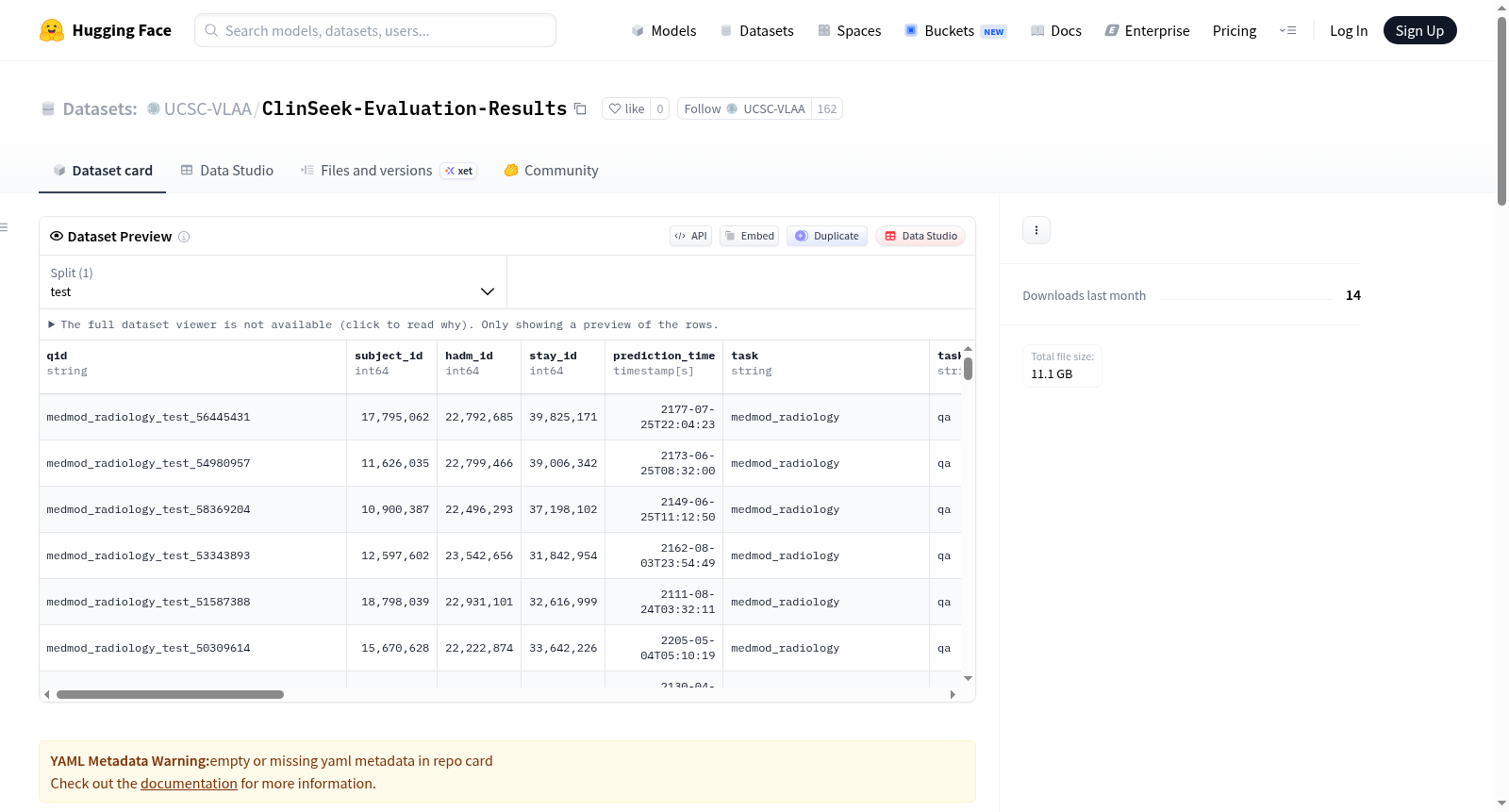
ClinSeek-Evaluation-Results
收藏Hugging Face2026-05-16 更新2026-05-17 收录
下载链接:
https://huggingface.co/datasets/UCSC-VLAA/ClinSeek-Evaluation-Results
下载链接
链接失效反馈官方服务:
资源简介:
本README文件描述了一个用于存储和整理医疗人工智能基准测试评估结果的目录结构。该目录包含三个主要基准测试的输出:1) EHR-Bench(文本型电子健康记录基准),包含1800行数据和45个任务,支持单次(oneshot)和多轮智能体(agentic)两种运行模式;2) AgentEHR-Bench,包含600行数据和6个基于MIMIC数据集的任务,仅支持多轮智能体模式;3) MM Bench(多模态电子健康记录基准),包含2703行数据和6个任务,支持单次和多轮智能体模式,后者涉及图像和EHR工具调用。评估结果按基准、运行模式和模型进行分层组织,关键输出文件为results.jsonl。目录中还记录了用于评估的多个大型语言模型(如Claude Opus、Qwen3-VL等)的标准化命名,并包含一个归档目录用于存放历史或未完成的运行记录。该结构旨在系统化地管理和比较不同模型在医疗任务上的性能表现。
This README file describes a directory structure for storing and organizing evaluation results of medical artificial intelligence benchmarks. The directory includes outputs from three main benchmarks: 1) EHR-Bench (text-based Electronic Health Record benchmark), containing 1800 rows of data and 45 tasks, supporting both oneshot and agentic (multi-turn) run modes; 2) AgentEHR-Bench, containing 600 rows of data and 6 tasks based on the MIMIC dataset, supporting only the multi-turn agentic mode; 3) MM Bench (multimodal Electronic Health Record benchmark), containing 2703 rows of data and 6 tasks, supporting oneshot and agentic modes, with the latter involving image and EHR tool calls. Evaluation results are organized hierarchically by benchmark, run mode, and model, with the key output file being results.jsonl. The directory also records standardized naming for multiple large language models used in evaluation (such as Claude Opus, Qwen3-VL, etc.), and includes an archive directory for storing historical or incomplete runs. This structure aims to systematically manage and compare the performance of different models on medical tasks.
