---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-class-classification
- multi-label-classification
paperswithcode_id: goemotions
pretty_name: GoEmotions
config_names:
- raw
- simplified
tags:
- emotion
dataset_info:
- config_name: raw
features:
- name: text
dtype: string
- name: id
dtype: string
- name: author
dtype: string
- name: subreddit
dtype: string
- name: link_id
dtype: string
- name: parent_id
dtype: string
- name: created_utc
dtype: float32
- name: rater_id
dtype: int32
- name: example_very_unclear
dtype: bool
- name: admiration
dtype: int32
- name: amusement
dtype: int32
- name: anger
dtype: int32
- name: annoyance
dtype: int32
- name: approval
dtype: int32
- name: caring
dtype: int32
- name: confusion
dtype: int32
- name: curiosity
dtype: int32
- name: desire
dtype: int32
- name: disappointment
dtype: int32
- name: disapproval
dtype: int32
- name: disgust
dtype: int32
- name: embarrassment
dtype: int32
- name: excitement
dtype: int32
- name: fear
dtype: int32
- name: gratitude
dtype: int32
- name: grief
dtype: int32
- name: joy
dtype: int32
- name: love
dtype: int32
- name: nervousness
dtype: int32
- name: optimism
dtype: int32
- name: pride
dtype: int32
- name: realization
dtype: int32
- name: relief
dtype: int32
- name: remorse
dtype: int32
- name: sadness
dtype: int32
- name: surprise
dtype: int32
- name: neutral
dtype: int32
splits:
- name: train
num_bytes: 55343102
num_examples: 211225
download_size: 24828322
dataset_size: 55343102
- config_name: simplified
features:
- name: text
dtype: string
- name: labels
sequence:
class_label:
names:
'0': admiration
'1': amusement
'2': anger
'3': annoyance
'4': approval
'5': caring
'6': confusion
'7': curiosity
'8': desire
'9': disappointment
'10': disapproval
'11': disgust
'12': embarrassment
'13': excitement
'14': fear
'15': gratitude
'16': grief
'17': joy
'18': love
'19': nervousness
'20': optimism
'21': pride
'22': realization
'23': relief
'24': remorse
'25': sadness
'26': surprise
'27': neutral
- name: id
dtype: string
splits:
- name: train
num_bytes: 4224138
num_examples: 43410
- name: validation
num_bytes: 527119
num_examples: 5426
- name: test
num_bytes: 524443
