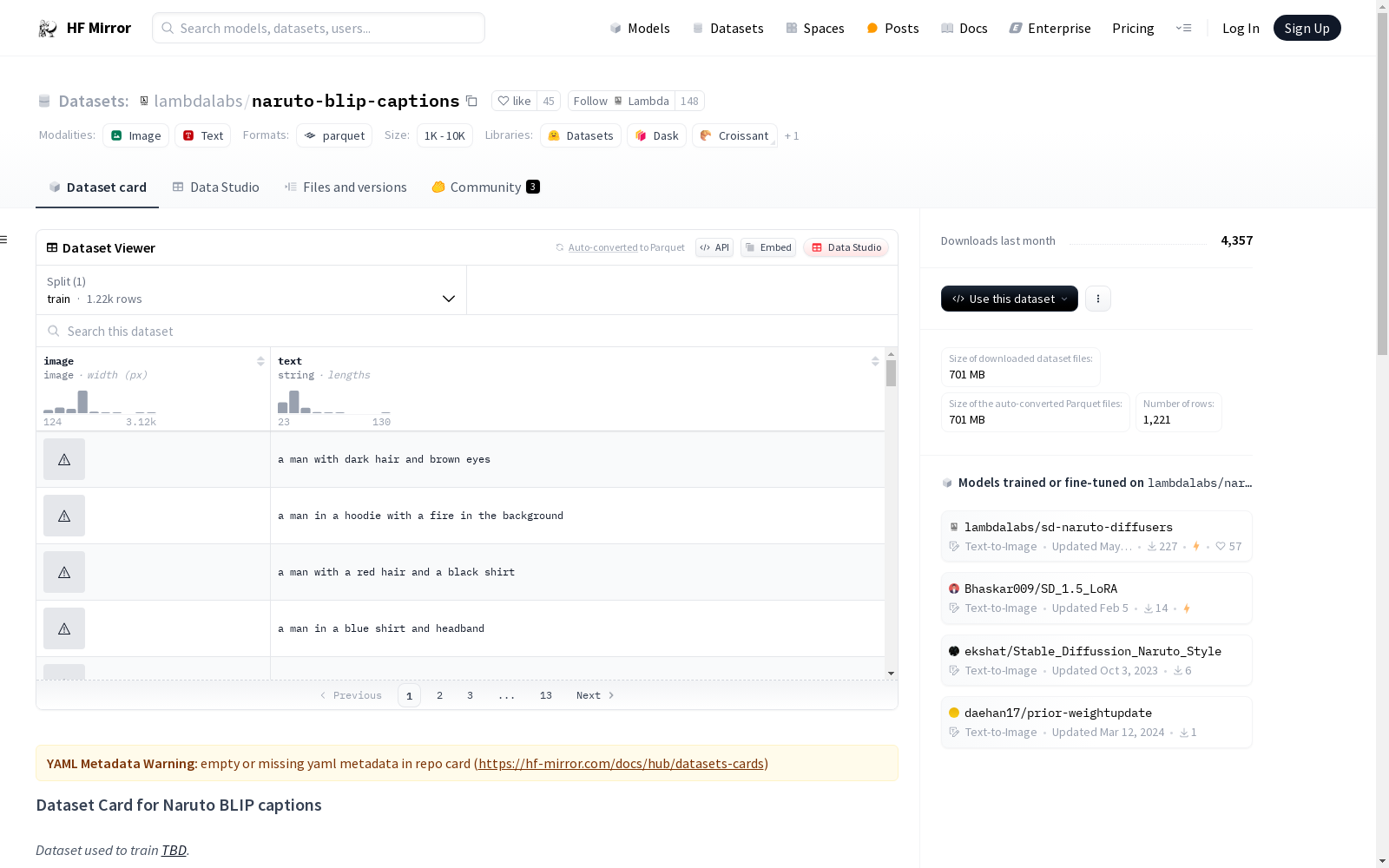
构建方式
lambdalabs/naruto-blip-captions数据集的构建,是通过采集自narutopedia.com的原始图像,并利用预训练的BLIP模型进行图像描述生成。该数据集的每一记录包含`image`和`text`两个键,`image`为不同尺寸的PIL jpeg格式图像,`text`键则是对应的文本描述。该数据集仅提供了训练集划分,以供模型训练之用。
使用方法
使用lambdalabs/naruto-blip-captions数据集时,用户可以直接通过HuggingFace的API加载训练集。由于数据集包含了图像和文本键,用户可以将其用于图像描述生成模型的训练,或者用于图像理解相关的机器学习任务中。在使用时,请遵循数据集的引用规范,正确引用数据集来源。
背景与挑战
背景概述
在计算机视觉与自然语言处理领域,图像与文本的结合成为研究的热点。Naruto BLIP captions数据集,创建于2022年,由Eole Cervenka主持,旨在推动图像描述生成技术的发展。该数据集利用了来自narutopedia.com的原始图像,并采用预训练的BLIP模型进行标注,为研究人员提供了一个结合了流行文化元素的实验平台,对图像描述、风格迁移等研究方向产生了显著影响。
当前挑战
该数据集面临的挑战主要涉及两个方面:一是图像描述的准确性,如何确保生成的文本能够准确反映图像内容;二是风格迁移的一致性,如何在保持Naruto风格的同时,确保描述文本的多样性和自然性。构建过程中,数据集的创建者需要解决图像与文本对齐、风格保持的技术难题,以及大规模数据标注的质量控制问题。
常用场景
经典使用场景
在机器学习和计算机视觉的研究领域,lambdalabs/naruto-blip-captions数据集被广泛应用于图像描述生成任务。该数据集通过结合原始图像与BLIP模型生成的文本字幕,为模型训练提供了丰富的视觉与文本关联数据,使得模型能够学习如何将图像内容转化为富有表现力的自然语言描述。
解决学术问题
该数据集有效解决了图像描述生成中的数据不足和文本-图像对齐的问题,为学术研究提供了强有力的数据支撑。其不仅提升了模型的描述准确性,还增强了生成文本的相关性和创造性,对图像理解与自然语言处理领域的结合研究具有重大意义。
实际应用
在实际应用中,lambdalabs/naruto-blip-captions数据集可用于开发智能图像描述系统,例如自动生成商品图片描述、社交媒体内容描述等,从而提高内容生成的效率和准确性,满足用户对图像内容理解的深层次需求。
数据集最近研究
最新研究方向
在计算机视觉与自然语言处理交叉领域,lambdalabs/naruto-blip-captions数据集近期引起了广泛关注。该数据集通过结合预训练的BLIP模型对 narutopedia.com 的图像进行captioning,不仅为图像描述生成任务提供了新的训练资源,而且对于探索视觉与语言融合的深度学习模型具有重要意义。目前,研究者们正致力于利用该数据集推进多模态学习的发展,特别是在图像理解、文本生成以及跨模态检索等前沿研究方向。此外,该数据集的引用也体现了其在学术界的认可度,为相关领域的学术交流和进步贡献了力量。
以上内容由遇见数据集搜集并总结生成