提供机构:
UCSC-VLAA
创建时间:
2026-05-16
原始信息汇总
数据集概述:ClinSeek-Evaluation-Results
该数据集包含面向临床基准的评估输出结果,按 基准测试 × 运行模式 × 模型 的结构进行组织。
目录结构
数据集的根目录下包含四个主要子目录:
| 目录 | 说明 |
|---|---|
ehr_bench/ |
纯文本 EHR-Bench 基准(1800 行,45 个任务) |
agent_ehr_bench/ |
AgentEHR-Bench 基准(600 行,6 个 MIMIC 任务),通过符号链接指向外部评估目录 |
mm_bench/ |
多模态 EHR-Bench 基准(2703 行,6 个任务) |
_archive/ |
归档目录,存放被取代、半完成或早期实验的运行结果 |
每个基准目录下又分为 agentic(多轮工具调用)和 oneshot(单次调用)两种运行模式,每种模式包含 smoke20/ 和 full1800/(或 full2703/、subset600/)子目录,以及可选的 scored/ 评分结果目录。
模型命名约定
所有叶子目录使用蛇形小写命名:
| 友好名称 | 目录名 |
|---|---|
| Claude Opus 4.6 | claude_opus_4_6 |
| Claude Sonnet 4.6 | claude_sonnet_4_6 |
| Qwen3-VL-235B | qwen3_vl_235b |
| Qwen3-235B | qwen3_235b |
| Kimi K2.5 | kimi_k2_5 |
| GLM-4.7 | glm_4_7 |
| MiniMax M2.5 | minimax_m2_5 |
| gpt-oss-120b | gpt_oss_120b |
关键结果文件位置
EHR-Bench 基准:
- Agentic 模式完整结果:
ehr_bench/agentic/full1800/<model>/results.jsonl - One-shot 模式完整结果:
ehr_bench/oneshot/full1800/<model>/results.jsonl
AgentEHR-Bench 基准:
- Agentic 模式完整结果:
agent_ehr_bench/agentic/subset600/<model>/results.jsonl
多模态基准:
- Agentic 模式完整结果:
mm_bench/agentic/full2703/<model>/(Opus 模型在results.jsonl,其他模型在merged_unique.jsonl) - Agentic 模式评分结果:
mm_bench/agentic/scored/<model>/summary_vocab.{json,md} - One-shot 模式完整结果:
mm_bench/oneshot/full2703/<model>/results.jsonl - One-shot 模式评分结果:
mm_bench/oneshot/scored/<model>/summary.{json,md}
