unclean-web
收藏Hugging Face2026-05-20 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/ray0rf1re/unclean-web
下载链接
链接失效反馈官方服务:
资源简介:
Unclean Web是一个原始、未过滤的网络爬取数据集,专门为语言模型的预训练、微调和研究而设计。该数据集通过广度优先搜索(BFS)递归爬取自18个不同的网站来源,共包含4,210个网页,估计总token数约为559万。它提供了多种格式的子集,包括完整的原始抓取数据、不同规模的token抽样子集(如10K、1M、5M token)、用于指令微调的OpenHermes格式子集、用于预训练的Dolma/RedPajama格式子集,以及用于分词器训练的原始文本分片子集。每个数据样本包含25个详细的字段,涵盖URL信息(如原始URL、种子URL、爬取深度、时间戳)、页面元数据(如标题、描述、关键词、作者、语言、规范链接)、结构化语义信息(如Open Graph标签、Twitter卡片标签、Schema.org数据)、文本内容(清理后的正文文本和所有可见文本)、HTML源代码(上限12MB)、链接信息(内部和外部链接)、图像数据(以base64编码存储)、代码块以及可能的错误信息。该数据集适用于多种自然语言处理任务,包括文本生成、文本分类、特征提取、多模态学习、模型预训练、指令微调和分词器训练。需要注意的是,数据集内容为原始未过滤的网络数据,可能包含冒犯性、成人或敏感材料。
Unclean Web is a raw, unfiltered web-scraped dataset specifically designed for language model pretraining, fine-tuning, and research. The dataset was recursively crawled from 18 different website sources using breadth-first search (BFS), containing a total of 4,210 web pages with an estimated total token count of approximately 5.59 million. It provides various format subsets, including complete raw crawl data, token-sampled subsets of different scales (e.g., 10K, 1M, 5M tokens), an OpenHermes-format subset for instruction fine-tuning, a Dolma/RedPajama-format subset for pretraining, and a raw text chunk subset for tokenizer training. Each data sample includes 25 detailed fields covering URL information (such as original URL, seed URL, crawl depth, timestamp), page metadata (such as title, description, keywords, author, language, canonical link), structured semantic information (such as Open Graph tags, Twitter card tags, Schema.org data), text content (cleaned body text and all visible text), HTML source code (capped at 12MB), link information (internal and external links), image data (stored in base64 encoding), code blocks, and possible error messages. The dataset