SWE-bench-extra
收藏Hugging Face2024-12-20 更新2024-12-21 收录
下载链接:
https://huggingface.co/datasets/nebius/SWE-bench-extra
下载链接
链接失效反馈官方服务:
资源简介:
SWE-bench Extra 数据集是一个用于训练或评估专门解决 GitHub 问题的代理系统的数据集。它基于构建 SWE-bench 基准的方法,包含来自 1,988 个 Python 仓库的 6,415 个问题-拉取请求对。数据收集过程包括收集问题并将其与成功解决问题的拉取请求链接,基于属性进行过滤,以及基于执行的验证。该数据集支持软件工程代理的开发,并包含额外的 `meta` 字段用于验证信息。数据集根据 CC-BY-4.0 许可证授权,同时提供了每个仓库的具体许可证。
The SWE-bench Extra dataset is a dataset for training or evaluating agent systems specialized in solving GitHub issues. Built upon the methodology used to construct the SWE-bench benchmark, it contains 6,415 issue-pull request pairs sourced from 1,988 Python repositories. The data collection process entails collecting issues, linking them to pull requests that successfully resolved the corresponding issues, filtering based on predefined attributes, and performing execution-based validation. This dataset supports the development of software engineering agents, and includes an additional `meta` field for validation-related information. The dataset is licensed under CC-BY-4.0, with specific license details provided for each individual repository.
创建时间:
2024-12-09
原始信息汇总
数据集概述
SWE-bench Extra 是一个用于训练或评估专注于解决 GitHub 问题的代理系统的数据集。该数据集基于构建 SWE-bench 基准的方法,包含从 1,988 个 Python 仓库中提取的 6,415 个 Issue-Pull Request 对。
数据集描述
SWE-bench Extra 数据集支持开发能够自主解决 GitHub 问题的软件工程代理。数据收集过程基于 SWE-bench 方法,包括以下步骤:
- Issue 和 Pull Request 收集:收集问题并将其与成功解决问题的 Pull Request 关联。
- 过滤:根据问题描述、相关代码路径和测试补丁等属性过滤实例。
