real-v-tsfm
收藏Hugging Face2025-08-28 更新2025-08-29 收录
下载链接:
https://huggingface.co/datasets/Volavion/real-v-tsfm
下载链接
链接失效反馈官方服务:
资源简介:
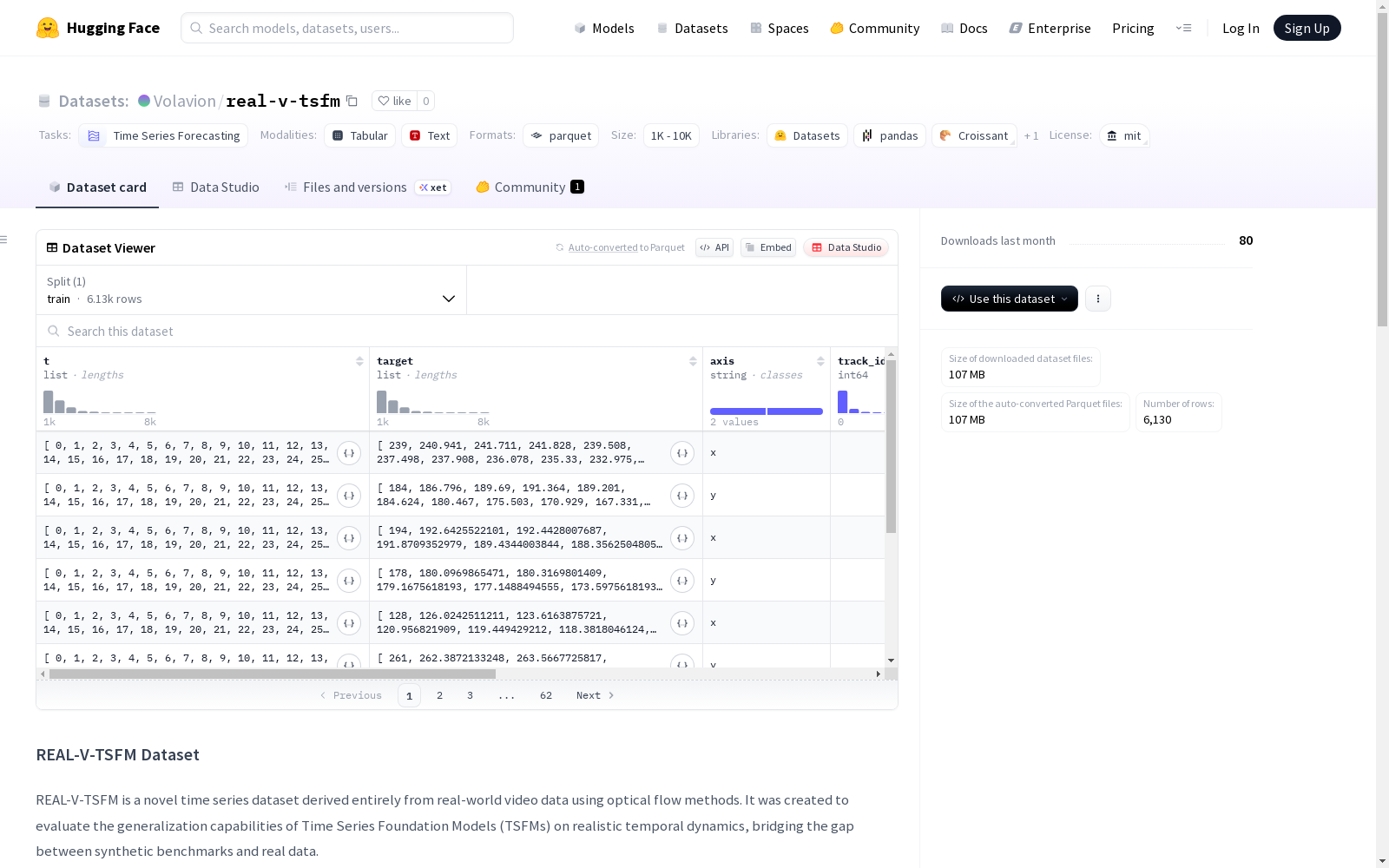
REAL-V-TSFM数据集是一个全新的时序数据集,完全从真实世界视频数据中使用光流方法衍生而来。它旨在评估时序基础模型在真实时序动态上的泛化能力,弥合了合成基准和真实数据之间的差距。数据集包含6130个时序,源自609个不同物体的轨迹,提供了大量的类别多样性。每个时序的平均长度为2043个时间步,长度在1000到8000个时间步之间变化。数据集大约有44%的序列是静止的,平均信息熵为3.88比特,表明了其复杂性和多样性。
创建时间:
2025-08-22
原始信息汇总
REAL-V-TSFM 数据集概述
数据集基本信息
- 名称:REAL-V-TSFM
- 来源:基于真实世界视频数据,主要源自LaSOT数据集
- 数据量:6,130个时间序列样本
- 数据大小:下载大小106.7MB,数据集大小200.8MB
- 许可证:MIT许可证
- 任务类别:时间序列预测
- 规模类别:1K<n<10K
数据特征
- 特征列:
- t:时间索引(int64列表)
- target:时间序列对应值(float64列表)
- axis:空间轴标识(x或y)
- track_id:光流跟踪标识符
- timestamp:时间戳字段
- prefix:源视频标识
- time_length:时间长度
- target_length:目标长度
- unique_id:唯一标识符
数据生成方法
使用Lucas-Kanade光流算法跟踪视频中检测到的关键点的像素轨迹,每个轨迹的x和y坐标形成独立的单变量时间序列。
数据处理流程
- 选择视频并提取逐帧图像
- 使用高斯混合模型2(MOG2)进行前景检测以屏蔽背景像素
- 使用Shi-Tomasi角点检测算法检测前景对象中的角点
- 使用金字塔Lucas-Kanade光流跨帧跟踪关键点,并应用前后一致性检查过滤不稳定轨迹
- 将轨迹插值到每个视频的最长序列长度,保留五个最不相关的轨迹以确保多样性并减少噪声
- 将每个轨迹的x和y坐标作为单独的时间序列存储在数据集中
数据集特点
- 来自609个不同对象的6,130个时间序列,提供显著的类别多样性
- 平均长度为2,043个时间步长,长度范围从1,000到8,000个时间步长
- 约44%的序列通过增强迪基-富勒检验显示为平稳序列
- 平均信息熵为3.88比特,表明复杂性和多样性
评估基准
- 在零样本预测设置下评估最先进的时间序列基础模型
- 使用指标:平均绝对百分比误差(MAPE)、对称MAPE(sMAPE)、聚合相对加权分位数损失(WQL)和聚合相对平均绝对尺度误差(MASE)
- 与M4数据集相比,在REAL-V-TSFM上表现出性能下降,表明当前模型对真实世界视频衍生时间序列的泛化能力有限
搜集汇总
数据集介绍
构建方式
在计算机视觉与时间序列分析的交叉领域,real-v-tsfm数据集通过先进的光流技术从真实视频中提取时序数据。其构建流程始于从LaSOT数据集中选取视频并逐帧提取图像,随后采用混合高斯模型进行前景检测以屏蔽背景像素。利用Shi-Tomasi角点检测算法在前景物体上识别关键点,并通过金字塔式Lucas-Kanade光流法跨帧追踪这些关键点,同时应用前向后向一致性检验筛选稳定轨迹。最终对轨迹进行插值以统一长度,并保留相关性最低的五条轨迹以确保数据多样性和降低噪声,每条轨迹的x和y坐标被分别存储为单变量时间序列。