num_examples: 5427
download_size: 3464371
dataset_size: 5275700
configs:
- config_name: raw
data_files:
- split: train
path: raw/train-*
- config_name: simplified
data_files:
- split: train
path: simplified/train-*
- split: validation
path: simplified/validation-*
- split: test
path: simplified/test-*
default: true
---
# Dataset Card for GoEmotions
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/google-research/google-research/tree/master/goemotions
- **Repository:** https://github.com/google-research/google-research/tree/master/goemotions
- **Paper:** https://arxiv.org/abs/2005.00547
- **Leaderboard:**
- **Point of Contact:** [Dora Demszky](https://nlp.stanford.edu/~ddemszky/index.html)
### Dataset Summary
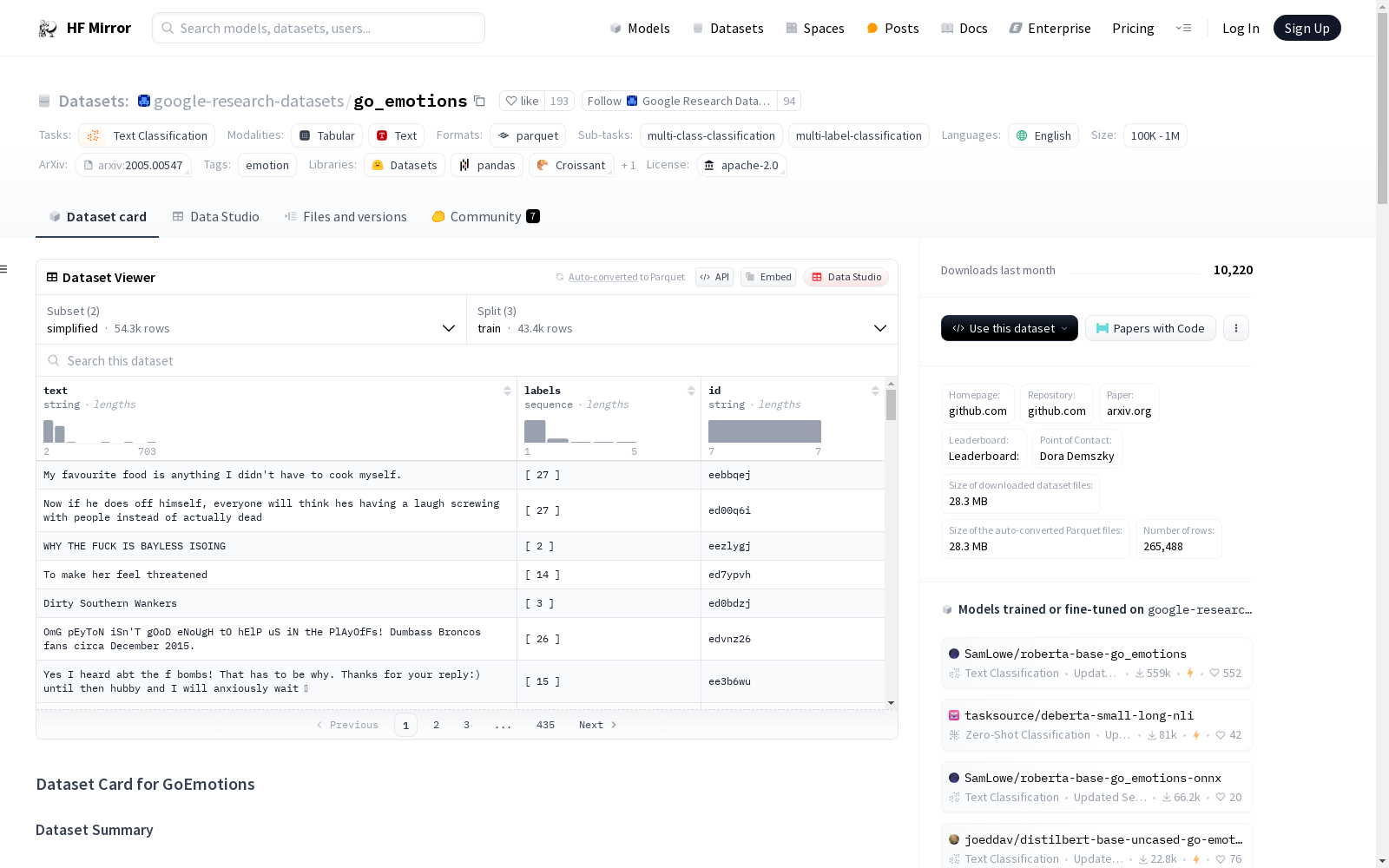
The GoEmotions dataset contains 58k carefully curated Reddit comments labeled for 27 emotion categories or Neutral.
The raw data is included as well as the smaller, simplified version of the dataset with predefined train/val/test
splits.
### Supported Tasks and Leaderboards
This dataset is intended for multi-class, multi-label emotion classification.
### Languages
The data is in English.
## Dataset Structure
### Data Instances
Each instance is a reddit comment with a corresponding ID and one or more emotion annotations (or neutral).
### Data Fields
The simplified configuration includes:
- `text`: the reddit comment
- `labels`: the emotion annotations
- `comment_id`: unique identifier of the comment (can be used to look up the entry in the raw dataset)
In addition to the above, the raw data includes:
* `author`: The Reddit username of the comment's author.
* `subreddit`: The subreddit that the comment belongs to.
* `link_id`: The link id of the comment.
* `parent_id`: The parent id of the comment.
* `created_utc`: The timestamp of the comment.
* `rater_id`: The unique id of the annotator.
* `example_very_unclear`: Whether the annotator marked the example as being very unclear or difficult to label (in this
case they did not choose any emotion labels).
In the raw data, labels are listed as their own columns with binary 0/1 entries rather than a list of ids as in the
simplified data.
