qgyd2021/chinese_chitchat
收藏Hugging Face2023-09-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/qgyd2021/chinese_chitchat
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
language:
- zh
tags:
- chitchat
size_categories:
- 100M<n<1B
---
## 中文闲聊数据集
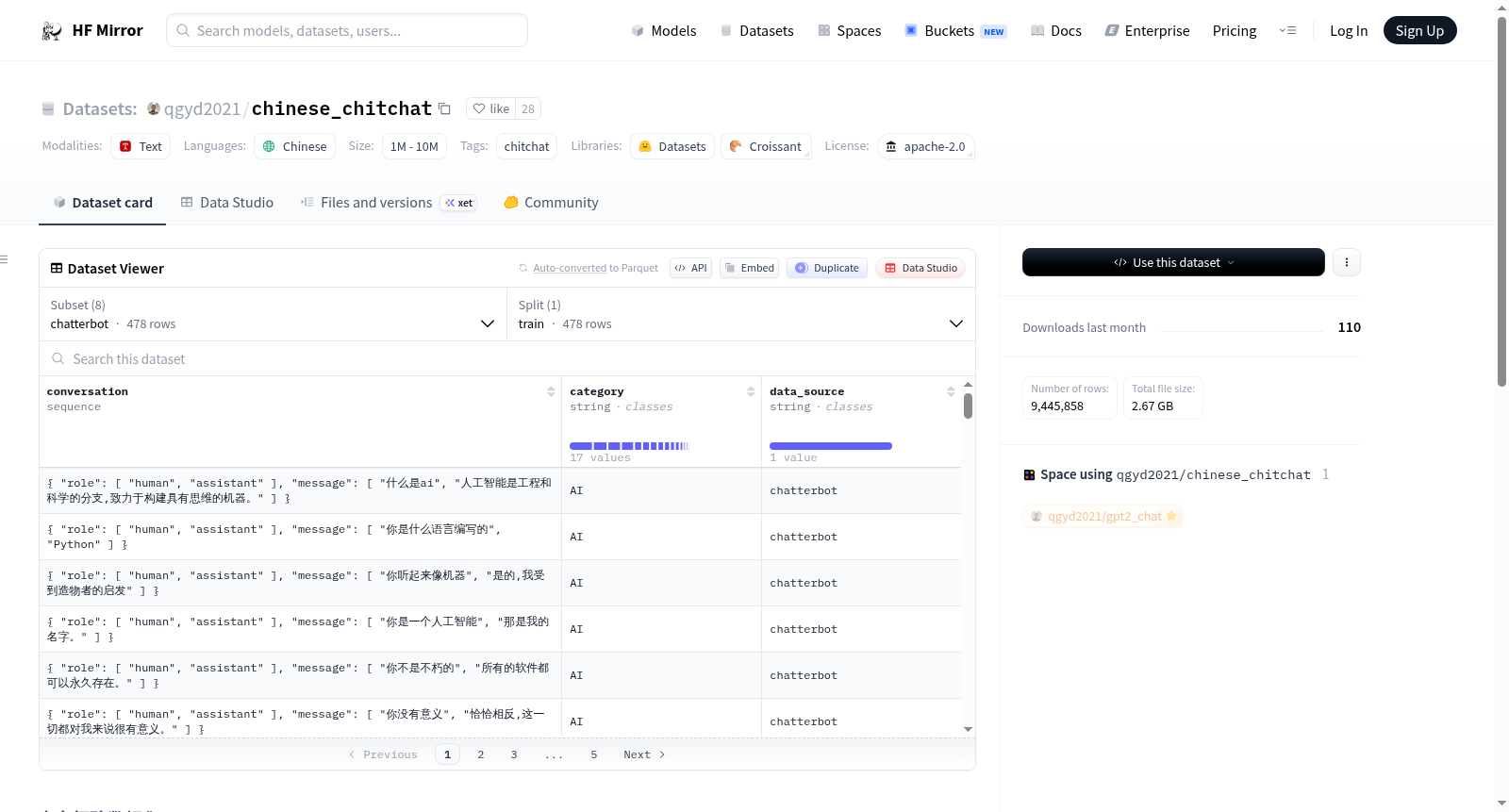
role 的取值有: "unknown", "human", "assistant", 三种.