特点
该数据集囊括6130条时间序列,源自609个不同对象的视频追踪数据,呈现出显著的类别多样性。序列平均长度达到2043个时间步,范围介于1000至8000之间,体现了真实场景下时间动态的复杂性。约44%的序列通过增强迪基-富勒检验被判定为平稳序列,平均信息熵为3.88比特,反映了数据内在的波动性和丰富的信息含量。这些特征共同构成了一个贴近现实世界复杂性的时序数据集合,为模型泛化能力评估提供了坚实基础。
使用方法
该数据集专为零样本预测任务设计,适用于评估时间序列基础模型在真实动态数据上的泛化性能。使用者可直接加载序列数据,其中t列表示时间索引,target列为对应数值,axis列标识空间轴方向(x或y)。评估时推荐采用平均绝对百分比误差、对称MAPE、加权分位数损失和平均绝对缩放误差等指标进行性能度量。数据中的timestamp字段为适配某些模型输入要求而设,虽无实际语义含义但能确保与主流框架兼容。通过对比在M4等合成数据集上的表现,可深入分析模型对真实视频衍生时序数据的适应能力。
背景与挑战
背景概述
REAL-V-TSFM数据集诞生于2023年,由时间序列分析领域的研究团队基于LaSOT视频数据集构建而成。该数据集通过Lucas-Kanade光流算法从真实视频中提取像素轨迹,生成6130条多元时间序列,涵盖609个不同对象的运动模式。其核心研究在于评估时间序列基础模型对真实世界动态模式的泛化能力,填补了合成数据基准与真实应用场景之间的鸿沟,为计算机视觉与时间序列预测的交叉研究提供了重要实验平台。
当前挑战
该数据集首要解决视频动态时间模式建模的挑战,包括非平稳性序列处理(44%序列具有平稳特性)、长程依赖捕捉(序列长度1000-8000步)以及跨对象泛化能力评估。构建过程中面临光流追踪稳定性控制、前景背景分离精度、关键点轨迹去噪等技术难点,需通过前向-后向一致性校验和高斯混合模型优化来保证数据质量。
常用场景
经典使用场景
在时间序列预测研究领域,REAL-V-TSFM数据集通过光学流技术从真实视频数据中提取像素轨迹,为评估时间序列基础模型的泛化能力提供了经典测试平台。该数据集包含6130条多元时间序列,涵盖人类和动物的复杂运动模式,研究者可基于其进行零样本预测评估,检验模型对真实世界动态变化的适应能力。
衍生相关工作
该数据集已衍生出多项重要研究工作,特别是在时间序列基础模型的跨域泛化评估方面。研究者通过对比M4等传统数据集的表现差异,揭示了现有模型在真实视频数据上的局限性,进而推动了针对复杂时空特征的模型改进方案,为新一代时间序列预测架构的设计提供了关键见解。
数据集最近研究
最新研究方向
在时间序列预测领域,REAL-V-TSFM数据集正推动光学流衍生时序数据的基础模型泛化能力研究。该数据集通过从真实视频中提取像素轨迹,构建了具有复杂时空动态特性的多元时间序列,为评估时序基础模型在真实场景中的适应性提供了重要基准。当前研究热点集中于模型在零样本预测任务中的表现差异分析,特别是在处理非平稳序列和高熵值数据时的局限性。这一方向不仅揭示了合成数据与真实数据之间的泛化鸿沟,更为计算机视觉与时间序列分析的跨学科融合提供了新的实验平台,对自动驾驶行为预测、人体运动分析等应用领域具有显著意义。
以上内容由遇见数据集搜集并总结生成


