handwritten-text-recognition-bongabdo
收藏Hugging Face2025-06-18 更新2025-06-19 收录
下载链接:
https://huggingface.co/datasets/deepcopy/handwritten-text-recognition-bongabdo
下载链接
链接失效反馈官方服务:
资源简介:
Bongabdo是一个经过策划的孟加拉语手写文本完整页面数据集,适用于现代神经网络架构的离线手写识别任务。它包含高分辨率的手写孟加拉语文本扫描图像、转录和丰富的每文档元数据。该数据集由不同年龄、职业和性别的众多人士贡献,非常适合训练在多种手写风格上具有良好泛化能力的鲁棒手写识别模型。
创建时间:
2025-06-18
原始信息汇总
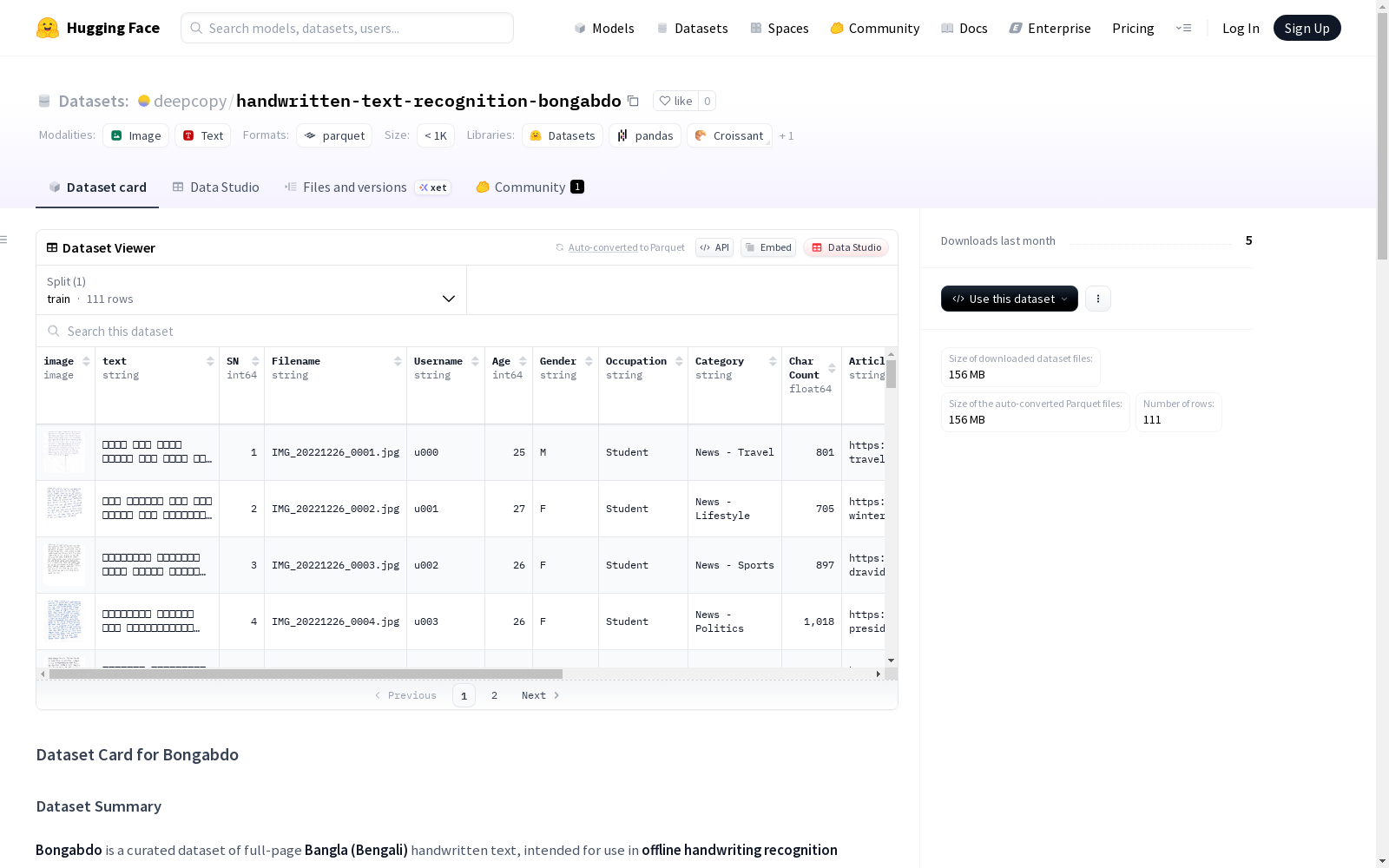
Bongabdo 数据集概述
数据集摘要
- Bongabdo 是一个经过整理的孟加拉语(Bengali)全页手写文本数据集,专为使用现代神经架构的离线手写识别任务设计。
- 包含高分辨率扫描的孟加拉语手写文本图像、转录文本以及丰富的每文档元数据。
- 数据由不同年龄、职业和性别的贡献者提供,适合训练能够跨手写风格泛化的鲁棒手写识别模型。
- 该数据集特别有价值,因为孟加拉语在手写数据集方面属于低资源语言。
支持任务
- 离线手写文本识别 (HTR)
- 文档布局理解(潜在用途,利用区域级元数据)
- 孟加拉语自然语言处理预处理(从人类手写体中)
数据集结构
特征
| 列名 | 类型 | 描述 |
|---|---|---|
image |
图像 | 全页扫描的孟加拉语手写文档。 |
text |
字符串 | 手写文本的转录(Unicode 孟加拉语)。 |
SN |
int64 | 示例的序列号。 |
Filename |
字符串 | 图像和注释文件的名称。 |
Username |
字符串 | 匿名贡献者 ID。 |
Age |
int64 | 作者的年龄。 |
Gender |
字符串 | 作者的性别(M/F)。 |
Occupation |
字符串 | 作者的职业(例如,学生)。 |
Category |
字符串 | 文本的主题类别(例如,新闻 - 旅行)。 |
Char Count |
float64 | 转录文本中的字符数。 |
Article link |
字符串 | 原始来源 URL(用于键入文本,非手写)。 |
Strike |
bool | 手写是否包含删除线。 |
Bangla - English |
bool | 文本是否包含孟加拉语和英语之间的代码切换。 |
Multi - Paragraph |
bool | 文档是否包含多个段落。 |
数据分割
当前版本未包含预定义训练/验证/测试分割。鼓励用户根据需要自行分割数据集。
使用示例
python from datasets import load_dataset
ds = load_dataset("deepcopy/handwritten-text-recognition-bongabdo") sample = ds["train"][0] sample["image"].show() print(sample["text"])
引用
如果使用此数据集,请引用以下论文: bibtex @inproceedings{ghosh2023bangla, title={Towards Full-page Offline Bangla Handwritten Text Recognition using Image-to-Sequence Architecture}, author={Ghosh, Ayanabha}, booktitle={IEEE Silchar Subsection Conference}, year={2023}, address={Silchar, Assam, India} }