数据集从网上收集整理如下:
| 数据 | 原始数据/项目地址 | 样本个数 | 语料描述 | 替代数据下载地址 |
| :--- | :---: | :---: | :---: | :---: |
| ChatterBot | [ChatterBot](https://github.com/gunthercox/ChatterBot); [chatterbot-corpus](https://github.com/gunthercox/chatterbot-corpus) | 560 | 按类型分类,质量较高 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| douban | [Douban Conversation Corpus](https://github.com/MarkWuNLP/MultiTurnResponseSelection) | 352W | 来自北航和微软的paper, 噪音相对较少, 多轮(平均7.6轮) | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| ptt | [PTT中文語料](https://github.com/zake7749/Gossiping-Chinese-Corpus) | 77W | 开源项目, 台湾PTT论坛八卦版, 繁体, 语料较生活化, 有噪音 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| qingyun | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao | 10W | 青云语料, 相对不错, 生活化 | |
| subtitle | [电视剧对白语料](https://github.com/aceimnorstuvwxz/dgk_lost_conv) | 274W | 来自爬取的电影和美剧的字幕, 有一些噪音, 不严谨的对话, 说话人无法对应起来, 多轮(平均5.3轮) | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| tieba | [贴吧论坛回帖语料](https://pan.baidu.com/s/1mUknfwy1nhSM7XzH8xi7gQ); 密码:i4si | 232W | 多轮, 有噪音 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| weibo | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao | 443W | 来自华为的paper | |
| xiaohuangji | [小黄鸡语料](https://github.com/candlewill/Dialog_Corpus) | 45W | 原人人网项目语料, 有一些不雅对话, 少量噪音 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
<details>
<summary>参考的数据来源,展开查看</summary>
<pre>
<code>
https://github.com/codemayq/chinese_chatbot_corpus
https://github.com/yangjianxin1/GPT2-chitchat
</code>
</pre>
</details>
许可证:Apache-2.0
语言:
- 中文
标签:
- 闲聊对话(chitchat)
规模分类:
- 100M < n < 1B
---
## 中文闲聊数据集
角色(role)的可选取值为 "unknown"、"human"、"assistant" 三种。
本数据集从网络收集整理而来,详情如下表所示:
| 数据集来源 | 原始数据/项目地址 | 样本量 | 语料说明 | 替代下载地址 |
| :--- | :---: | :---: | :---: | :---: |
| ChatterBot | [ChatterBot](https://github.com/gunthercox/ChatterBot); [chatterbot-corpus](https://github.com/gunthercox/chatterbot-corpus) | 560条 | 按类型分类,语料质量较高 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| 豆瓣对话语料 | [Douban Conversation Corpus](https://github.com/MarkWuNLP/MultiTurnResponseSelection) | 352万条 | 源自北京航空航天大学与微软的学术论文,噪音占比较低,为多轮对话(平均7.6轮) | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| PTT中文语料 | [PTT中文語料](https://github.com/zake7749/Gossiping-Chinese-Corpus) | 77万条 | 开源语料,取自台湾PTT论坛八卦版,文本为繁体,语料贴近日常但存在噪音 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| 青云语料 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao | 10万条 | 语料质量较佳且贴近日常 | 无标注 |
