cammt
收藏CaMMT 数据集概述
数据集基本信息
- 名称: CaMMT (Culturally Aware Multimodal Machine Translation)
- 用途: 评估多模态机器翻译系统在文化相关内容上的表现
- 数据量: 5,817个主条目 + 1,550个CSI翻译条目
- 语言: 19种语言,覆盖23个地区
- 许可证: CC BY-NC-SA 4.0
数据集特点
- 多模态: 包含图像和文本数据
- 文化相关性: 特别关注文化特定项目(CSIs)
- 翻译策略: 提供保守翻译和替代翻译
- 地区多样性: 覆盖23个不同地区
数据结构
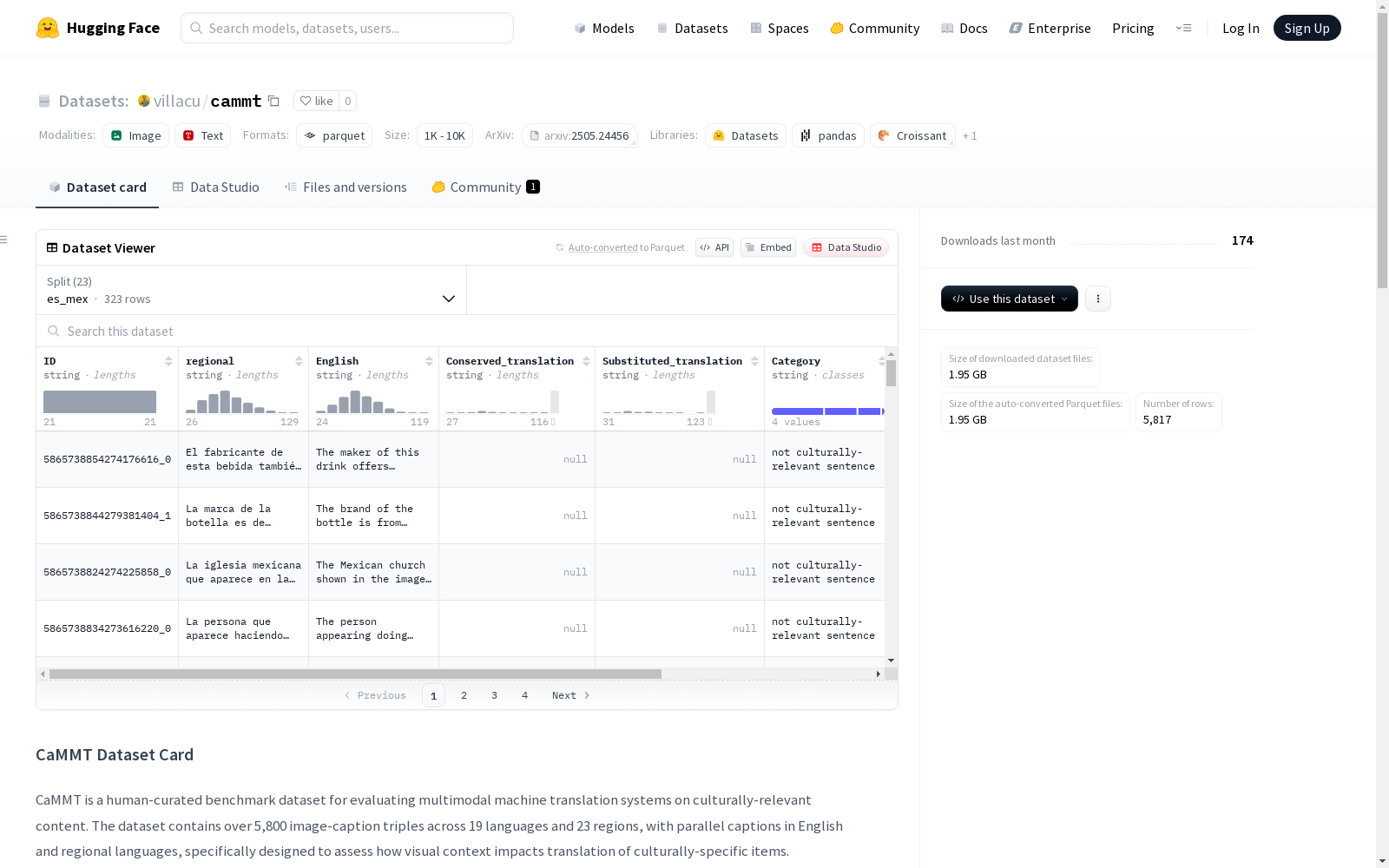
特征字段
ID: 唯一标识符regional: 地区语言文本English: 英语平行文本Conserved_translation: 保留CSI的翻译Substituted_translation: 使用熟悉等效词的翻译Category: 文化相关性分类Preferred_translation: 母语者偏好的翻译image: 图像数据
数据分类
- 非文化相关句子
- 非CSI(文化相关但无特定CSI)
- CSI-有可译性
- CSI-强制翻译
数据分布
| 地区 | 样本数 | 数据大小(bytes) |
|---|---|---|
| es_mex | 323 | 158368543.0 |
| bn_india | 286 | 94017886.0 |
| om_eth | 214 | 28490930.0 |
| ur_india | 220 | 102386298.0 |
| ig_nga | 200 | 14372042.0 |
| ur_pak | 216 | 147129846.0 |
| zh_ch | 308 | 91877910.0 |
| es_ecu | 362 | 141969979.0 |
| sw_ken | 271 | 31567516.0 |
| kor_sk | 290 | 143897056.0 |
| ru_rus | 200 | 56598710.0 |
| ta_india | 213 | 142254878.0 |
| amh_eth | 234 | 122937506.0 |
| jp_jap | 203 | 63884062.0 |
| fil_phl | 203 | 42171387.0 |
| ms_mys | 315 | 84408174.0 |
| bg_bg | 369 | 179103702.0 |
| es_chl | 234 | 98202963.0 |
| pt_brz | 284 | 214095076.0 |
| ar_egy | 203 | 106134417.0 |
| ind_ind | 202 | 116476184.0 |
| mr_india | 202 | 145040535.0 |
| es_arg | 265 | 142144959.0 |
引用信息
bibtex @misc{villacueva2025cammtbenchmarkingculturallyaware, title={CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation}, author={Emilio Villa-Cueva and Sholpan Bolatzhanova and Diana Turmakhan and Kareem Elzeky and Henok Biadglign Ademtew and Alham Fikri Aji and Israel Abebe Azime and Jinheon Baek and Frederico Belcavello and Fermin Cristobal and Jan Christian Blaise Cruz and Mary Dabre and Raj Dabre and Toqeer Ehsan and Naome A Etori and Fauzan Farooqui and Jiahui Geng and Guido Ivetta and Thanmay Jayakumar and Soyeong Jeong and Zheng Wei Lim and Aishik Mandal and Sofia Martinelli and Mihail Minkov Mihaylov and Daniil Orel and Aniket Pramanick and Sukannya Purkayastha and Israfel Salazar and Haiyue Song and Tiago Timponi Torrent and Debela Desalegn Yadeta and Injy Hamed and Atnafu Lambebo Tonja and Thamar Solorio}, year={2025}, eprint={2505.24456}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2505.24456}, }