kNN-Targets-wikipedia-mistral
收藏Hugging Face2025-10-22 更新2025-10-22 收录
下载链接:
https://huggingface.co/datasets/Rubin-Wei/kNN-Targets-wikipedia-mistral
下载链接
链接失效反馈官方服务:
资源简介:
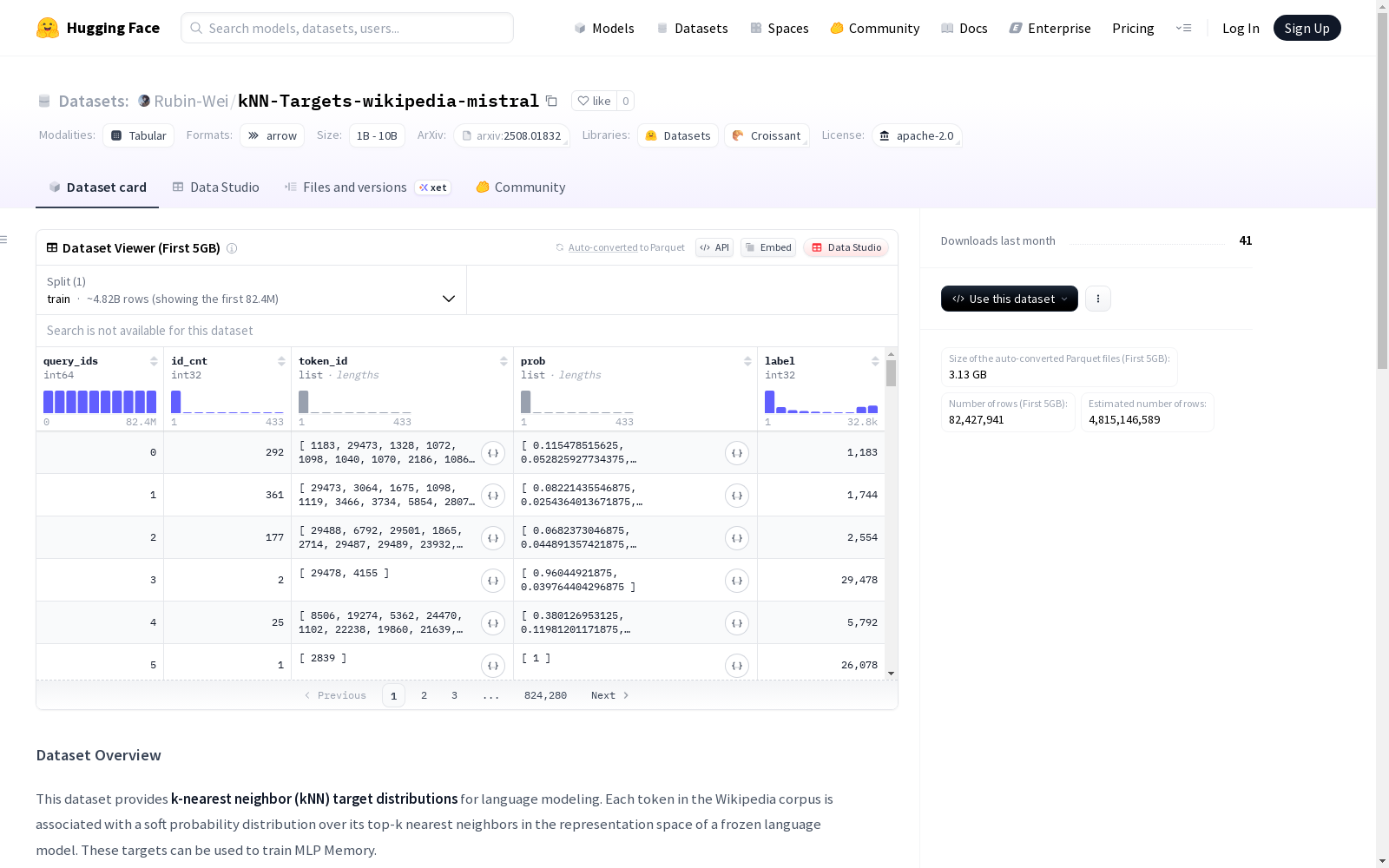
该数据集为语言建模提供了k-近邻(kNN)目标分布。Wikipedia语料库中的每个标记都与冻结语言模型表示空间中其top-k最近邻的软概率分布相关联。这些目标可以用来训练MLP Memory。数据集包含五个字段:查询标记的唯一标识符、kNN分布中的标记数、与top-k邻居标记对应的词汇索引数组、每个标记的概率数组以及kNN分布旨在预测或增强的地面真实标记ID。
创建时间:
2025-10-19
原始信息汇总
数据集概述
基本信息
- 数据集名称: kNN-Targets-wikipedia-mistral
- 许可证: Apache-2.0
- 功能: 提供语言建模的k近邻目标分布
核心内容
- 每个Wikipedia语料库中的标记都与其在冻结语言模型表示空间中的top-k最近邻的软概率分布相关联
- 这些目标可用于训练MLP Memory
关联资源
- 对应预处理语料库: Rubin-Wei/enwiki-dec2021-preprocessed-mistral
- 兼容模型: Mistral-7B-v0.3
- 相关论文: MLP Memory: A Retriever-Pretrained Memory for Large Language Models
- GitHub仓库: https://github.com/Rubin-Wei/MLPMemory
生成流程
- 数据存储构建: 使用冻结语言模型从训练分割中提取隐藏状态和目标标记
- FAISS索引构建: 在数据存储上构建压缩的IVF-PQ索引以实现高效的kNN搜索
- kNN目标保存: 为每个标记检索其top-1024邻居并计算温度缩放的softmax分布
数据模式
数据集包含以下五列:
- query_ids: 每个查询标记的全局唯一且顺序排序的标识符,范围从0到4,829,843,071
- id_cnt: kNN分布中的标记数量
- token_id: 对应top-k邻居标记的词汇索引数组
- prob: 与每个token_id相关联的概率数组
- label: kNN分布旨在预测或增强的真实标记ID
引用信息
bibtex @inproceedings{Wei2025MLPMA, title={MLP Memory: A Retriever-Pretrained Memory for Large Language Models}, author={Rubin Wei and Jiaqi Cao and Jiarui Wang and Jushi Kai and Qipeng Guo and Bowen Zhou and Zhouhan Lin}, year={2025}, url={https://api.semanticscholar.org/CorpusID:281658735} }
联系方式
- 邮箱: weirubinn@gmail.com