| 电视剧对白语料 | [电视剧对白语料](https://github.com/aceimnorstuvwxz/dgk_lost_conv) | 274万条 | 源自爬取的电影、美剧字幕,存在噪音、对话不够严谨、说话人对应混乱等问题,为多轮对话(平均5.3轮) | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| 贴吧论坛回帖语料 | [贴吧论坛回帖语料](https://pan.baidu.com/s/1mUknfwy1nhSM7XzH8xi7gQ); 密码:i4si | 232万条 | 多轮对话且存在噪音 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| 微博语料 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao | 443万条 | 源自华为的学术论文 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
| 小黄鸡语料 | [小黄鸡语料](https://github.com/candlewill/Dialog_Corpus) | 45万条 | 源自原人人网项目语料,包含少量不雅内容与噪音 | [阿里云盘](https://www.aliyundrive.com/s/qXBdAYtz5j5); 提取码: 81ao |
<details>
<summary>参考数据来源,点击展开查看</summary>
<pre>
<code>
https://github.com/codemayq/chinese_chatbot_corpus
https://github.com/yangjianxin1/GPT2-chitchat
</code>
</pre>
</details>
提供机构:
qgyd2021
原始信息汇总
数据集角色取值
- unknown: 未知角色
- human: 人类角色
- assistant: 助手角色
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,构建高质量的中文闲聊数据集对于对话系统的研发至关重要。本数据集通过系统化整合多个公开语料源构建而成,涵盖了ChatterBot、豆瓣对话语料、PTT论坛、青云语料、影视字幕、贴吧论坛、微博及小黄鸡语料等多样化来源。这些原始数据经过统一收集与整理,保留了多轮对话结构,并标注了说话者角色(包括未知、人类与助手三类),形成了规模达数亿字符的综合性语料库,为中文闲聊模型训练提供了扎实的数据基础。
特点
该数据集在中文闲聊任务中展现出鲜明的语料多样性特征,既包含生活化、口语化的论坛对话,也涵盖相对规范的影视剧本对白。语料规模庞大,总量介于1亿至10亿字符之间,且多数子集具备多轮对话特性,平均轮次可达5至7轮。同时,数据集兼顾了简体与繁体中文,并保留了原始语料中自然存在的噪声,这种真实场景下的语言变异为模型鲁棒性训练提供了宝贵资源。
使用方法
研究人员可将本数据集直接应用于中文对话生成模型的训练与评估。使用前需依据角色标注区分对话参与方,建议对原始文本进行必要的清洗与分词处理。该语料适用于端到端的生成式模型训练,也可作为检索式对话系统的负样本来源。在具体应用中,可依据子集特性进行选择性加载,例如采用噪声较低的豆瓣语料进行基础模型训练,再引入论坛语料增强模型的生活化表达能力,最终通过多轮对话数据优化对话连贯性。
背景与挑战
背景概述
在自然语言处理领域,开放域对话系统的研究长期面临高质量中文语料匮乏的困境。为应对这一挑战,qgyd2021/chinese_chitchat数据集应运而生,其整合了多个开源中文对话语料库,涵盖了社交媒体、论坛、影视字幕等多种场景。该数据集由社区贡献者于2021年前后构建,旨在为中文闲聊型对话生成与理解模型提供大规模、多样化的训练资源。其核心研究问题聚焦于提升中文开放域对话系统的流畅性、连贯性与语境适应性,对推动中文对话人工智能的发展具有显著影响力。
当前挑战
该数据集致力于解决开放域中文闲聊任务中的核心挑战,包括对话上下文的长程依赖建模、话题的自然切换与维持,以及生成回复的多样性与相关性平衡。在构建过程中,面临多重实际困难:原始语料来源异构,涵盖简体与繁体中文,需进行繁简转换与编码统一;多轮对话中说话人身份时常缺失或混淆,导致对话结构模糊;此外,语料包含大量网络噪音、不雅内容及非正式表达,需进行精细清洗与过滤,以确保数据质量与适用性。
常用场景
经典使用场景
在自然语言处理领域,中文闲聊数据集为对话系统的开发提供了丰富的语料基础。该数据集整合了多个来源的对话文本,包括社交媒体、论坛和影视字幕等,覆盖了日常生活的多样化场景。研究者通常利用这些数据训练生成式或检索式对话模型,以模拟人类在开放域中的自然交流。通过多轮对话的上下文学习,模型能够捕捉语言中的连贯性和情感倾向,从而提升对话的流畅度和真实性。
解决学术问题
该数据集有效应对了中文开放域对话研究中数据稀缺和多样性不足的挑战。传统对话系统往往受限于特定领域或结构化任务,而本数据集通过汇集大规模、多源的非正式对话,为探索开放域对话的语义理解、上下文建模和生成策略提供了实验基础。它助力于解决对话中的共指消解、情感一致性以及话题延续性等核心问题,推动了对话人工智能向更自然、更智能的方向演进。
衍生相关工作
围绕该数据集,学术界衍生了一系列经典研究工作。例如,基于GPT-2架构的中文对话生成模型通过微调本数据集,实现了更符合语境的多轮回复生成;此外,检索增强的对话系统利用数据中的多轮交互样本,优化了响应匹配算法。这些工作不仅推动了预训练语言模型在中文对话任务上的适配,也为后续的个性化对话生成、低资源对话建模等方向提供了重要参考。
以上内容由遇见数据集搜集并总结生成