### Data Splits
The simplified data includes a set of train/val/test splits with 43,410, 5426, and 5427 examples respectively.
## Dataset Creation
### Curation Rationale
From the paper abstract:
> Understanding emotion expressed in language has a wide range of applications, from building empathetic chatbots to
detecting harmful online behavior. Advancement in this area can be improved using large-scale datasets with a
fine-grained typology, adaptable to multiple downstream tasks.
### Source Data
#### Initial Data Collection and Normalization
Data was collected from Reddit comments via a variety of automated methods discussed in 3.1 of the paper.
#### Who are the source language producers?
English-speaking Reddit users.
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
Annotations were produced by 3 English-speaking crowdworkers in India.
### Personal and Sensitive Information
This dataset includes the original usernames of the Reddit users who posted each comment. Although Reddit usernames
are typically disasociated from personal real-world identities, this is not always the case. It may therefore be
possible to discover the identities of the individuals who created this content in some cases.
## Considerations for Using the Data
### Social Impact of Dataset
Emotion detection is a worthwhile problem which can potentially lead to improvements such as better human/computer
interaction. However, emotion detection algorithms (particularly in computer vision) have been abused in some cases
to make erroneous inferences in human monitoring and assessment applications such as hiring decisions, insurance
pricing, and student attentiveness (see
[this article](https://www.unite.ai/ai-now-institute-warns-about-misuse-of-emotion-detection-software-and-other-ethical-issues/)).
### Discussion of Biases
From the authors' github page:
> Potential biases in the data include: Inherent biases in Reddit and user base biases, the offensive/vulgar word lists used for data filtering, inherent or unconscious bias in assessment of offensive identity labels, annotators were all native English speakers from India. All these likely affect labelling, precision, and recall for a trained model. Anyone using this dataset should be aware of these limitations of the dataset.
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Researchers at Amazon Alexa, Google Research, and Stanford. See the [author list](https://arxiv.org/abs/2005.00547).
### Licensing Information
The GitHub repository which houses this dataset has an
[Apache License 2.0](https://github.com/google-research/google-research/blob/master/LICENSE).
### Citation Information
@inproceedings{demszky2020goemotions,
author = {Demszky, Dorottya and Movshovitz-Attias, Dana and Ko, Jeongwoo and Cowen, Alan and Nemade, Gaurav and Ravi, Sujith},
booktitle = {58th Annual Meeting of the Association for Computational Linguistics (ACL)},
title = {{GoEmotions: A Dataset of Fine-Grained Emotions}},
