TinyStories-mini-Interaction-SFT
收藏Hugging Face2025-05-17 更新2025-05-18 收录
下载链接:
https://huggingface.co/datasets/ReactiveAI/TinyStories-mini-Interaction-SFT
下载链接
链接失效反馈官方服务:
资源简介:
这是一个基于TinyStories数据集的监督微调数据集,专为Reactive Transformer模型的第二训练阶段概念验证而制作。数据集包含query和answer字段,模拟对话中的问题和回答,但不包含实际世界知识,仅包含关于合成生成简单故事的问答。
创建时间:
2025-05-10
原始信息汇总
数据集概述:ReactiveAI/TinyStories-mini-Interaction-SFT
数据集基本信息
- 许可证: Apache-2.0
- 语言: 英语 (en)
- 大小分类: 10K<n<100K
- 任务类别: 问答、文本生成、填充掩码
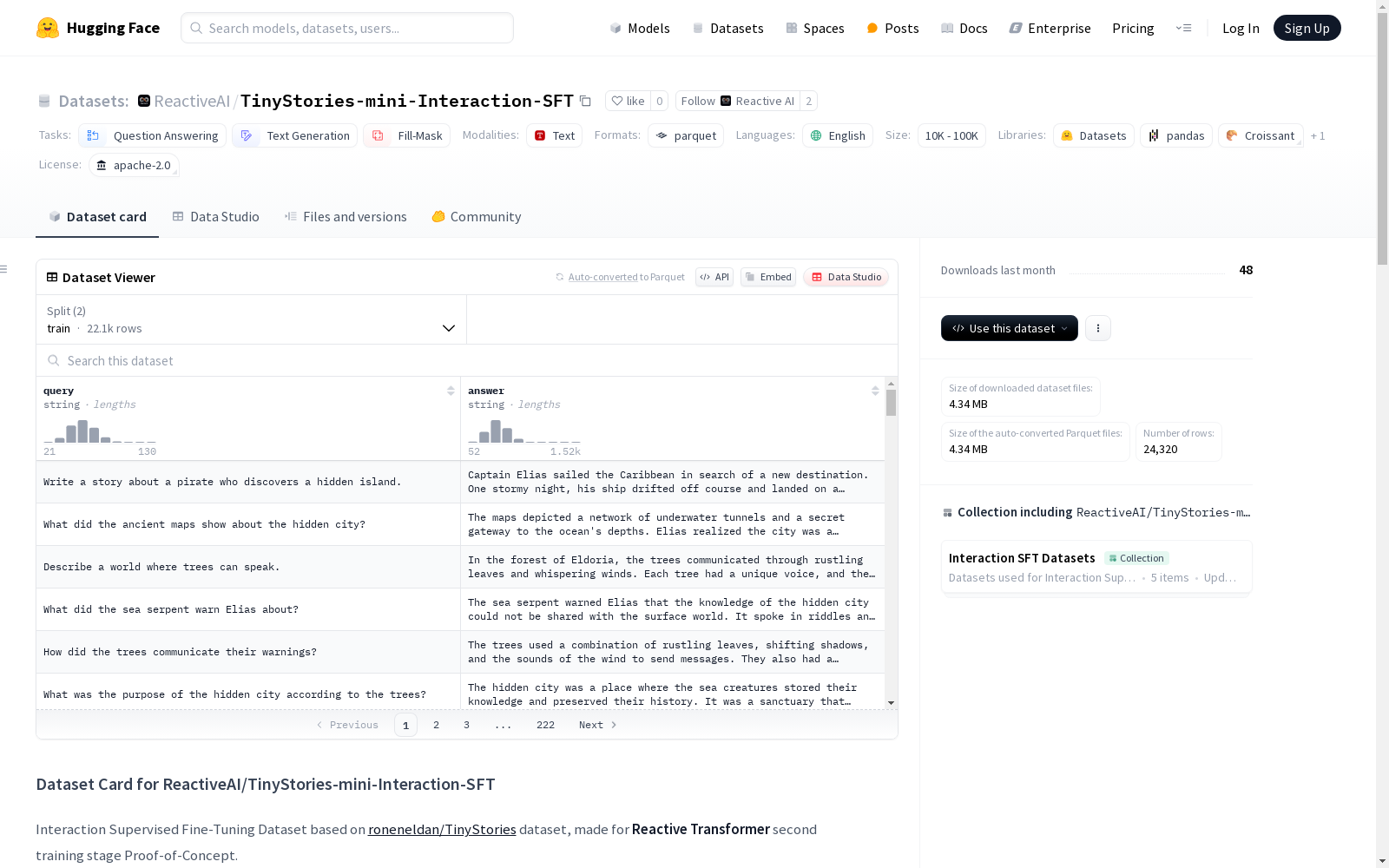
数据集结构
- 特征:
query: 字符串类型answer: 字符串类型
- 数据分块:
train: 22,147 个样本,11,498,744 字节validation: 2,173 个样本,1,112,918 字节
- 下载大小: 4,341,920 字节
- 数据集大小: 12,611,662 字节
数据集用途
- 直接用途: 用于研究目的,特别是针对小型模型的监督微调。
- 超出范围用途: 不适用于生产模型,因为数据集中不包含真实世界知识。
数据集创建
- 策划者: Reactive AI
- 数据来源: 基于 roneneldan/TinyStories 数据集生成
- 数据生成: 使用 Qwen3-4b 模型合成生成,由 Adam Filipek 监督
- 生成设置: 每次生成约20行,温度为0.7,使用默认的top p/top k设置
数据集特点
- 记录格式: 每条记录包含
query和answer字段,格式为[Q] Users query [A] Models answer - 最大长度: 每条记录最多256个令牌,
query比answer短很多 - 数据相似性: 部分记录可能非常相似,因为生成模型在单次运行中倾向于生成相似主题的交互
偏见、风险和限制
- 偏见: 数据集较小,每条记录最多256个令牌,适用性有限
- 风险: 可能存在少量由真实世界知识引起的偏见
- 限制: 数据集规模小,仅适用于小型研究模型
推荐用途
- 推荐用于训练微型研究模型,如 RxT-Alpha-Micro
联系方式
- 联系人: Adam Filipek
- 邮箱: adamfilipek@rxai.dev
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,交互式监督微调数据集对于模型训练至关重要。TinyStories-mini-Interaction-SFT数据集基于roneneldan/TinyStories数据集构建,专为Reactive Transformer架构的第二阶段训练概念验证而设计。该数据集通过Qwen3-4b模型批量生成,每批约20条记录,采用0.7的温度参数和默认的top p/top k设置,确保了数据的多样性和可控性。数据生成过程严格遵循交互格式,每条记录包含独立的query和answer字段,总长度不超过256个token,为模型提供了清晰的学习目标。
特点
