---
dataset_info:
features:
- name: image
dtype: image
- name: mask
dtype: image
- name: System
dtype: string
- name: Orientation
dtype: string
- name: latitude
dtype: float64
- name: longitude
dtype: float64
- name: date
dtype: string
- name: LocAcc
dtype: int64
- name: Species
dtype: string
- name: Owner
dtype: string
- name: Dataset-Name
dtype: string
- name: TVT-split1
dtype: string
- name: TVT-split2
dtype: string
- name: TVT-split3
dtype: string
- name: TVT-split4
dtype: string
- name: TVT-split5
dtype: string
splits:
- name: train
num_bytes: 1896819757.9
num_examples: 3775
download_size: 1940313757
dataset_size: 1896819757.9
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# VegAnn Dataset 😄
## Dataset Description 📖
VegAnn, short for Vegetation Annotation, is a meticulously curated collection of 3,775 multi-crop RGB images aimed at enhancing research in crop vegetation segmentation. These images span various phenological stages and were captured using diverse systems and platforms under a wide range of illumination conditions. By aggregating sub-datasets from different projects and institutions, VegAnn represents a broad spectrum of measurement conditions, crop species, and development stages.
### Languages 🌐
The annotations and documentation are primarily in English.
## Dataset Structure 🏗
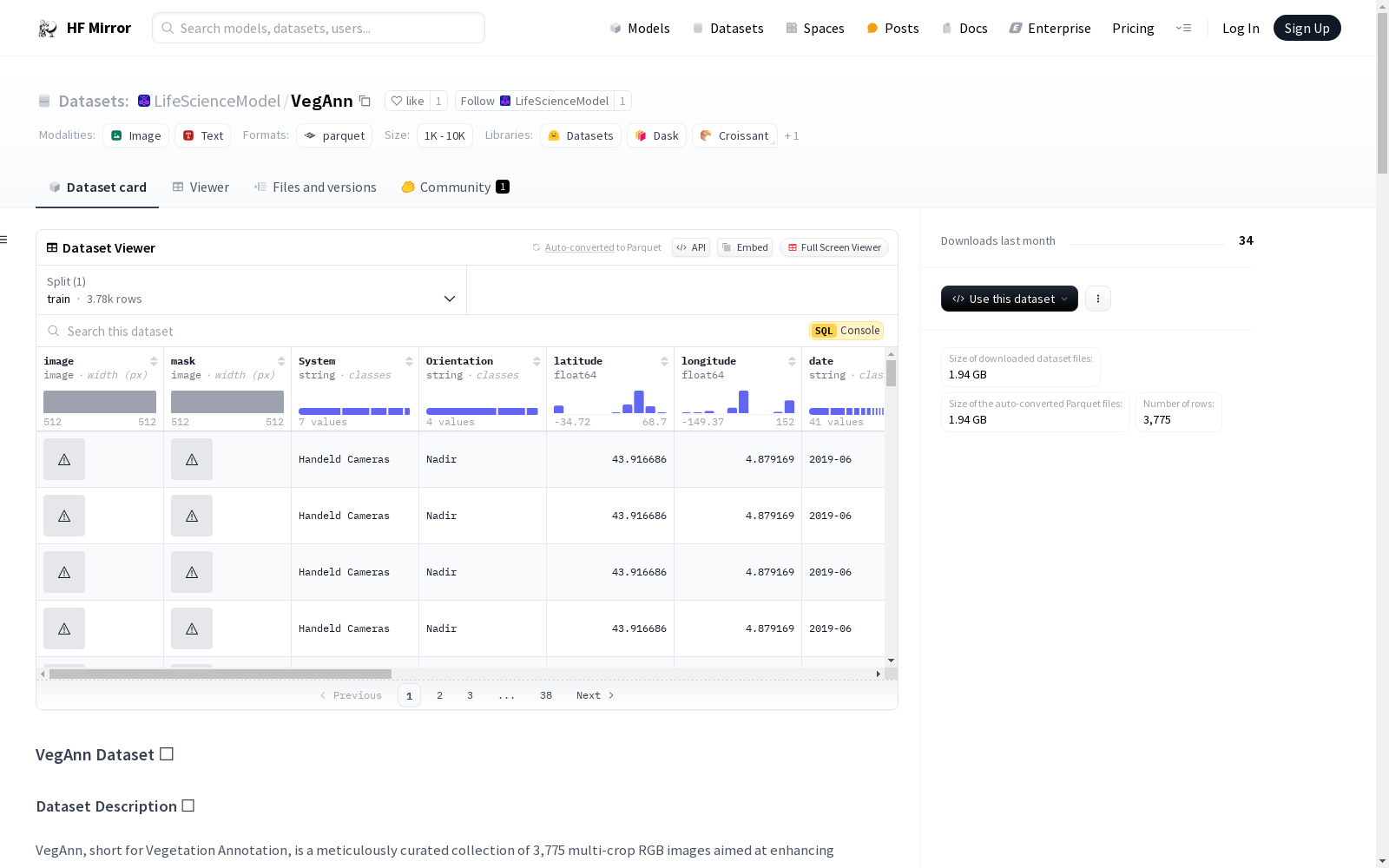
### Data Instances 📸
A VegAnn data instance consists of a 512x512 pixel RGB image patch derived from larger raw images. These patches are designed to provide sufficient detail for distinguishing between vegetation and background, crucial for applications in semantic segmentation and other forms of computer vision analysis in agricultural contexts.