is suitable for various natural language processing tasks, including text generation, text classification, feature extraction, multimodal learning, model pretraining, instruction fine-tuning, and tokenizer training. It should be noted that the dataset contains raw, unfiltered web data and may include offensive, adult, or sensitive material.
创建时间:
2026-05-19
原始信息汇总
数据集概览
Unclean Web 是一个未经处理的原始网络抓取数据集,专为语言模型的预训练、微调及研究而设计。该数据集采用 CC0 1.0 许可证,主要语言为英语,适用于文本生成、文本分类和特征提取等任务。
数据规模与统计
| 指标 | 数量 |
|---|---|
| 总页面数 | 18,865 |
| 预估总Token数 | 24.35M |
| 唯一来源网站数 | 27 |
| 架构版本 | 3.0 |
| 最后更新 | 2026-05-21 04:40 UTC |
数据集划分与子集
该数据集提供了多种划分和子集,方便不同用途:
| 划分/子集 | 描述 | 格式 |
|---|---|---|
full (按批次) |
完整的原始抓取数据,包含所有列 | Parquet / JSONL |
subset_10k_tokens |
约10K Token的随机样本,用于快速测试 | Parquet / JSONL |
subset_1m_tokens |
约1M Token的精选样本 | Parquet / JSONL |
subset_5m_tokens |
约5M Token的精选样本 | Parquet / JSONL |
subset_half |
成功抓取页面的随机50% | Parquet / JSONL |
subset_openhermes |
OpenHermes 2.5/3 指令微调格式 | Parquet / JSONL |
subset_dolma |
Dolma / RedPajama / Fineweb 预训练格式 | Parquet / JSONL |
subset_tokenizer |
用于分词器训练的原始2048字符文本分片 | Parquet / JSONL |
merged (通过 merge_batches.py) |
所有批次划分合并为一个 | Parquet / JSONL |
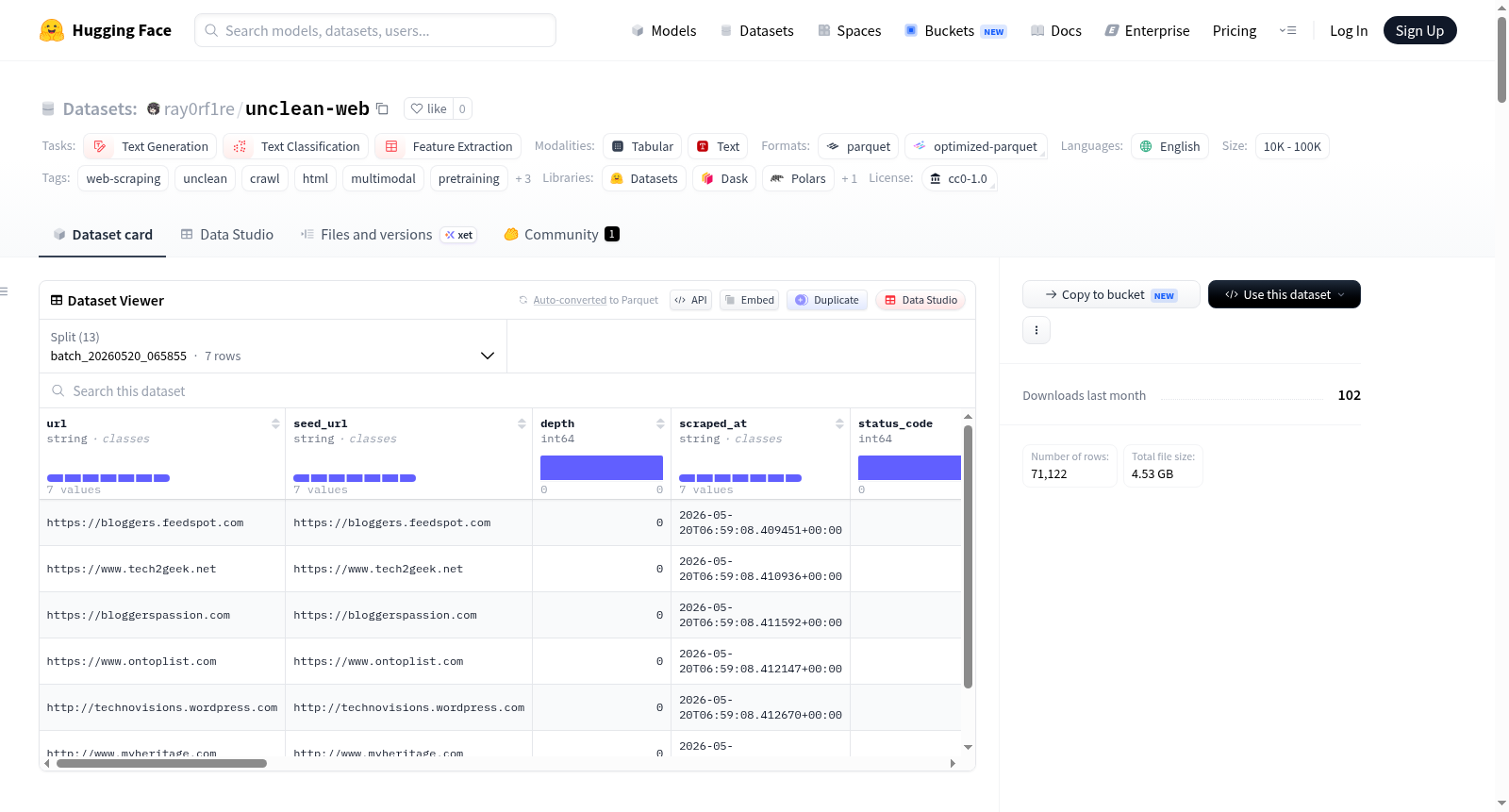
数据列架构
| 列名 | 类型 | 描述 |
|---|---|---|
url |
string |
抓取页面的绝对URL |
seed_url |
string |
本次抓取的起始根URL |
depth |
int64 |
BFS爬取深度(0表示种子页面本身) |
scraped_at |
string |
ISO-8601 UTC时间戳 |
status_code |
int64 |
HTTP响应状态码 |
title |
string |
<title> 标签文本 |
description |
string |
<meta name=description> 内容 |
keywords |
string |
<meta name=keywords> 内容 |
author |
string |
<meta name=author> 内容 |
lang |
string |
<html lang> 属性值 |
canonical |
string |
来自 <link rel=canonical> 的规范URL |
og_tags |
string |
Open Graph <meta property=og:*> 标签的JSON字典 |
twitter_tags |
string |
Twitter卡片 <meta name=twitter:*> 标签的JSON字典 |
schema_org |
string |