许可
Attribution 4.0 International (CC BY 4.0)
搜集汇总
数据集介绍
构建方式
Bongabdo数据集专注于孟加拉语手写文本识别领域,其构建过程体现了严谨的学术规范。该数据集通过系统性地收集来自不同年龄、职业和性别群体的全页孟加拉语手写文档,采用高分辨率扫描技术获取图像数据。每份样本均包含精确的Unicode文本转录,并附加了丰富的元数据标注,如书写者特征、文本类别等。数据采集过程严格遵循研究伦理,采用匿名化处理保护贡献者隐私,最终形成包含111个高质量样本的数据集。
特点
该数据集最显著的特点是针对低资源孟加拉语手写文本的全面覆盖。样本不仅包含高分辨率扫描图像和精确转录,还提供了书写者年龄、职业等人口统计学特征,以及文本是否包含删除线、双语混用等多维度标注。这种细粒度的元数据设计使得数据集特别适合研究手写风格变异性和文档布局理解。作为IEEE会议论文的配套数据集,其学术价值在孟加拉语OCR领域具有开创性意义。
使用方法
使用该数据集时,研究人员可通过Hugging Face的datasets库直接加载,采用标准化的Python接口访问图像和标注数据。由于数据集未预设标准划分,建议用户根据具体任务需求,使用train_test_split等方法自定义数据分割策略。典型应用场景包括端到端手写文本识别模型训练、多语言混合文本处理研究,以及结合元数据的书写风格分析等。数据集采用CC BY 4.0许可,使用时需按规定引用原始论文。
背景与挑战
背景概述
Bongabdo数据集由Ayanabha Ghosh于2023年提出,旨在解决孟加拉语离线手写文本识别的关键问题。作为低资源语言处理领域的重要补充,该数据集收录了来自不同年龄、职业和性别群体的全页孟加拉语手写文档,包含高分辨率扫描图像及对应转录文本。其创新性体现在首次实现了对孟加拉语完整页面的手写文本识别研究,相关成果发表于IEEE Silchar分会会议,为南亚语系文字处理提供了基准数据支持。数据集丰富的元数据特征,如书写者属性、文本类别等,为研究手写风格变异与识别性能的关系奠定了重要基础。
当前挑战
该数据集面临的核心挑战主要体现在两方面:在领域问题层面,孟加拉语复杂的连字结构和书写风格的高度个性化导致传统OCR技术识别准确率受限,特别是处理全页文档时的段落分割与行序识别问题更为突出;在构建过程中,需克服多书写者样本采集的协调难度,确保扫描图像质量的一致性,同时精确标注包含代码转换(孟加拉语-英语)和删除线等特殊情况的文本。此外,当前数据规模相对有限,对深度学习模型的泛化能力构成挑战,需通过数据增强等技术手段加以缓解。
常用场景
经典使用场景
在自然语言处理与计算机视觉交叉领域,Bongabdo数据集为孟加拉语离线手写文本识别提供了重要研究基础。该数据集通过收录不同年龄、职业和性别的书写者样本,构建了具有丰富多样性的孟加拉语手写文本库。研究者通常利用其高分辨率扫描图像和对应转录文本,训练端到端的图像序列转换模型,实现从手写图像到可编辑文本的自动转换。
实际应用
在实际应用层面,该数据集支撑的识别技术可广泛应用于孟加拉语地区的教育数字化、历史档案电子化等领域。银行支票处理、政府表格自动录入等商业场景同样受益于此类技术。特别值得注意的是,包含不同职业书写者样本的特性,使训练模型能更好地适应真实场景中的笔迹变异问题。
衍生相关工作
基于该数据集的经典研究包括Ghosh提出的全页式孟加拉语手写识别框架,该工作采用图像序列架构实现了端到端识别。后续研究进一步探索了多模态特征融合、注意力机制优化等方向,部分成果已应用于孟加拉语OCR系统开发。数据集包含的丰富元数据也催生了书写风格分析与人口统计学关联研究等衍生方向。
以上内容由遇见数据集搜集并总结生成


