behavior1k-task0029
收藏Hugging Face2025-11-15 更新2025-11-16 收录
下载链接:
https://huggingface.co/datasets/fracapuano/behavior1k-task0029
下载链接
链接失效反馈官方服务:
资源简介:
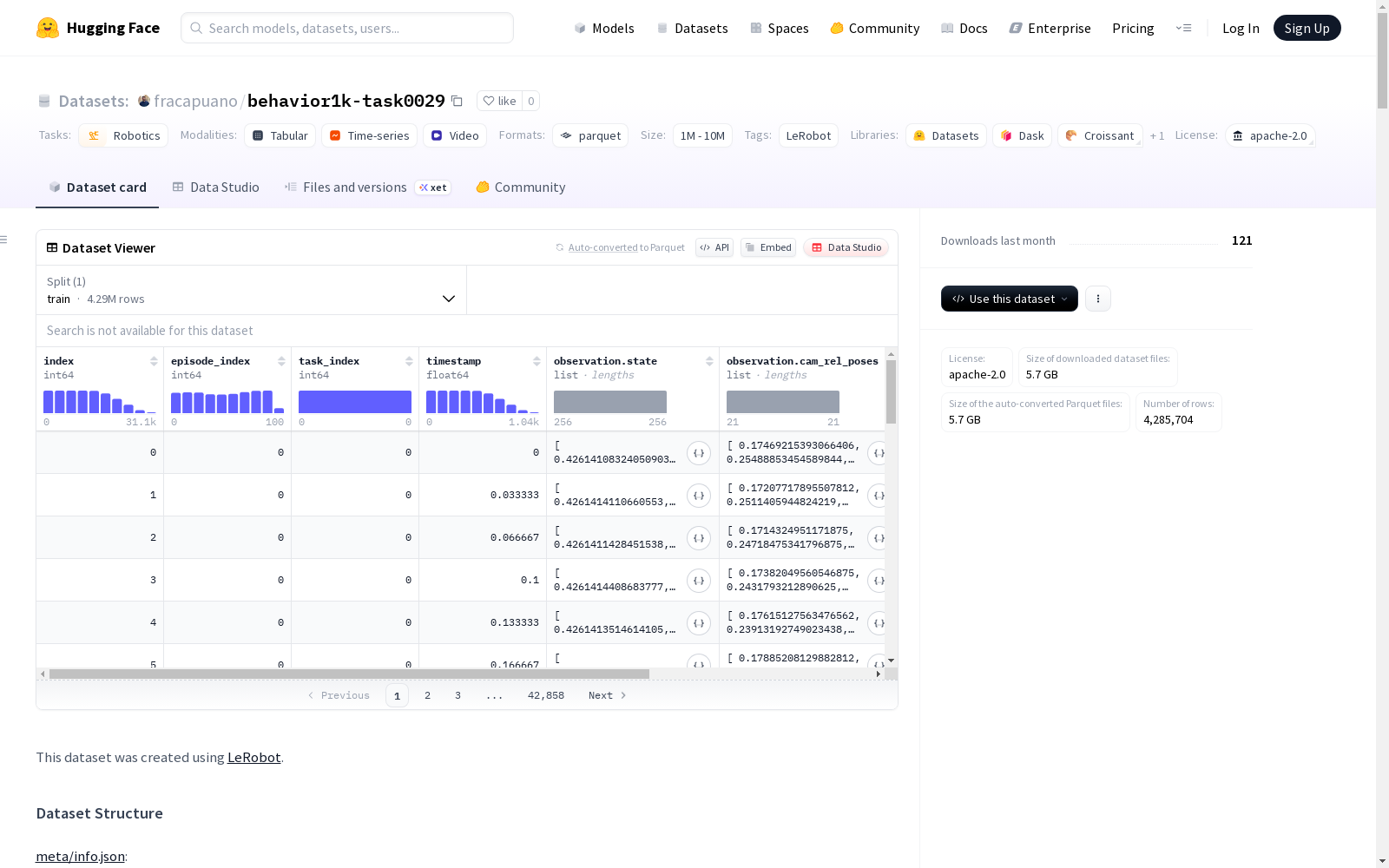
这是一个关于机器人(R1Pro)的视觉数据集,包含200个剧集,总共有4,285,704帧。数据集分为训练集,并包含RGB图像、深度图像、分割掩模以及相关的动作和状态信息。所有视频的帧率为30fps,数据以Parquet和JSON格式存储。
创建时间:
2025-11-11
原始信息汇总
数据集概述
基本信息
- 数据集名称: behavior1k-task0029
- 许可证: Apache-2.0
- 任务类别: 机器人学
- 创建工具: LeRobot
- 代码库版本: v3.0
数据集规模
- 总任务数: 1
- 总片段数: 200
- 总帧数: 4,285,704
- 总视频数: 1,800
- 数据文件大小: 100 MB
- 视频文件大小: 500 MB
数据采集信息
- 机器人类型: R1Pro
- 帧率: 30 FPS
- 分块大小: 10,000
- 数据分割:
- 训练集: 0:10000
数据结构
数据文件路径
- 数据文件: data/chunk-{chunk_index:03d}/file-{file_index:03d}.parquet
- 视频文件: videos/{video_key}/chunk-{chunk_index:03d}/file-{file_index:03d}.mp4
- 元信息文件: meta/episodes/task-{episode_chunk:04d}/episode_{episode_index:08d}.json
- 标注文件: annotations/task-{episode_chunk:04d}/episode_{episode_index:08d}.json
特征配置
图像观测数据
RGB图像:
- 左腕摄像头: 480×480×3
- 右腕摄像头: 480×480×3
- 头部摄像头: 720×720×3
深度图像:
- 左腕深度: 480×480×3
- 右腕深度: 480×480×3
- 头部深度: 720×720×3
实例分割图像:
- 左腕实例分割: 480×480×3
- 右腕实例分割: 480×480×3
- 头部实例分割: 720×720×3
其他特征
- 动作: float32[23]
- 时间戳: float32[1]
- 片段索引: int64[1]
- 帧索引: int64[1]
- 任务索引: int64[1]
- 相机相对位姿: float32[21]
- 状态观测: float32[256]
视频编码信息
- 视频编码器: libx265
- 像素格式: yuv420p(RGB图像)/ yuv420p16le(深度图像)
- 音频: 无
- 深度图标识: 深度图像标记为深度图
搜集汇总
数据集介绍
构建方式