<script type=application/ld+json> 对象的JSON列表 |
text |
string |
干净的正文文本(已移除脚本和样式) |
text_all |
string |
包括导航、页脚等的所有可见文本 |
word_count |
int64 |
text 列的词数 |
token_estimate |
int64 |
近似Token数(词数 × 1.35) |
content_hash |
string |
text 列的SHA-256前缀,用于去重 |
structured |
string |
包含标题、段落、表格、列表、块引用的JSON |
html |
string |
原始HTML源代码(上限12 MB) |
links |
string |
内部 <a href> URL的JSON列表 |
external_links |
string |
外部 <a href> URL的JSON列表 |
images |
string |
图像对象(url, alt, base64数据等)的JSON列表 |
code_blocks |
string |
<code>/<pre>/<script>/<style> 块的JSON列表 |
error |
string? |
成功时为 null,失败时为错误字符串 |
数据来源
该数据集涵盖了27个不同的来源网站,包括但不限于:en.wikipedia.org、github.com、medium.com、archiveofourown.org、www.fandom.com、www.fanfiction.net、www.reddit.com、www.webtoons.com 等。
数据管道
该数据集由 scrape_to_hf.py Python管道生成,具备以下特性:
- 智能URL解析
- BFS递归爬取,可配置深度(1-25),仅限同源
- 每层级临时缓存,支持大规模爬取
- Token预算控制(
-M参数),达到目标时停止 - 自动站点发现(
-A参数),通过DuckDuckGo、Bing、Common Crawl发现网站 - 重试与退避,3次重试,指数退避,尊重robots.txt
- 多线程并行工作,实现更快的BFS爬取
- 自动生成7个标准子集
- 自更新README,每次上传都会重新生成
注意事项与免责声明
- 内容为原始未经筛选状态,可能包含攻击性、成人或敏感材料。
- 图像数据以 base64 格式存储在
imagesJSON列中(仅当未设置--no-images时)。 - 默认尊重 robots.txt,可通过
--ignore-robots覆盖。 - 每次上传运行会创建一个新的命名划分,数据会累积而非覆盖。
搜集汇总
数据集介绍
构建方式
Unclean Web 数据集通过一个名为 scrape_to_hf.py 的 Python 管道构建,该管道采用广度优先搜索策略,从 27 个广泛多样的网络源进行递归爬取,覆盖了包括博客、社区、百科、创作平台等在内的多元化站点。爬取过程遵循 robots.txt 规则,并支持智能 URL 解析、可配置的爬取深度(1–25 层)以及基于令牌数量的预算控制。每个深度层级会临时缓存至磁盘后释放,以避免内存溢出,同时借助多线程并行工作来提升效率。爬取结果自动生成 7 种标准子集,如面向预训练、指令微调和分词器训练的不同格式,且每次上传都会创建新的命名分割,实现数据的持续累积而不覆盖。
特点
该数据集的核心特质在于其原始未过滤性,直接保留了网络爬取的粗犷面貌,包含可能敏感或冒犯性的内容,为语言模型研究提供了真实且未经雕琢的样本。其丰富的列模式设计精妙,涵盖 URL、深度、状态码、各种元标签、结构化文本、原始 HTML、链接、图像及代码块等 25 个字段,并嵌入了 SHA-256 哈希前缀以支持去重,以及是否成功抓取的错误列。此外,数据集提供了从完整批次到特定令牌量样本的多种子集,并适配 OpenHermes 和 Dolma 等流行训练格式,兼具规模灵活性与领域适配性。
使用方法