多模态 agentic 符号链接说明
五个非 Anthropic 模型的多模态 agentic 运行结果通过符号链接指向 _multi_eval_raw/ 目录下的原始输出,以便于浏览。例如:
mm_bench/agentic/full2703/claude_sonnet_4_6→_multi_eval_raw/full5_20260421T091517Z/claude-sonnet-4-6mm_bench/agentic/scored/claude_sonnet_4_6→../full2703/_multi_eval_raw/full5_20260421T091517Z/scored_vocab/claude-sonnet-4-6
Claude Opus 4.6 的多模态 agentic 结果为真实目录,由独立的 Opus-solo 运行产生。
归档目录内容
_archive/ 包含:
- 半完成的运行(如
ehr_bench_opus46_1800_pre_ssl_retry) - 重复或修复后的重新运行(如
ehr_bench_smoke20_salvage_patched_*) - 早期多模态实验运行(如
mm_agentic_smoke5_early) - 合并前的重试输出(如
ehr_bench_oneshot_full1800_kimi_k2_5_pre_retry) - 早期非词汇表评分的多模态输出(如
mm_agentic_opus_scored_novocab)
搜集汇总
数据集介绍
构建方式
ClinSeek-Evaluation-Results数据集以严谨的层次化结构组织,按三大基准测试(EHR-Bench、AgentEHR-Bench、MM-Bench)与两种运行模式(agentic多轮工具调用与oneshot单次推理)进行交叉分类。每个基准测试下,模型输出以蛇形命名法的模型简称(如claude_opus_4_6)存放于对应目录,并包含results.jsonl原始轨迹文件、run.log日志及per-region分片数据。对于多模态agentic实验,非Anthropic模型的运行结果通过符号链接指向原始批处理目录(_multi_eval_raw),而Claude Opus系列则因独立运行而保留真实目录,确保了数据溯源的可审计性。废弃或中间产物统一归入_archive目录,供后续核查。
特点
该数据集的独到之处在于其多维度、多模态的评估框架。它横跨文本型EHR-Bench(1800行、45项任务)、AgentEHR-Bench(600行、6项MIMIC任务)以及多模态MM-Bench(2703行、6项任务),全面覆盖临床推理与工具调用场景。模型输出不仅包括原始的agentic多轮对话轨迹和推理过程,还提供了经过词汇级评分(vocab scoring)的摘要文件(summary.json与summary.md),便于直接获取量化指标。此外,通过符号链接机制统一管理跨实验的异构目录结构,兼顾了浏览便利性与原始数据的完整性。
使用方法
研究者可直接依据规范路径检索特定模型与任务的结果:如EHR-Bench agentic完整运行结果位于ehr_bench/agentic/full1800/<model>/results.jsonl,而多模态agentic的已评分摘要则存放于mm_bench/agentic/scored/<model>/summary_vocab.json。对于需要复现完整推理轨迹或进行细粒度错误分析的工作,可解析results.jsonl文件中的每一步调用记录;若仅关注最终量化表现,则直接使用scored目录下的summary文件。废弃实验的中间产物位于_archive目录,供30天内的审计与回溯使用。
