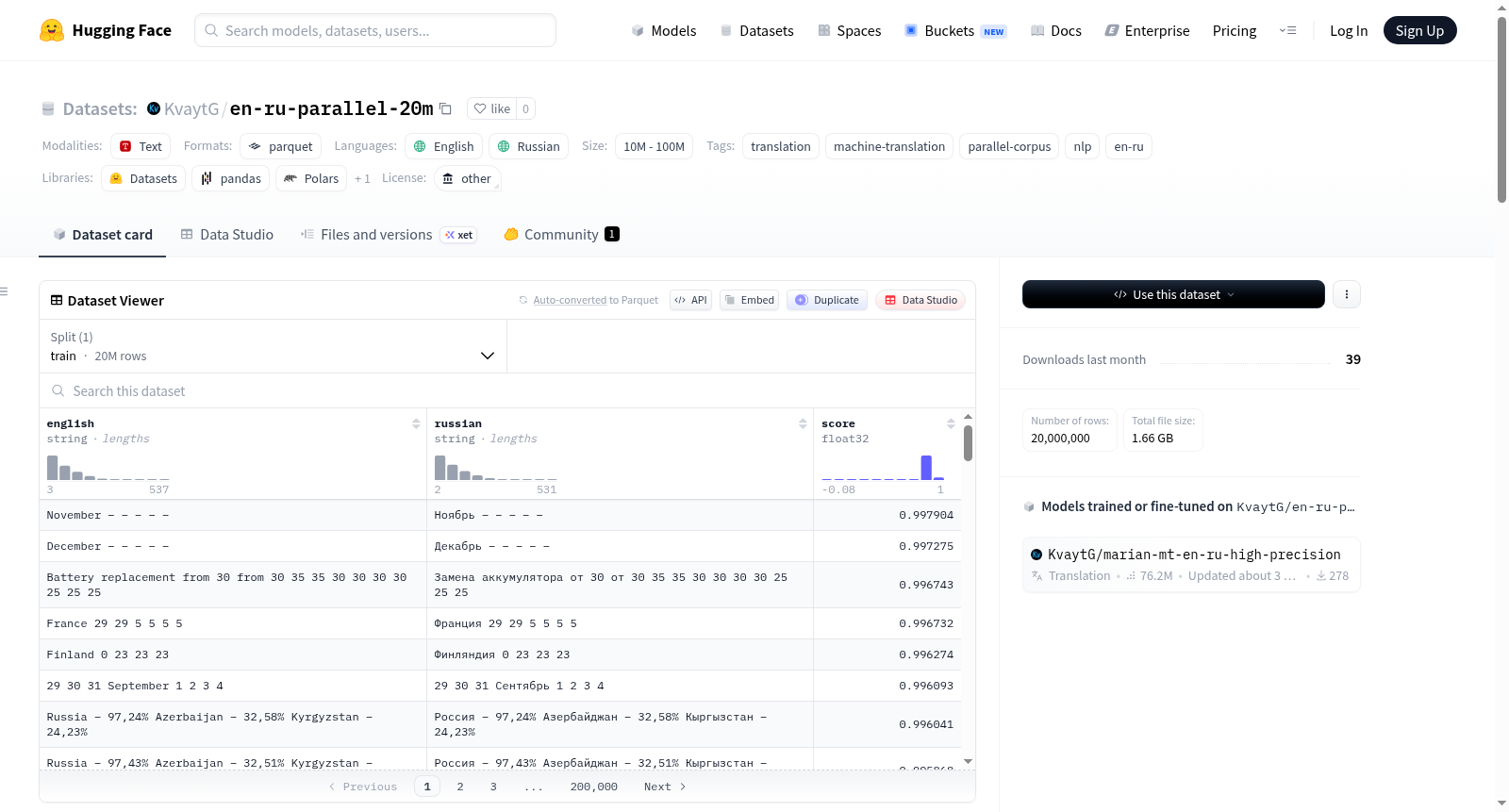
en-ru-parallel-20m
收藏en-ru-parallel-20m 数据集概述
数据集简介
该数据集包含 20,000,000 个经过仔细筛选的英语-俄语平行句对。它是专门为机器翻译、多语言嵌入训练、模型微调以及任何其他需要大规模高质量英俄平行语料库的 NLP 任务而创建的。
数据集摘要
该语料库基于 2026年3月28日 在 OPUS 上可用的 所有 英语-俄语数据集构建。
应用了多阶段清洗和排序流程:
- 使用 en-ru-corpus-utils 中的工具进行启发式过滤。
- 使用
removedup进行去重。 - 使用 LaBSE 余弦相似度进行质量排序。为了高效处理海量数据,LaBSE 嵌入通过 model2vec + PCA (pca_dims=300) 计算。仅保留了相似度得分最高的 2000 万个句对。
数据集按 LaBSE 分数降序排列(质量最高的在前)。
语言
- 英语 (
en) - 俄语 (
ru)
数据字段
| 字段名 | 类型 | 描述 |
|---|---|---|
english |
string | 英语句子 |
russian |
string | 俄语句子 |
score |
float32 | LaBSE 余弦相似度得分(越高表示对齐越好)。数据集按此列降序排序。 |
数据划分
| 划分 | 样本数量 |
|---|---|
train |
20,000,000 |
(没有预定义的验证集或测试集——用户可以自行轻松创建。)
使用方式
python from datasets import load_dataset dataset = load_dataset("KvaytG/en-ru-parallel-20m", split="train")
许可证与法律声明
该数据集是来自 OPUS 项目 的多个语料库的聚合。
因为它包含了来自 所有 可用的英俄 OPUS 源(截至 2026年3月28日)的数据,所以它是一个混合许可证的集合。基础文本保留其原始许可证,这些许可证差异很大:
- 部分数据属于公共领域或采用宽松许可证(例如,Europarl, UNPC)。
- 部分数据使用 Copyleft 许可证(例如,Wikipedia 的 CC-BY-SA)。
- 部分数据严格禁止商业用途(例如,TED/QED 的 CC-BY-NC)。
- 部分数据可能受版权保护(例如,OpenSubtitles)。
因此,此聚合数据集并未在 MIT 等单一宽松许可证下发布。 通过下载和使用此数据集,您承认:
- 本数据集的作者不拥有基础文本的版权。
- 该数据集主要供研究和教育目的使用。
- 您全权负责确保您对此数据的使用(尤其是在商业应用中)符合相应 OPUS 子语料库的原始许可证。
引用
bibtex @misc{kvaytg_en_ru_parallel_20m, author = {KvaytG}, title = {20M high-quality English-Russian parallel corpus}, year = {2026}, publisher = {Hugging Face}, journal = {Hugging Face Datasets}, url = {https://huggingface.co/datasets/KvaytG/en-ru-parallel-20m}, note = {Built from all OPUS en-ru corpora (28 Mar 2026) with heuristic cleaning, deduplication and LaBSE ranking via model2vec+PCA} }