- 基于执行的验证:设置项目环境并运行测试以验证其正确执行。
数据集结构
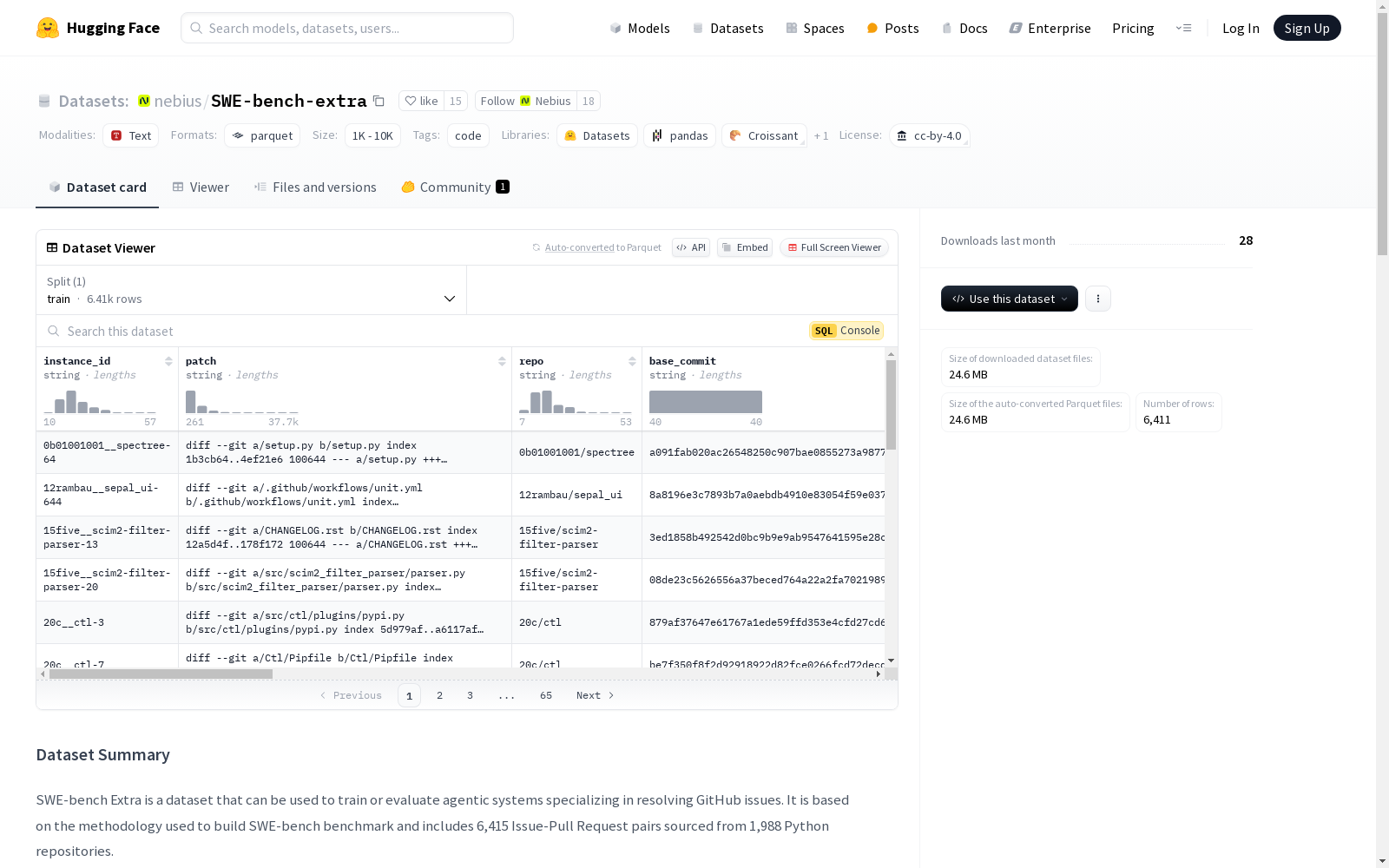
数据集包含以下字段:
instance_id:格式化的实例标识符,通常为repo_owner__repo_name-PR-number。patch:由 PR 生成的黄金补丁(减去与测试相关的代码),解决了问题。repo:GitHub 仓库的所有者/名称标识符。base_commit:表示解决方案 PR 应用之前仓库 HEAD 的提交哈希。hints_text:在解决方案 PR 的第一个提交创建日期之前在问题上发表的评论。created_at:Pull Request 的创建日期。test_patch:解决方案 PR 贡献的测试文件补丁。problem_statement:问题标题和正文。version:用于运行评估的安装版本。environment_setup_commit:用于环境设置和安装的提交哈希。FAIL_TO_PASS:表示由 PR 解决并与问题解决相关的测试集的 JSON 字符串列表。PASS_TO_PASS:表示在 PR 应用前后应通过的测试的 JSON 字符串列表。meta:一个 JSON 字典,指示实例是否为 lite,如果不是,则列出失败的 lite 验证器。license:仓库的许可证类型。
数据集统计
数据集的平均值、75 百分位数和最大值描述了收集实例的各种属性。统计数据未按仓库分组进行微平均。
| 数据 | 类型 | 平均值 | 75 百分位数 | 最大值 |
|---|---|---|---|---|
| Issue 文本 | 长度(单词) | 111.5 | 146 | 1,294 |
| 代码库 | 文件(非测试) | 71.71 | 72.00 | 2,264 |
| 行数(非测试) | 15,163.38 | 13,777 | 1,039,288 | |
| 黄金补丁 | 编辑的文件 | 2.6 | 3 | 7 |
| 编辑的行数 | 56 | 76 | 300 | |
| 测试 | 失败到通过 | 10.94 | 5 | 4,941 |
| 总数 | 58.5 | 49 | 7,820 |
许可证
数据集根据 Creative Commons Attribution 4.0 许可证授权。请尊重每个特定仓库的许可证,每个实例都提供了仓库在提交时的许可证。
搜集汇总
数据集介绍
构建方式
SWE-bench-extra数据集的构建基于SWE-bench基准方法,旨在支持软件工程代理的开发,能够自主解决GitHub问题。其构建过程包括三个主要步骤:首先,收集并关联能够成功解决问题的Issue和Pull Request;其次,基于Issue描述、相关代码路径和测试补丁等属性进行筛选;最后,通过设置项目环境并运行测试,进行基于执行的验证。
特点
SWE-bench-extra数据集的特点在于其专注于GitHub问题的解决,包含6,415个Issue-Pull Request对,来源于1,988个Python仓库。数据集不仅提供了问题描述和解决方案的补丁,还包含了测试补丁、环境设置信息以及执行验证结果,确保了数据的高质量和实用性。此外,数据集还引入了‘meta’字段,用于指示实例是否符合‘lite’标准,并列出未通过验证的规则。
使用方法
