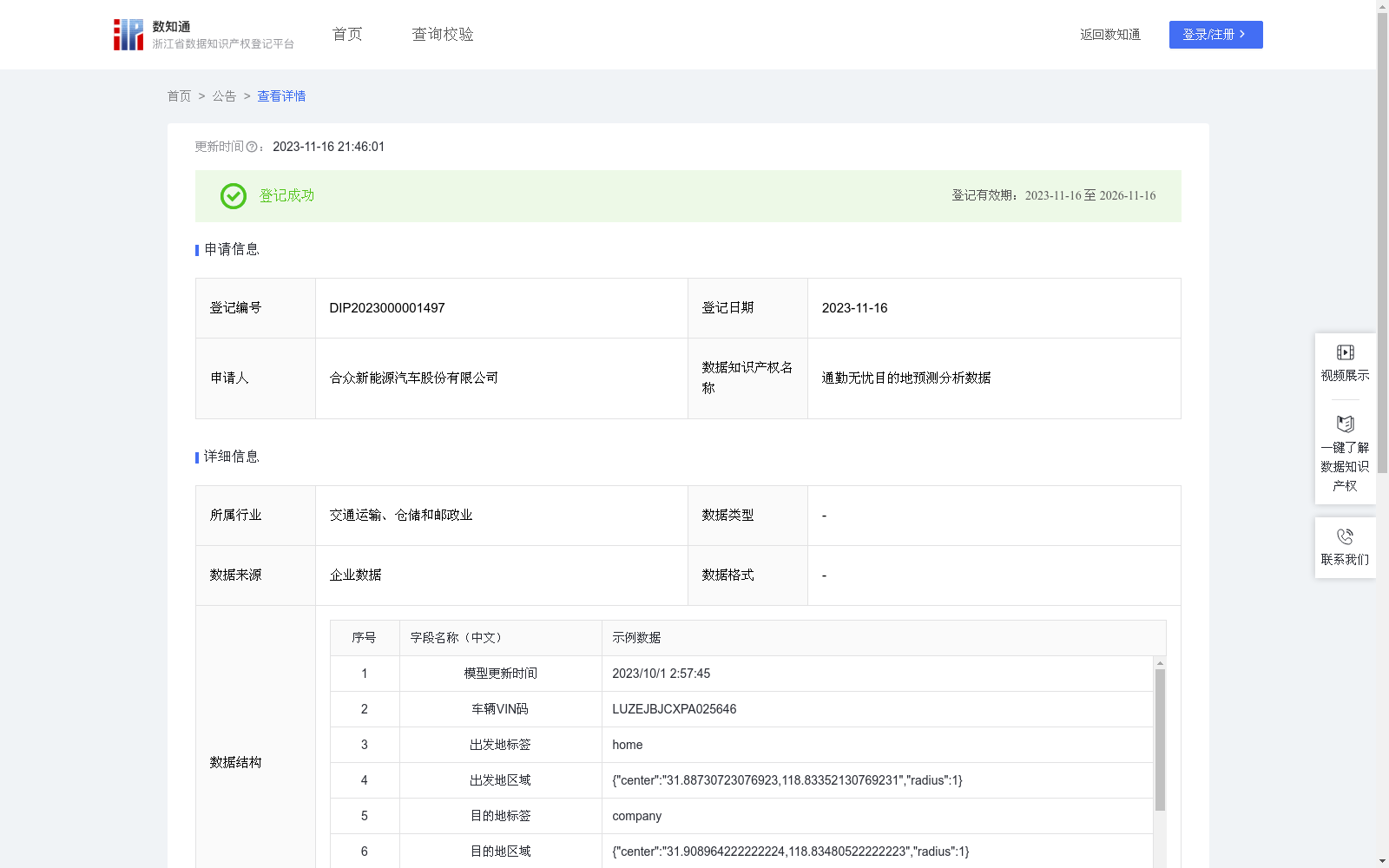
通勤无忧目的地预测分析数据
收藏浙江省数据知识产权登记平台2023-11-16 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/11357
下载链接
链接失效反馈官方服务:
资源简介:
基于导航埋点数据,在后台通过云端大数据算法模型,预测用户的家和公司位置,并自动规划行驶路线;基于这个功能,可开发出熟路模式等,一系列智能便捷服务,提升用户体验。1.数据采集: 采集TBOX上传的信号数据,车辆状态、经度、纬度等字段。通过车辆启动、熄火状态划分车辆行程段。存储每辆车每段行程的起点和终点的经度和纬度。2.数据清洗:过滤掉经度或纬度异常或缺失的数据。3.数据处理: 将经、纬度数据转为弧度制,算出任意两点间的球面距离。4.初次聚类:将数据进行DBSCAN聚类,使用网格调参法调整扫描半径eps和最小样本数min_samples,计算不同参数下的模型的轮廓系数。5.评估初步结果: 最大的轮廓系数是否满意? 是则记录结果转到步骤9,如果不是转到步骤6。6.数据筛选: 只保留每辆车每天的第一次行程的起始点和最后一次行程的结束点的经、纬度。7.再次聚类: 再次计算不同参数下的模型的轮廓系数。8.评估筛选后的结果: 对最大的轮廓系数是否满意? 是则记录结果,不是则考虑使用其他策略或参数调整。9.结果验证: 计算聚类结果中占比最大的簇的中心点经度和纬度为预测位置,比较预测位置与真实的常居地址,计算预测位置与真实位置的距离。10.实施决策: 预测位置与真实位置的距离是否在可接受范围内? 是则将此方法整合到导航应用中,如果不是,考虑其他策略或返回步骤。
Based on navigation embedded tracking data, user's home and company locations can be predicted via cloud-based big data algorithm models in the backend, and driving routes can be automatically planned. Based on this function, a series of intelligent and convenient services such as the familiar route mode can be developed to enhance user experience.
1. Data Collection: Collect signal data uploaded by TBOX, including fields such as vehicle status, longitude and latitude. Divide vehicle trip segments based on the vehicle's ignition-on and ignition-off states. Store the longitude and latitude of the start and end points of each trip for every vehicle.
2. Data Cleaning: Filter out data with abnormal or missing longitude or latitude values.
3. Data Processing: Convert longitude and latitude data to radians, and calculate the spherical distance between any two points.
4. Initial Clustering: Perform DBSCAN clustering on the dataset, use the grid search parameter tuning method to adjust the scanning radius eps and the minimum number of samples min_samples, and calculate the silhouette coefficient of the model under different parameter combinations.
5. Preliminary Result Evaluation: Check whether the maximum silhouette coefficient is satisfactory. If yes, record the result and proceed to Step 9; if not, proceed to Step 6.
6. Data Screening: Only retain the longitude and latitude of the starting point of the first trip and the ending point of the last trip for each vehicle per day.
7. Secondary Clustering: Recalculate the silhouette coefficient of the model under different parameter combinations.
8. Screened Result Evaluation: Check whether the maximum silhouette coefficient is satisfactory. If yes, record the result; if not, consider adopting other strategies or adjusting parameters.
9. Result Validation: Take the longitude and latitude of the cluster center with the largest proportion in the clustering results as the predicted location, compare the predicted location with the user's real regular residence address, and calculate the distance between the predicted and real locations.
10. Implementation Decision: Check whether the distance between the predicted location and the real location is within an acceptable range. If yes, integrate this method into the navigation application; if not, consider other strategies or return to the previous steps.
提供机构:
合众新能源汽车股份有限公司
创建时间:
2023-10-10
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