### Data Fields 📋
- `Name`: Unique identifier for each image patch.
- `System`: The imaging system used to acquire the photo (e.g., Handheld Cameras, DHP, UAV).
- `Orientation`: The camera's orientation during image capture (e.g., Nadir, 45 degrees).
- `latitude` and `longitude`: Geographic coordinates where the image was taken.
- `date`: Date of image acquisition.
- `LocAcc`: Location accuracy flag (1 for high accuracy, 0 for low or uncertain accuracy).
- `Species`: The crop species featured in the image (e.g., Wheat, Maize, Soybean).
- `Owner`: The institution or entity that provided the image (e.g., Arvalis, INRAe).
- `Dataset-Name`: The sub-dataset or project from which the image originates (e.g., Phenomobile, Easypcc).
- `TVT-split1` to `TVT-split5`: Fields indicating the train/validation/test split configurations, facilitating various experimental setups.
### Data Splits 📊
The dataset is structured into multiple splits (as indicated by `TVT-split` fields) to support different training, validation, and testing scenarios in machine learning workflows.
## Dataset Creation 🛠
### Curation Rationale 🤔
The VegAnn dataset was developed to address the gap in available datasets for training convolutional neural networks (CNNs) for the task of semantic segmentation in real-world agricultural environments. By incorporating images from a wide array of conditions and stages of crop development, VegAnn aims to enhance the performance of segmentation algorithms, promote benchmarking, and foster research on large-scale crop vegetation segmentation.
### Source Data 🌱
#### Initial Data Collection and Normalization
Images within VegAnn were sourced from various sub-datasets contributed by different institutions, each under specific acquisition configurations. These were then standardized into 512x512 pixel patches to maintain consistency across the dataset.
#### Who are the source data providers?
The data was provided by a collaboration of institutions including Arvalis, INRAe, The University of Tokyo, University of Queensland, NEON, and EOLAB, among others.

### Annotations 📝
#### Annotation process
Annotations for the dataset were focused on distinguishing between vegetation and background within the images. The process ensured that the images offered sufficient spatial resolution to allow for accurate visual segmentation.
#### Who are the annotators?
The annotations were performed by a team comprising researchers and domain experts from the contributing institutions.
## Considerations for Using the Data 🤓
### Social Impact of Dataset 🌍
The VegAnn dataset is expected to significantly impact agricultural research and commercial applications by enhancing the accuracy of crop monitoring, disease detection, and yield estimation through improved vegetation segmentation techniques.
### Discussion of Biases 🧐
Given the diverse sources of the images, there may be inherent biases towards certain crop types, geographical locations, and imaging conditions. Users should consider this diversity in applications and analyses.
### Licensing Information 📄
Please refer to the specific licensing agreements of the contributing institutions or contact the dataset providers for more information on usage rights and restrictions.