该数据集以其简洁性和针对性著称,包含2万条训练数据和2千条验证数据,每条数据均以问答形式呈现。其显著特点在于query字段显著短于answer字段,模拟了真实对话中的信息分布。尽管数据完全由模型生成且基于虚构故事,但通过精心设计的生成策略,确保了数据在保持多样性的同时,避免了复杂的世界知识干扰,特别适合微小型研究模型的训练需求。数据采用Apache 2.0许可协议,为学术研究提供了充分的自由度。
使用方法
作为专为Reactive Transformer架构设计的训练资源,该数据集最适合RxT-Alpha-Micro等微型研究模型的监督微调。使用时需注意其交互式特性,模型应被训练为按照'[Q]用户查询[A]模型回答'的固定格式生成响应。由于数据规模有限且完全合成,建议配合数据增强技术使用,并通过多轮次训练提升模型表现。验证集可用于监控模型在独立数据上的泛化能力,但不宜将其直接应用于生产环境,而应视为架构验证的研究工具。
背景与挑战
背景概述
TinyStories-mini-Interaction-SFT数据集由Reactive AI团队开发,旨在为基于Reactive Transformer架构的实验性模型提供监督微调数据。该数据集构建于2024年,灵感来源于roneneldan/TinyStories数据集,主要用于支持具有短期记忆机制的事件驱动型反应模型的第二阶段概念验证。其核心研究问题聚焦于如何通过特定格式的交互数据([Q]用户查询[A]模型回答)来优化模型对单次交互的处理能力,而非传统语言模型中的完整对话历史处理。这一创新方法为对话系统的内存管理和响应生成机制提供了新的研究方向。
当前挑战
该数据集面临的主要挑战体现在两个方面:领域问题方面,需要解决反应式模型在有限交互长度(最大256个标记)下保持语义连贯性的难题,这对模型的上下文理解能力提出了更高要求;数据构建方面,虽然采用Qwen3-4b模型批量生成数据,但存在话题重复性偏差,同一批生成的20条数据可能呈现主题相似性。此外,合成数据可能隐含底层模型的真实世界知识残留,与预期纯粹基于虚构故事的目标产生微妙偏差。这些挑战使得数据集更适合微型研究模型验证,而非生产环境应用。
常用场景
经典使用场景
在自然语言处理领域,TinyStories-mini-Interaction-SFT数据集为研究者提供了一个理想的实验平台,用于探索反应式Transformer架构的监督微调过程。该数据集通过精心设计的问答对形式,模拟了对话交互场景,特别适合用于训练和验证那些依赖短时记忆而非完整对话历史的语言模型。其简洁的格式和有限的长度使得研究者能够专注于模型在单轮交互中的表现,为反应式模型的早期开发奠定了重要基础。
解决学术问题
该数据集有效解决了反应式Transformer架构在微调阶段面临的数据格式适配问题。传统语言模型需要处理完整的对话历史,而反应式模型则将历史信息存储在内部短时记忆中,仅对当前交互进行响应。TinyStories-mini-Interaction-SFT提供了标准化的[Q]和[A]标记格式,帮助模型学习正确的交互模式。这一创新为探索新型记忆机制的语言模型架构提供了关键支持,推动了对话系统领域的研究边界。
衍生相关工作
围绕该数据集已经产生了一系列创新性研究,最典型的是RxT-Alpha-Micro系列模型的开发工作。这些微尺度研究模型充分利用了数据集的特性,验证了反应式Transformer架构的可行性。相关研究还探索了在不同温度参数下生成多样化训练数据的方法,为合成数据在模型微调中的应用提供了新思路。这些工作共同推动了事件驱动型语言模型研究的发展。
以上内容由遇见数据集搜集并总结生成


