talkmap/telecom-conversation-corpus
收藏Hugging Face2024-03-15 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/talkmap/telecom-conversation-corpus
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- text-generation
language:
- en
tags:
- conversation
- telecom
pretty_name: telecom-200k
size_categories:
- 100K<n<1M
---
# Telecom 200k Dataset Overview
This dataset consists of 200,000 synthetically generated conversations in a customer service setting for the telecom industry. There are two speakers: a customer, and an agent.
---
许可证:MIT许可证
任务类别:
- 文本生成(text-generation)
语言:
- 英语(en)
标签:
- 对话(conversation)
- 电信(telecom)
展示名称:电信200k(telecom-200k)
规模类别:
- 10万<样本数<100万
---
# 电信200k数据集概览
本数据集包含20万条合成生成的电信行业客服场景对话,对话双方分别为客户与客服专员。
提供机构:
talkmap
原始信息汇总
Telecom 200k 数据集概述
数据集信息
- 许可证: MIT
- 任务类别: 文本生成
- 语言: 英语
- 标签: 对话, 电信
- 易读名称: telecom-200k
- 大小类别: 100K<n<1M
数据集内容
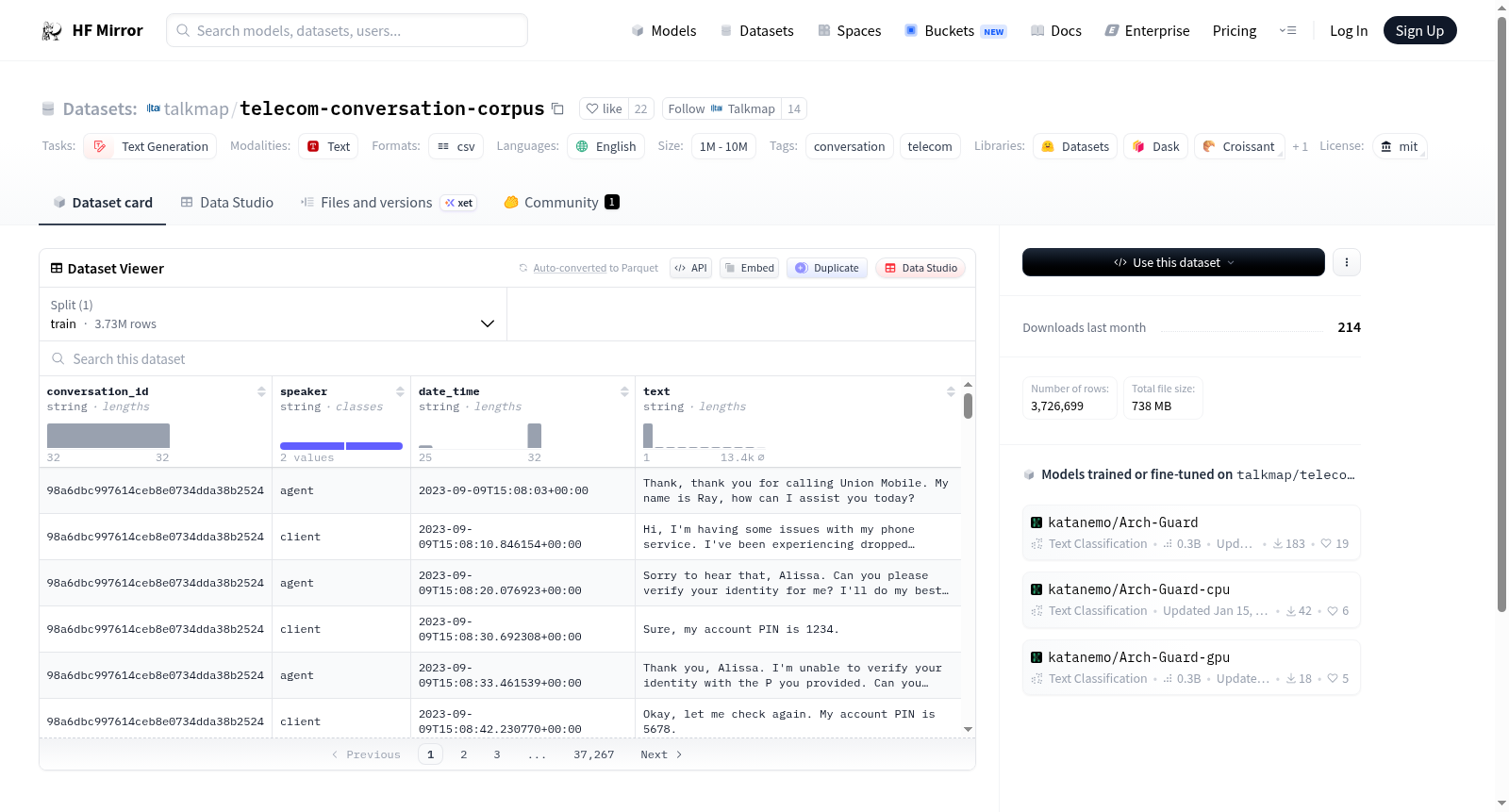
该数据集包含200,000条在电信行业客户服务场景中合成生成的对话。对话涉及两个角色:客户和代理。
搜集汇总
数据集介绍
构建方式
在电信行业客户服务领域,高质量对话数据对模型训练至关重要。该数据集通过合成生成技术构建,包含20万条模拟客户与客服代理之间的双人对话。构建过程聚焦电信业务场景,确保对话内容覆盖常见服务诉求与标准响应流程,从而形成结构化的交互语料库。
特点
数据集的核心特点在于其规模与领域专精性。20万条对话样本为文本生成任务提供了充足训练素材,同时严格限定于电信客户服务语境,使模型能精准学习行业术语与服务规范。此外,对话采用双角色设计,自然呈现问题咨询与解决方案的完整交互链。
使用方法