在机器人技术领域,数据采集的精确性与系统性至关重要。behavior1k-task0029数据集通过R1Pro型机器人平台,以30帧每秒的采样频率记录了200个完整任务片段,累计生成4285704帧数据。数据以分块形式存储于Parquet文件中,每块包含10000帧,同时配套保存了多视角视频流与结构化元数据,确保数据采集过程的完整性与可追溯性。
特点
该数据集在机器人感知研究领域展现出显著的多模态特性。其核心价值在于同步采集了左腕、右腕及头部三个视角的RGB图像与深度信息,分辨率分别达到480×480与720×720像素。特别值得关注的是包含实例分割标识的视觉数据,结合23维动作向量、256维状态观测及相机位姿等结构化特征,为模仿学习与行为克隆研究提供了丰富的多源信息。
使用方法
针对机器人行为学习的研究需求,该数据集采用分块索引的访问机制。研究者可通过解析meta/info.json中的路径模板,按chunk索引与file索引定位具体数据文件。训练集划分明确指向前10000个数据块,配合独立的视频流文件与标注信息,支持端到端的行为建模、感知融合算法验证等多类研究场景。
背景与挑战
背景概述
在机器人技术迅猛发展的背景下,behavior1k-task0029数据集作为LeRobot项目的重要组成部分,专注于机器人行为学习领域。该数据集由HuggingFace团队基于R1Pro机器人平台构建,通过多视角视觉传感器与动作控制数据的同步采集,为机器人模仿学习与策略优化提供了丰富样本。其核心研究目标在于解决复杂环境中机器人动作序列的生成与泛化问题,通过包含428万帧高分辨率视频与23维动作向量的结构化数据,显著推动了机器人感知-行动闭环系统的研究进程。
当前挑战
该数据集面临的核心挑战在于机器人动作序列的时空对齐与多模态数据融合。具体而言,需解决来自头戴式与腕部传感器的异构视觉数据(包括RGB、深度及实例分割信息)与23维连续动作空间的精确映射问题。在构建过程中,面临多摄像头同步校准、大规模视频数据压缩存储(约500GB)以及动作标注时序一致性维护等技术难点,这些因素共同构成了数据集质量保障的关键瓶颈。
常用场景
经典使用场景
在机器人学习领域,behavior1k-task0029数据集通过多视角视觉数据与动作序列的精确对齐,为模仿学习算法提供了丰富的训练素材。其包含的头部及腕部RGB图像、深度信息与实例分割数据,能够有效支撑机器人从人类演示中提取操作策略的研究。该数据集以30Hz高频采样保证了动作连贯性,常被用于构建端到端的视觉运动映射模型。
衍生相关工作
以该数据集为基础衍生了多项视觉运动编码研究,包括基于时空注意力机制的行为克隆框架、多传感器融合的强化学习策略等。相关工作通过解耦视觉特征与动作语义,发展了跨场景的泛化操作模型,为后续大规模行为数据集构建提供了标准化范式参考。
数据集最近研究
最新研究方向
在机器人学习领域,behavior1k-task0029数据集凭借其多模态感知数据与高维动作空间的特性,正推动模仿学习与强化学习的深度融合。当前研究聚焦于利用该数据集的多视角视觉信息(包括头部与腕部RGB、深度及实例分割图像)构建具身智能系统的感知-行动闭环,探索跨模态表征学习在复杂任务中的泛化能力。随着LeRobot开源生态的发展,该数据集已成为机器人行为克隆与策略迁移研究的重要基准,为家庭服务机器人自主操作技能的规模化学习提供了关键数据支撑。
以上内容由遇见数据集搜集并总结生成