## Citation Information 📚
If you use the VegAnn dataset in your research, please cite the following:
```
@article{madec_vegann_2023,
title = {{VegAnn}, {Vegetation} {Annotation} of multi-crop {RGB} images acquired under diverse conditions for segmentation},
volume = {10},
issn = {2052-4463},
url = {https://doi.org/10.1038/s41597-023-02098-y},
doi = {10.1038/s41597-023-02098-y},
abstract = {Applying deep learning to images of cropping systems provides new knowledge and insights in research and commercial applications. Semantic segmentation or pixel-wise classification, of RGB images acquired at the ground level, into vegetation and background is a critical step in the estimation of several canopy traits. Current state of the art methodologies based on convolutional neural networks (CNNs) are trained on datasets acquired under controlled or indoor environments. These models are unable to generalize to real-world images and hence need to be fine-tuned using new labelled datasets. This motivated the creation of the VegAnn - Vegetation Annotation - dataset, a collection of 3775 multi-crop RGB images acquired for different phenological stages using different systems and platforms in diverse illumination conditions. We anticipate that VegAnn will help improving segmentation algorithm performances, facilitate benchmarking and promote large-scale crop vegetation segmentation research.},
number = {1},
journal = {Scientific Data},
author = {Madec, Simon and Irfan, Kamran and Velumani, Kaaviya and Baret, Frederic and David, Etienne and Daubige, Gaetan and Samatan, Lucas Bernigaud and Serouart, Mario and Smith, Daniel and James, Chrisbin and Camacho, Fernando and Guo, Wei and De Solan, Benoit and Chapman, Scott C. and Weiss, Marie},
month = may,
year = {2023},
pages = {302},
}
```
## Additional Information
- **Dataset Curators**: Simon Madec et al.
- **Version**: 1.0
- **License**: Specified by each contributing institution
- **Contact**: TBD
数据集信息:
特征:
- 名称:image,数据类型:image(图像)
- 名称:mask,数据类型:image(图像)
- 名称:System(成像系统),数据类型:字符串
- 名称:Orientation(拍摄方位),数据类型:字符串
- 名称:latitude(纬度),数据类型:float64(64位浮点型)
- 名称:longitude(经度),数据类型:float64(64位浮点型)
- 名称:date(采集日期),数据类型:字符串
- 名称:LocAcc(位置精度标记),数据类型:int64(64位整型)
- 名称:Species(作物物种),数据类型:字符串
- 名称:Owner(数据提供方),数据类型:字符串
- 名称:Dataset-Name(子数据集名称),数据类型:字符串
- 名称:TVT-split1(训练/验证/测试拆分1),数据类型:字符串
- 名称:TVT-split2(训练/验证/测试拆分2),数据类型:字符串
- 名称:TVT-split3(训练/验证/测试拆分3),数据类型:字符串
- 名称:TVT-split4(训练/验证/测试拆分4),数据类型:字符串
- 名称:TVT-split5(训练/验证/测试拆分5),数据类型:字符串
拆分:
- 名称:train(训练集),字节数:1896819757.9,样本数:3775
下载大小:1940313757
数据集总大小:1896819757.9
配置:
- 配置名称:default(默认配置),数据文件:
- 拆分:train(训练集),路径:data/train-*
# VegAnn数据集 😄
## 数据集描述 📖
VegAnn全称为Vegetation Annotation(植被标注),是经过精心整理的3775幅多作物RGB图像集合,旨在推动作物植被分割领域的研究进展。该数据集涵盖多种物候期,使用多样化的成像系统与平台,在多样的光照条件下采集完成。通过整合来自不同项目与机构的子数据集,VegAnn覆盖了广泛的采集条件、作物物种与发育阶段。
### 语言 🌐
标注内容与文档说明主要采用英语撰写。
## 数据集结构 🏗
### 数据实例 📸
VegAnn的数据实例均源自原始大图裁剪得到的512×512像素RGB图像块。此类图像块能够提供足够的细节以区分植被与背景,对于农业场景下的语义分割(semantic segmentation)及其他计算机视觉分析应用至关重要。