该数据集主要面向文本生成任务,适用于训练对话式AI模型。使用时可直接加载原始对话文本,按客户与代理角色分离输入输出对。建议将数据划分为训练集与验证集,通过监督学习使模型掌握电信场景下的上下文响应逻辑,或用于微调预训练语言模型以适配特定业务需求。
背景与挑战
背景概述
在自然语言处理与对话系统研究领域,电信行业作为高度依赖客户交互的服务密集型产业,其客服对话数据对于训练领域特定语言模型具有重要价值。talkmap/telecom-conversation-corpus数据集由研究团队于近期创建,包含20万条合成生成的英文客服对话记录,模拟客户与客服代理之间的双向交流场景。该数据集旨在弥补真实电信客服数据因隐私保护、标注成本高昂而难以获取的缺陷,为文本生成任务提供大规模、结构化的领域训练资源。其发布有望推动电信行业智能客服系统的语义理解与对话生成能力提升,并为跨领域对话系统的迁移学习研究奠定基础。
当前挑战
该数据集当前面临的核心挑战体现在两个层面。在领域问题层面,合成数据与真实客服对话在语言多样性、非规范表述及情绪波动上的差异,可能导致模型在部署时产生领域漂移,难以精准识别客户意图与解决复杂投诉。在构建过程中,人工设计的对话模板难以覆盖电信业务中多变的套餐规则、技术故障场景及合规性要求,使得生成对话的生态效度受限。此外,缺乏对长程依赖关系与多轮对话逻辑一致性的显式建模,可能影响模型在真实场景下的鲁棒性,亟需通过混合真实数据微调或对抗性验证来缓解这些局限。
常用场景
经典使用场景
在自然语言处理与对话系统研究领域,talkmap/telecom-conversation-corpus数据集以其高度结构化的电信客服对话内容,成为训练和评估文本生成模型的重要资源。该数据集包含20万条合成生成的客服对话,涵盖客户与坐席之间的双向交流,为研究者提供了规模可观且领域聚焦的训练语料。经典使用场景包括基于大型语言模型的对话生成、意图识别与槽位填充任务,以及面向特定行业的多轮对话系统构建,尤其适用于电信服务场景下的自动应答与问题解决能力优化。
解决学术问题
该数据集的核心学术价值在于为电信行业的对话系统研究提供了标准化、可复现的基准语料,有效缓解了真实客服数据获取困难、隐私保护与标注成本高昂等长期困扰学界的问题。它推动了面向特定垂直领域的对话生成模型发展,使研究者能够深入探索领域自适应、少样本学习与对话策略优化等关键问题。通过提供合成但逼真的交互样本,该数据集还促进了对话质量评估指标的设计与验证,为构建鲁棒、高效的人机交互系统奠定了数据基础。
衍生相关工作
基于该数据集,研究者已衍生出多项代表性工作,包括面向电信领域的对话状态追踪模型、融合领域知识的可控文本生成方法,以及利用对比学习增强对话语义理解的框架。部分工作进一步扩展了数据集规模,引入多语言版本或跨场景迁移学习策略,探索合成数据在真实世界对话系统泛化能力提升中的作用。这些衍生研究不仅丰富了对话系统的方法论体系,也为其他垂直行业(如金融、医疗)的合成数据构建与模型训练提供了可借鉴的范式。
以上内容由遇见数据集搜集并总结生成