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,构建高质量的辅助数据集对提升语言模型性能至关重要。本数据集通过三阶段流程生成:首先从冻结的Mistral-7B-v0.3模型中提取Wikipedia语料的隐藏状态和目标词元构建数据存储库;随后采用压缩的IVF-PQ索引技术建立高效k近邻检索系统;最终为每个词元计算其与1024个最近邻的温度缩放softmax概率分布,形成完整的k近邻目标分布体系。
特点
该数据集的核心价值体现在其独特的概率分布特性上。每个词元都关联着在表示空间中最邻近词汇的软概率分布,这种设计能有效捕捉语言模型潜在空间中的语义关联。数据集包含超48亿个有序查询标识,并完整保留原始词汇索引与概率数组的对应关系,为MLP Memory等模块的训练提供了精确的监督信号。
使用方法
研究人员可将本数据集与预处理后的Wikipedia语料配合使用,通过加载查询标识符与概率分布数组,直接应用于语言模型的记忆增强模块训练。具体实施时需参照原始论文提出的架构,将k近邻目标分布作为辅助训练信号集成到模型优化过程中,从而实现参数化记忆能力的有效提升。
背景与挑战
背景概述
随着大规模语言模型在自然语言处理领域的广泛应用,如何有效增强模型的知识记忆与推理能力成为关键研究方向。kNN-Targets-wikipedia-mistral数据集由Rubin Wei等研究者于2025年提出,旨在通过构建基于k近邻的软目标分布,为语言建模任务提供增强型训练目标。该数据集基于Mistral-7B-v0.3模型的隐空间表示,对Wikipedia语料中的每个词汇单元计算其在表示空间中的概率分布,其核心创新在于将检索机制与生成模型预训练相结合,为MLP Memory等新型架构提供数据支撑,推动了参数化记忆与检索增强技术的融合发展。
当前挑战
在语言建模领域,传统自回归模型面临长尾知识记忆不足与泛化能力有限的根本性挑战。本数据集通过构建kNN目标分布,致力于解决模型在开放域知识推理中的表征一致性问题。数据构建过程中需克服大规模隐状态索引的技术瓶颈:首先需在数十亿级词汇单元上建立高维向量的压缩索引,同时保证近邻检索的精度与效率平衡;其次在概率分布计算中需设计合理的温度缩放机制,以协调近邻相似度与原始词汇分布的语义关联性,这对计算资源分配和算法稳定性提出了双重考验。
常用场景
经典使用场景
在自然语言处理领域,kNN-Targets-wikipedia-mistral数据集为语言模型训练提供了创新的监督信号。该数据集通过计算每个词汇在表示空间中的k近邻分布,构建了基于检索的软标签目标。这一方法特别适用于训练多层感知机记忆模块,使模型能够动态参考外部知识库,从而增强对罕见词汇和复杂语义关系的建模能力。
解决学术问题
该数据集有效解决了语言模型中知识固化与泛化能力不足的学术难题。通过引入基于检索的k近邻目标分布,模型能够突破参数化知识的限制,实现对海量非参数化知识的灵活调用。这种机制显著提升了模型在处理长尾分布词汇和动态更新知识时的适应性,为构建更智能、更健壮的语言理解系统提供了理论支撑。
衍生相关工作
基于该数据集衍生的经典工作主要集中在增强型语言模型架构创新。MLP Memory框架通过预训练检索机制与语言模型的深度融合,催生了新一代非参数化记忆增强模型。相关研究进一步拓展了检索增强生成技术的边界,推动了知识检索与神经生成模型的协同进化,为后续动态知识库集成和持续学习系统的开发奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