使用者可通过 HuggingFace Datasets 库轻松加载 Unclean Web,例如直接调用 load_dataset('ray0rf1re/unclean-web', split='batch_20260101_120000') 来获取完整批次,或选择 subset_1m_tokens 等子集快速测试。对于大规模处理,支持以 streaming=True 模式流式加载合并后的整个数据集以节省内存。进一步地,用户可以解析结构化列中的 JSON 数据以提取标题、段落等元素,或遍历 images 列中的 base64 编码图像数据进行多模态应用。该数据集兼容文本生成、文本分类、特征提取等多种任务,适用于预训练、指令微调及分词器训练等场景。
背景与挑战
背景概述
大规模、高质量的网络文本数据是当前语言模型预训练与指令微调的核心驱动力。由独立研究者ray0rf1re于2026年创建的Unclean Web数据集,旨在提供一种未经精细过滤的原始互联网爬取资源,以填补现有清洗数据集(如FineWeb、Dolma)在保留网页原生多样性与噪声方面的空白。该数据集覆盖27个独特来源,包括维基百科、GitHub、Reddit、Archive of Our Own等,总计约1.8万页面、2400万Token,按广度优先策略爬取并附带丰富元数据(如结构标签、图像信息、代码块等),为语言模型预训练、分词器训练及多模态研究提供了贴近真实网络分布的训练样本。
当前挑战
Unclean Web数据集直面当前语言模型预训练中数据过度清洁化导致的泛化能力下降问题,通过保留拼写错误、导航文字、广告等真实网络噪声,促进模型对多样化输入鲁棒性的提升。构建过程中面临多重挑战:首先,爬取策略需在广度优先与Token预算之间平衡,通过临时缓存与并行工作器避免内存溢出;其次,需在每个上传批次中自动生成7种标准化子集(如OpenHermes、Dolma格式),兼顾研究灵活性与一致性;此外,图片以base64形式存储带来了存储与传输开销,而对robots.txt的默认遵守则限制了部分站点的覆盖深度。
常用场景
经典使用场景
在自然语言处理与大规模语言模型研究的浪潮中,raw web数据始终是预训练语料库的重要基石。Unclean Web数据集正是为了向研究者提供一份未经人工精心筛选、保留了互联网原始多样性的语料而构建。其经典使用场景聚焦于语言模型的预训练与持续预训练,研究者可直接利用其text或text_all字段构建大规模无监督语料,模拟模型在真实网络文本上的学习过程。此外,该数据集通过提供指定token规模的子集(如subset_1m_tokens与subset_5m_tokens),使得小规模预训练或领域适应实验成为可能。同时,其预设的subset_openhermes与subset_dolma格式,分别服务于指令微调与类RedPajama格式的标准化训练流程,极大简化了从原始抓取到模型训练的数据管线搭建。
实际应用
在实际应用层面,Unclean Web数据集为构建面向垂直领域的语言模型提供了丰富的原材料。例如,来自Archive of Our Own、FanFiction.net等创作平台的文本,可用于训练擅长理解叙事文风与粉丝文化语境的生成模型;来自GitHub与itch.io的页面则有助于强化代码理解与软件文档处理能力。此外,该数据集中的图像与base64编码数据为多模态模型的训练提供了潜在资源。其预设的tokenizer训练子集,将原始文本分割为2048字符的片段,可直接用于训练字节对编码(BPE)分词器,这对于需要自定义词表以适配特定领域或语言的研发团队而言是极大的便利。借助该数据集,开发者可以快速构建针对特定网站风格或内容类型的对话系统、摘要生成工具与内容推荐引擎。
衍生相关工作
Unclean Web数据集的设计理念与实现管线催生了一系列衍生研究方向与工具。首先,其配套的scrape_to_hf.py脚本本身即构成一个可复用的网络爬取数据处理框架,研究者可在此基础上扩展出面向特定站点或语言的数据采集工具。其次,该数据集提供的多格式子集(如Dolma格式)为数据规范化与数据集间迁移学习的研究提供了基准。其与OpenHermes格式的兼容性,使得基于指令微调的工作能够直接与这一未经清洗的语料进行对比实验。此外,针对该数据集中代码块与结构化内容的分离处理,启发了一系列关于混合代码与自然语言语料处理方法的研究。从更宏观的视角看,Unclean Web的出现推动了关于'数据污染'、'数据多样性'以及'最低过滤原则'在预训练数据构成中重要性的学术讨论,进而衍生出多个后续致力于可控数据质量过滤的工作。
以上内容由遇见数据集搜集并总结生成