### 数据字段 📋
- `"Name"`:每个图像块的唯一标识符。
- `"System"`:用于采集图像的成像系统(例如手持相机、DHP、无人机(UAV))。
- `"Orientation"`:图像采集时的相机方位(例如天底视角(Nadir)、45度角)。
- `"latitude"`(纬度)与`"longitude"`(经度):图像采集地的地理坐标。
- `"date"`:图像采集日期。
- `"LocAcc"`:位置精度标记(1代表高精度,0代表低精度或精度不确定)。
- `"Species"`:图像中的作物物种(例如小麦、玉米、大豆)。
- `"Owner"`:提供该图像的机构或实体(例如Arvalis、INRAe)。
- `"Dataset-Name"`:该图像所属的子数据集或项目(例如Phenomobile、Easypcc)。
- `"TVT-split1"`至`"TVT-split5"`:用于标识训练/验证/测试拆分配置的字段,便于开展各类实验设置。
### 数据拆分 📊
本数据集通过`"TVT-split"`字段设置了多种拆分方式,以适配机器学习流程中不同的训练、验证与测试场景。
## 数据集构建 🛠
### 整理依据 🤔
VegAnn数据集的开发旨在填补现有数据集的不足:当前针对真实农业环境语义分割任务训练卷积神经网络(CNNs)的可用数据集较为匮乏。通过整合多样采集条件与作物发育阶段的图像,VegAnn旨在提升分割算法的性能、推动基准测试工作,并促进大规模作物植被分割领域的研究。
### 源数据 🌱
#### 初始数据采集与标准化
VegAnn的图像源自不同机构贡献的多个子数据集,各子数据集均采用特定的采集配置。随后所有图像均被标准化裁剪为512×512像素的图像块,以保证数据集内的一致性。
#### 源数据提供方有哪些?
本数据集由多家机构合作提供,包括Arvalis、INRAe、东京大学、昆士兰大学、NEON以及EOLAB等。

### 标注信息 📝
#### 标注流程
本数据集的标注工作聚焦于区分图像中的植被与背景。标注流程确保图像具备足够的空间分辨率,以实现精准的视觉分割。
#### 标注人员有哪些?
标注工作由来自各贡献机构的研究人员与领域专家组成的团队完成。
## 数据使用注意事项 🤓
### 数据集的社会影响 🌍
VegAnn数据集有望通过提升植被分割技术的精度,显著推动农业研究与商业应用的发展,助力作物监测、病害检测与产量估算等任务。
### 偏差分析 🧐
由于图像来源多样,数据集可能存在针对特定作物类型、地理区域与成像条件的固有偏差。使用者在应用与分析过程中应考虑到这一多样性。
### 授权信息 📄
如需了解使用权限与限制的更多信息,请参阅各贡献机构的具体授权协议,或联系数据集提供方。
## 引用信息 📚
如果您在研究中使用VegAnn数据集,请引用以下文献:
@article{madec_vegann_2023,
title = {{VegAnn}, {Vegetation} {Annotation} of multi-crop {RGB} images acquired under diverse conditions for segmentation},
volume = {10},
issn = {2052-4463},
url = {https://doi.org/10.1038/s41597-023-02098-y},
doi = {10.1038/s41597-023-02098-y},
abstract = {Applying deep learning to images of cropping systems provides new knowledge and insights in research and commercial applications. Semantic segmentation or pixel-wise classification, of RGB images acquired at the ground level, into vegetation and background is a critical step in the estimation of several canopy traits. Current state of the art methodologies based on convolutional neural networks (CNNs) are trained on datasets acquired under controlled or indoor environments. These models are unable to generalize to real-world images and hence need to be fine-tuned using new labelled datasets. This motivated the creation of the VegAnn - Vegetation Annotation - dataset, a collection of 3775 multi-crop RGB images acquired for different phenological stages using different systems and platforms in diverse illumination conditions. We anticipate that VegAnn will help improving segmentation algorithm performances, facilitate benchmarking and promote large-scale crop vegetation segmentation research.},
number = {1},
journal = {Scientific Data},
author = {Madec, Simon and Irfan, Kamran and Velumani, Kaaviya and Baret, Frederic and David, Etienne and Daubige, Gaetan and Samatan, Lucas Bernigaud and Serouart, Mario and Smith, Daniel and James, Chrisbin and Camacho, Fernando and Guo, Wei and De Solan, Benoit and Chapman, Scott C. and Weiss, Marie},
month = may,
year = {2023},
pages = {302},
}
## 附加信息
- **数据集整理者**:Simon Madec 等
- **版本**:1.0
- **授权协议**:由各贡献机构分别指定
- **联系方式**:待定(TBD)