year = {2020}
}
### Contributions
Thanks to [@joeddav](https://github.com/joeddav) for adding this dataset.
annotations_creators:
- 众包(crowdsourced)
language_creators:
- 现有公开资源采集(found)
language:
- 英语(en)
license:
- Apache许可证2.0(apache-2.0)
multilinguality:
- 单语言(monolingual)
size_categories:
- 10万<n<100万
- 1万<n<10万
source_datasets:
- 原创数据集(original)
task_categories:
- 文本分类(text-classification)
task_ids:
- 多分类任务(multi-class-classification)
- 多标签分类任务(multi-label-classification)
paperswithcode_id: goemotions
pretty_name: GoEmotions
config_names:
- raw(原始配置)
- simplified(精简配置)
tags:
- 情绪(emotion)
dataset_info:
- config_name: raw(原始配置)
features:
- name: text
dtype: 字符串
- name: id
dtype: 字符串
- name: author
dtype: 字符串
- name: subreddit
dtype: 字符串
- name: link_id
dtype: 字符串
- name: parent_id
dtype: 字符串
- name: created_utc
dtype: float32
- name: rater_id
dtype: 有符号32位整数(int32)
- name: example_very_unclear
dtype: 布尔值(bool)
- name: admiration(钦佩)
dtype: int32
- name: amusement(愉悦感)
dtype: int32
- name: anger(愤怒)
dtype: int32
- name: annoyance(厌烦)
dtype: int32
- name: approval(赞同)
dtype: int32
- name: caring(关怀)
dtype: int32
- name: confusion(困惑)
dtype: int32
- name: curiosity(好奇)
dtype: int32
- name: desire(渴望)
dtype: int32
- name: disappointment(失望)
dtype: int32
- name: disapproval(不赞同)
dtype: int32
- name: disgust(厌恶)
dtype: int32
- name: embarrassment(尴尬)
dtype: int32
- name: excitement(兴奋)
dtype: int32
- name: fear(恐惧)
dtype: int32
- name: gratitude(感激)
dtype: int32
- name: grief(悲痛)
dtype: int32
- name: joy(喜悦)
dtype: int32
- name: love(喜爱)
dtype: int32
- name: nervousness(紧张)
dtype: int32
- name: optimism(乐观)
dtype: int32
- name: pride(自豪)
dtype: int32
- name: realization(领悟)
dtype: int32
- name: relief(释然)
dtype: int32
- name: remorse(懊悔)
dtype: int32
- name: sadness(悲伤)
dtype: int32
- name: surprise(惊讶)
dtype: int32
- name: neutral(中性)
dtype: int32
splits:
- name: train
num_bytes: 55343102
num_examples: 211225
download_size: 24828322
dataset_size: 55343102
- config_name: simplified(精简配置)
features:
- name: text
dtype: 字符串
- name: labels
sequence:
class_label:
names:
'0': 钦佩(admiration)
'1': 愉悦感(amusement)
'2': 愤怒(anger)
'3': 厌烦(annoyance)
'4': 赞同(approval)
'5': 关怀(caring)
'6': 困惑(confusion)
'7': 好奇(curiosity)
'8': 渴望(desire)
'9': 失望(disappointment)
'10': 不赞同(disapproval)
'11': 厌恶(disgust)
'12': 尴尬(embarrassment)
'13': 兴奋(excitement)
'14': 恐惧(fear)
'15': 感激(gratitude)
'16': 悲痛(grief)
'17': 喜悦(joy)
'18': 喜爱(love)
'19': 紧张(nervousness)
'20': 乐观(optimism)
'21': 自豪(pride)
'22': 领悟(realization)
'23': 释然(relief)
'24': 懊悔(remorse)
'25': 悲伤(sadness)
'26': 惊讶(surprise)
'27': 中性(neutral)
- name: id
dtype: 字符串
splits:
- name: train
num_bytes: 4224138
num_examples: 43410
- name: validation
num_bytes: 527119
num_examples: 5426
- name: test
num_bytes: 524443
num_examples: 5427
download_size: 3464371
dataset_size: 5275700
configs:
- config_name: raw(原始配置)
data_files:
- split: train
path: raw/train-*
- config_name: simplified(精简配置)
data_files:
- split: train
path: simplified/train-*
- split: validation
path: simplified/validation-*
- split: test
path: simplified/test-*
default: true
# GoEmotions数据集卡片
## 目录
- [数据集概述](#数据集概述)
- [数据集摘要](#数据集摘要)
- [支持任务与排行榜](#支持任务与排行榜)
- [语言](#语言)
- [数据集结构](#数据集结构)
- [数据实例](#数据实例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [构建依据](#构建依据)
- [源数据](#源数据)
- [标注](#标注)
- [个人与敏感信息](#个人与敏感信息)
- [数据集使用注意事项](#数据集使用注意事项)
- [数据集的社会影响](#数据集的社会影响)
- [偏见讨论](#偏见讨论)
- [其他已知局限性](#其他已知局限性)
- [附加信息](#附加信息)
- [数据集整理者](#数据集整理者)
- [许可信息](#许可信息)
- [引用信息](#引用信息)
- [贡献致谢](#贡献致谢)
## 数据集概述
- **项目主页**:https://github.com/google-research/google-research/tree/master/goemotions
- **代码仓库**:https://github.com/google-research/google-research/tree/master/goemotions
- **论文**:https://arxiv.org/abs/2005.00547
- **排行榜**:
- **联系人**:[多罗特亚·德姆茨基(Dora Demszky)](https://nlp.stanford.edu/~ddemszky/index.html)
### 数据集摘要
GoEmotions数据集包含5.8万条经过精心整理的Reddit论坛评论,标注了27种情绪类别或中性标签。数据集同时提供原始版本与精简版本,其中精简版本已预定义训练集、验证集与测试集划分。
### 支持任务与排行榜
本数据集适用于多分类、多标签情绪分类任务。
### 语言
本数据集采用英语。
## 数据集结构
### 数据实例
每条数据为一条Reddit论坛评论,附带唯一标识符以及一项或多项情绪标注(或中性标签)。
### 数据字段
精简配置包含以下字段:
- `text`:Reddit论坛评论内容
- `labels`:情绪标注
- `comment_id`:评论的唯一标识符(可用于在原始数据集中检索对应条目)
除上述字段外,原始数据集还包含以下额外字段:
* `author`:评论作者的Reddit用户名
* `subreddit`:评论所属的Reddit子版块
* `link_id`:评论的链接ID
* `parent_id`:评论的父级ID
* `created_utc`:评论的UTC时间戳
* `rater_id`:标注者的唯一标识符
* `example_very_unclear`:标注者是否标记该示例非常模糊、难以标注(此种情况下标注者未选择任何情绪标签)
在原始数据集中,标签以独立的二进制0/1列形式呈现,而非精简数据集中的ID列表形式。
### 数据划分
精简数据集包含训练集、验证集与测试集,样本数量分别为43410、5426与5427。
## 数据集构建
### 构建依据
摘自论文摘要:
> 理解语言中表达的情绪具有广泛应用场景,从构建共情聊天机器人到检测有害网络行为。借助具备细粒度分类体系、可适配多种下游任务的大规模数据集,可推动该领域的研究进展。
### 源数据
#### 初始数据采集与标准化
数据通过多种自动化方法从Reddit论坛评论中采集,详情参见论文3.1节。
#### 源语言生产者是谁?
数据来自英语使用者的Reddit论坛用户。
### 标注
#### 标注流程
[需更多信息]
#### 标注者是谁?
标注工作由印度的3名英语母语众包标注者完成。
### 个人与敏感信息
本数据集包含每条评论原作者的Reddit用户名。尽管Reddit用户名通常与真实身份无直接关联,但并非绝对如此,在部分场景下仍有可能据此追溯到发布内容的个体身份。
## 数据集使用注意事项
### 数据集的社会影响
情绪检测是一项极具价值的研究课题,有望推动人机交互等领域的改进。然而,情绪检测算法(尤其是计算机视觉领域的相关算法)在部分场景中已被滥用,例如在招聘决策、保险定价、学生注意力评估等人类监测与评估应用中做出错误推断(详见[此文章](https://www.unite.ai/ai-now-institute-warns-about-misuse-of-emotion-detection-software-and-other-ethical-issues/))。
### 偏见讨论
摘自作者GitHub页面的说明:
> 本数据集存在的潜在偏见包括:Reddit平台及其用户群体本身的固有偏见、数据过滤所用的冒犯性/粗俗词汇列表的偏差、对冒犯性身份标签评估时的固有或无意识偏见,以及所有标注者均为印度英语母语者这一因素。这些因素均可能影响训练模型的标注效果、精确率与召回率。使用本数据集的人员应充分了解该数据集的上述局限性。
### 其他已知局限性
[需更多信息]
## 附加信息
### 数据集整理者
本数据集由亚马逊Alexa、谷歌研究院与斯坦福大学的研究人员整理完成,详见[作者列表](https://arxiv.org/abs/2005.00547)。
### 许可信息
托管本数据集的GitHub仓库采用[Apache许可证2.0(Apache License 2.0)](https://github.com/google-research/google-research/blob/master/LICENSE)。
### 引用信息
bibtex
@inproceedings{demszky2020goemotions,
author = {Demszky, Dorottya and Movshovitz-Attias, Dana and Ko, Jeongwoo and Cowen, Alan and Nemade, Gaurav and Ravi, Sujith},
booktitle = {58th Annual Meeting of the Association for Computational Linguistics (ACL)},
title = {{GoEmotions: A Dataset of Fine-Grained Emotions}},
year = {2020}
}
### 贡献致谢
感谢[@joeddav](https://github.com/joeddav)为本数据集添加至相关平台。