背景与挑战
背景概述
ClinSeek-Evaluation-Results数据集由研究团队构建,旨在系统评估大语言模型在电子健康记录(EHR)临床决策支持场景中的表现。该数据集创建于2026年,通过整合text-only的EHR-Bench、多模态的MM-Bench以及AgentEHR-Bench三大基准,涵盖了从单次推理到多轮工具调用的多种运行模式,并纳入了Claude Opus、Qwen3-VL、Kimi K2.5等前沿模型。其核心研究问题聚焦于评估语言模型在结构化与非结构化医疗数据上的推理能力、多模态融合能力以及智能体交互能力。该数据集为临床自然语言处理领域提供了标准化的评估框架,推动了医疗AI模型的可复现性研究与基准测试的规范化发展。
当前挑战
该数据集面临的核心挑战包括:首先,医疗领域的评估任务具有高度专业性与复杂性,如EHR-Bench覆盖45项分类任务,要求模型精准理解临床术语与上下文,而MM-Bench则需处理文本与影像等多模态信息的协同推理,这对模型的知识广度与跨模态对齐能力构成严峻考验。其次,在数据构建层面,多模型、多基准的评估流程引入了显著的工程复杂性,例如不同模型的输出格式与路径需要统一管理,多轮工具调用场景下的日志、结果与评分文件需规范化存储,且需处理来自不同运行批次(如Opus单独运行与多模型联合运行)的输出差异性。此外,早期运行产生的废弃数据(如_archive中的半完成或补丁实验)需要审慎管理,以避免干扰最终结果的溯源性,同时确保评估流程的可重复性与透明度。
常用场景
经典使用场景
ClinSeek-Evaluation-Results数据集专为评估临床大型语言模型在电子健康记录(EHR)场景下的表现而设计。其经典使用场景涵盖三大基准测试:EHR-Bench包含1800行、45项临床任务,用于评估模型在纯文本诊疗决策中的准确性;AgentEHR-Bench包含600行、6项MIMIC任务,重点考察模型在工具调用和智能体协作中的执行能力;MM-Bench包含2703行、6项多模态任务,用于验证模型结合医学图像与EHR文本信息的综合推理能力。该数据集支持agentic多轮交互和one-shot单次推理两种模式,为评估不同复杂度临床场景下的模型行为提供了标准化框架。
实际应用
在实际临床应用中,该数据集评估结果可指导医院信息系统和临床决策支持工具的模型选型。基于EHR-Bench评测结果,医疗机构能够选择在用药推荐、疾病诊断、风险预测等文本任务上表现最佳的语言模型;AgentEHR-Bench的评测结论有助于筛选出能够执行多步骤操作(如检查申请、转诊安排)的智能体模型;MM-Bench的评估则直接服务于整合影像报告与病程记录的辅助诊断系统开发。此外,评测数据还为联邦学习框架下的模型性能监控、部署前的鲁棒性压力测试以及不同规模模型之间的性价比权衡提供了实证依据。
衍生相关工作
该数据集衍生出一系列重要的后续研究工作。基于EHR-Bench的评测结果,研究者提出了针对临床术语理解的领域自适应微调方法,显著提升了通用模型在文本诊疗任务上的准确率。AgentEHR-Bench的评估数据催生了多轮临床对话中工具调用策略的优化算法,通过强化学习调整模型的行动序列规划。MM-Bench的多模态评估结果则推动了视觉-语言联合预训练架构的发展,如设计跨模态注意力机制以更好地融合医学图像与结构化病历信息。此外,该数据集的评测框架本身也已被多个医疗AI竞赛采纳为标准化评估方案,激励了更为实用的临床大模型技术路线探索。
以上内容由遇见数据集搜集并总结生成