使用SWE-bench-extra数据集时,用户可以通过HuggingFace的`datasets`库进行加载,具体代码为`from datasets import load_dataset; ds = load_dataset('nebius/SWE-bench-extra')`。数据集提供了详细的字段信息,包括问题描述、解决方案补丁、测试补丁等,用户可以根据需求选择合适的字段进行分析或模型训练。此外,数据集还提供了依赖安装的默认配方,确保用户能够顺利执行实例。
背景与挑战
背景概述
SWE-bench-extra数据集是由Nebius团队基于SWE-bench基准构建的,旨在支持软件工程代理系统的发展。该数据集包含了6,415个GitHub Issue与Pull Request配对,来源于1,988个Python仓库。其核心研究问题是如何通过自动化手段解决GitHub上的软件问题,从而提升软件开发效率。该数据集的构建方法包括问题与Pull Request的收集、基于属性的过滤以及基于执行的验证,确保数据的高质量和实用性。SWE-bench-extra不仅为研究者提供了一个评估和训练软件工程代理的平台,还通过生成80,036条轨迹数据集,进一步推动了相关领域的研究进展。
当前挑战
SWE-bench-extra数据集在构建过程中面临多项挑战。首先,如何从海量的GitHub仓库中筛选出高质量的Issue与Pull Request配对,确保数据的相关性和有效性,是一个复杂的问题。其次,执行基于代码的验证过程需要确保项目环境的正确设置和测试的顺利运行,这对数据集的自动化处理能力提出了高要求。此外,数据集的多样性和覆盖范围也是一个挑战,如何在不同类型的软件项目中保持数据的一致性和代表性,是构建过程中需要解决的关键问题。最后,数据集的隐私和许可问题也需要谨慎处理,确保每个实例的许可信息得到尊重,避免法律风险。
常用场景
经典使用场景
SWE-bench-extra数据集的经典使用场景主要集中在训练和评估能够自主解决GitHub问题的软件工程代理系统。该数据集通过提供大量的Issue-Pull Request对,帮助模型学习如何从问题描述中提取关键信息,并生成有效的代码补丁来解决问题。这种场景特别适用于开发自动化工具,以提高软件开发效率和质量。
衍生相关工作
基于SWE-bench-extra数据集,研究者们开发了一系列相关的经典工作。例如,通过该数据集生成的轨迹数据集`nebius/swe-agent-trajectories`,进一步训练了动作生成模型,显著提升了模型在解决软件工程问题上的表现。此外,结合批评模型进行引导搜索,进一步提高了模型的性能,达到了当前使用开放权重模型的代理系统的最先进水平。
数据集最近研究
最新研究方向
在软件工程领域,SWE-bench-extra数据集的最新研究方向主要集中在开发能够自主解决GitHub问题的智能代理系统。该数据集通过收集和筛选GitHub上的Issue-Pull Request对,支持了自动化软件工程代理的训练与评估。近期研究中,学者们利用该数据集生成了大规模的轨迹数据,并训练了动作生成模型,显著提升了模型在解决复杂软件工程问题上的表现。此外,结合批评模型进行引导搜索的方法,进一步推动了该领域的技术前沿,展示了在开源模型中实现高效软件工程代理的潜力。这些研究不仅为自动化软件开发提供了新的工具,也为未来智能代理在软件工程中的广泛应用奠定了基础。
以上内容由遇见数据集搜集并总结生成


